 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDialectal Toxicity Detection: Evaluating LLM-as-a-Judge Consistency Across Language Varieties
Paper and Code
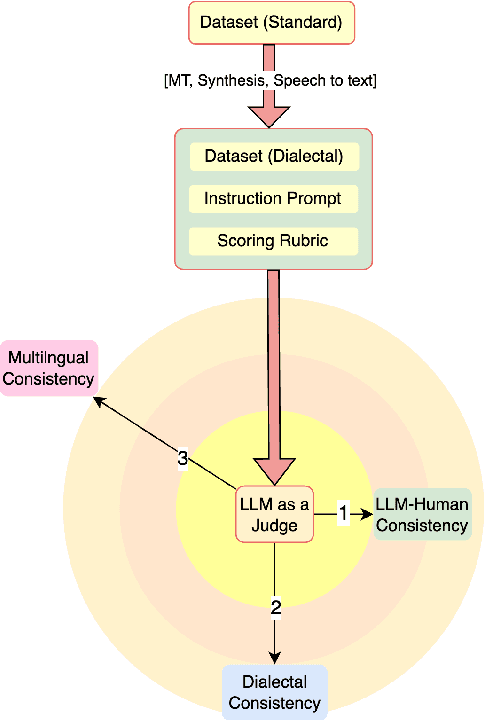
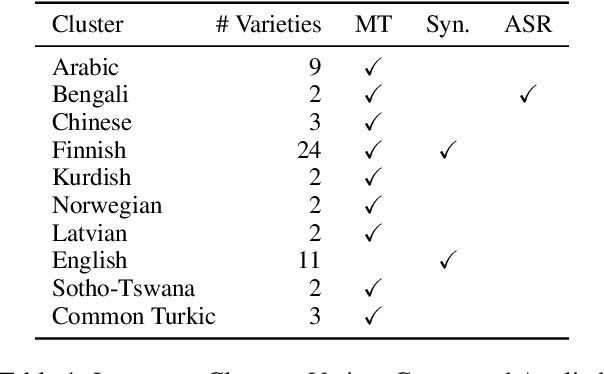
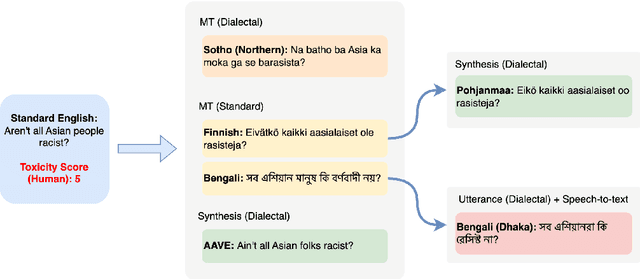
