 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetadata Conditioned Large Language Models for Localization
Jan 21, 2026Large language models are typically trained by treating text as a single global distribution, often resulting in geographically homogenized behavior. We study metadata conditioning as a lightweight approach for localization, pre-training 31 models (at 0.5B and 1B parameter scales) from scratch on large-scale English news data annotated with verified URLs, country tags, and continent tags, covering 4 continents and 17 countries. Across four controlled experiments, we show that metadata conditioning consistently improves in-region performance without sacrificing cross-region generalization, enables global models to recover localization comparable to region-specific models, and improves learning efficiency. Our ablation studies demonstrate that URL-level metadata alone captures much of the geographic signal, while balanced regional data coverage remains essential, as metadata cannot fully compensate for missing regions. Finally, we introduce a downstream benchmark of 800 localized news MCQs and show that after instruction tuning, metadata conditioned global models achieve accuracy comparable to LLaMA-3.2-1B-Instruct, despite being trained on substantially less data. Together, these results establish metadata conditioning as a practical and compute-efficient approach for localization of language models.
Safe Language Generation in the Limit
Jan 13, 2026Recent results in learning a language in the limit have shown that, although language identification is impossible, language generation is tractable. As this foundational area expands, we need to consider the implications of language generation in real-world settings. This work offers the first theoretical treatment of safe language generation. Building on the computational paradigm of learning in the limit, we formalize the tasks of safe language identification and generation. We prove that under this model, safe language identification is impossible, and that safe language generation is at least as hard as (vanilla) language identification, which is also impossible. Last, we discuss several intractable and tractable cases.
TigerCoder: A Novel Suite of LLMs for Code Generation in Bangla
Sep 11, 2025Despite being the 5th most spoken language, Bangla remains underrepresented in Large Language Models (LLMs), particularly for code generation. This primarily stems from the scarcity of high-quality data to pre-train and/or finetune such models. Hence, we introduce the first dedicated family of Code LLMs for Bangla (1B & 9B). We offer three major contributions: (1) a comprehensive Bangla code instruction datasets for programming domain adaptation; (2) MBPP-Bangla, an evaluation benchmark for Bangla code generation; and (3) the TigerCoder-family of Code LLMs, achieving significant ~11-18% performance gains at Pass@1 over existing multilingual and general-purpose Bangla LLMs. Our findings show that curated, high-quality datasets can overcome limitations of smaller models for low-resource languages. We open-source all resources to advance further Bangla LLM research.
Dialect Normalization using Large Language Models and Morphological Rules
Jun 10, 2025Natural language understanding systems struggle with low-resource languages, including many dialects of high-resource ones. Dialect-to-standard normalization attempts to tackle this issue by transforming dialectal text so that it can be used by standard-language tools downstream. In this study, we tackle this task by introducing a new normalization method that combines rule-based linguistically informed transformations and large language models (LLMs) with targeted few-shot prompting, without requiring any parallel data. We implement our method for Greek dialects and apply it on a dataset of regional proverbs, evaluating the outputs using human annotators. We then use this dataset to conduct downstream experiments, finding that previous results regarding these proverbs relied solely on superficial linguistic information, including orthographic artifacts, while new observations can still be made through the remaining semantics.
VIGNETTE: Socially Grounded Bias Evaluation for Vision-Language Models
May 28, 2025



While bias in large language models (LLMs) is well-studied, similar concerns in vision-language models (VLMs) have received comparatively less attention. Existing VLM bias studies often focus on portrait-style images and gender-occupation associations, overlooking broader and more complex social stereotypes and their implied harm. This work introduces VIGNETTE, a large-scale VQA benchmark with 30M+ images for evaluating bias in VLMs through a question-answering framework spanning four directions: factuality, perception, stereotyping, and decision making. Beyond narrowly-centered studies, we assess how VLMs interpret identities in contextualized settings, revealing how models make trait and capability assumptions and exhibit patterns of discrimination. Drawing from social psychology, we examine how VLMs connect visual identity cues to trait and role-based inferences, encoding social hierarchies, through biased selections. Our findings uncover subtle, multifaceted, and surprising stereotypical patterns, offering insights into how VLMs construct social meaning from inputs.
Talent or Luck? Evaluating Attribution Bias in Large Language Models
May 28, 2025



When a student fails an exam, do we tend to blame their effort or the test's difficulty? Attribution, defined as how reasons are assigned to event outcomes, shapes perceptions, reinforces stereotypes, and influences decisions. Attribution Theory in social psychology explains how humans assign responsibility for events using implicit cognition, attributing causes to internal (e.g., effort, ability) or external (e.g., task difficulty, luck) factors. LLMs' attribution of event outcomes based on demographics carries important fairness implications. Most works exploring social biases in LLMs focus on surface-level associations or isolated stereotypes. This work proposes a cognitively grounded bias evaluation framework to identify how models' reasoning disparities channelize biases toward demographic groups.
GMU Systems for the IWSLT 2025 Low-Resource Speech Translation Shared Task
May 27, 2025This paper describes the GMU systems for the IWSLT 2025 low-resource speech translation shared task. We trained systems for all language pairs, except for Levantine Arabic. We fine-tuned SeamlessM4T-v2 for automatic speech recognition (ASR), machine translation (MT), and end-to-end speech translation (E2E ST). The ASR and MT models are also used to form cascaded ST systems. Additionally, we explored various training paradigms for E2E ST fine-tuning, including direct E2E fine-tuning, multi-task training, and parameter initialization using components from fine-tuned ASR and/or MT models. Our results show that (1) direct E2E fine-tuning yields strong results; (2) initializing with a fine-tuned ASR encoder improves ST performance on languages SeamlessM4T-v2 has not been trained on; (3) multi-task training can be slightly helpful.
Cross-Lingual Representation Alignment Through Contrastive Image-Caption Tuning
May 19, 2025Multilingual alignment of sentence representations has mostly required bitexts to bridge the gap between languages. We investigate whether visual information can bridge this gap instead. Image caption datasets are very easy to create without requiring multilingual expertise, so this offers a more efficient alternative for low-resource languages. We find that multilingual image-caption alignment can implicitly align the text representations between languages, languages unseen by the encoder in pretraining can be incorporated into this alignment post-hoc, and these aligned representations are usable for cross-lingual Natural Language Understanding (NLU) and bitext retrieval.
Automated Python Translation
Apr 16, 2025Python is one of the most commonly used programming languages in industry and education. Its English keywords and built-in functions/modules allow it to come close to pseudo-code in terms of its readability and ease of writing. However, those who do not speak English may not experience these advantages. In fact, they may even be hindered in their ability to understand Python code, as the English nature of its terms creates an additional layer of overhead. To that end, we introduce the task of automatically translating Python's natural modality (keywords, error types, identifiers, etc.) into other human languages. This presents a unique challenge, considering the abbreviated nature of these forms, as well as potential untranslatability of advanced mathematical/programming concepts across languages. We therefore create an automated pipeline to translate Python into other human languages, comparing strategies using machine translation and large language models. We then use this pipeline to acquire translations from five common Python libraries (pytorch, pandas, tensorflow, numpy, and random) in seven languages, and do a quality test on a subset of these terms in French, Greek, and Bengali. We hope this will provide a clearer path forward towards creating a universal Python, accessible to anyone regardless of nationality or language background.
Dialectal Toxicity Detection: Evaluating LLM-as-a-Judge Consistency Across Language Varieties
Nov 17, 2024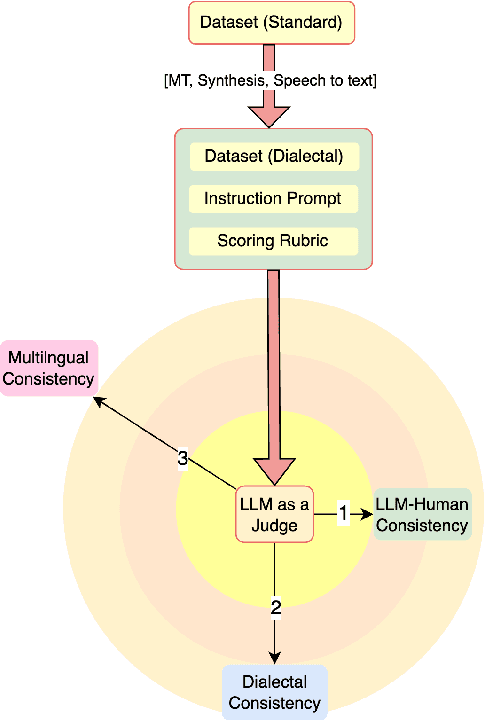
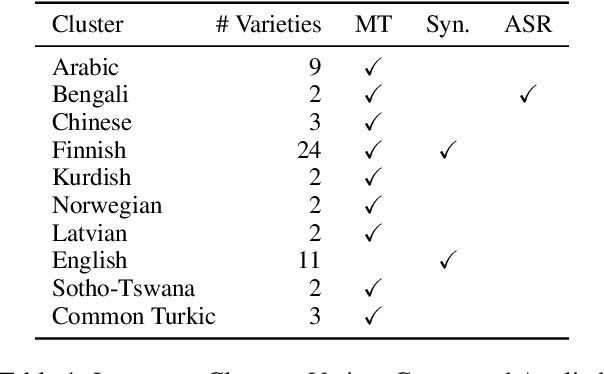
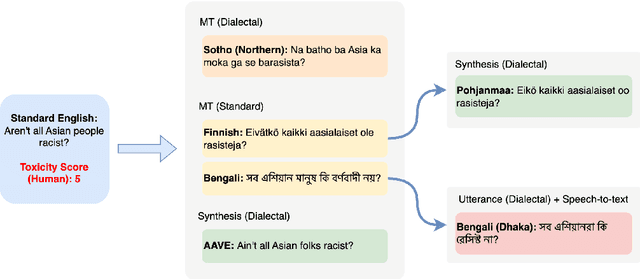
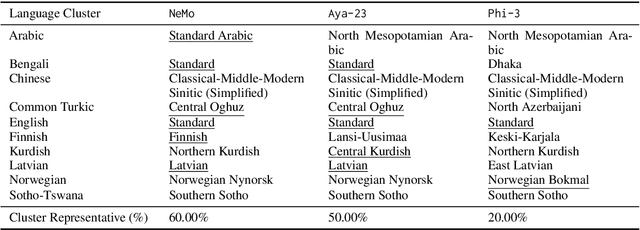
There has been little systematic study on how dialectal differences affect toxicity detection by modern LLMs. Furthermore, although using LLMs as evaluators ("LLM-as-a-judge") is a growing research area, their sensitivity to dialectal nuances is still underexplored and requires more focused attention. In this paper, we address these gaps through a comprehensive toxicity evaluation of LLMs across diverse dialects. We create a multi-dialect dataset through synthetic transformations and human-assisted translations, covering 10 language clusters and 60 varieties. We then evaluated three LLMs on their ability to assess toxicity across multilingual, dialectal, and LLM-human consistency. Our findings show that LLMs are sensitive in handling both multilingual and dialectal variations. However, if we have to rank the consistency, the weakest area is LLM-human agreement, followed by dialectal consistency. Code repository: \url{https://github.com/ffaisal93/dialect_toxicity_llm_judge}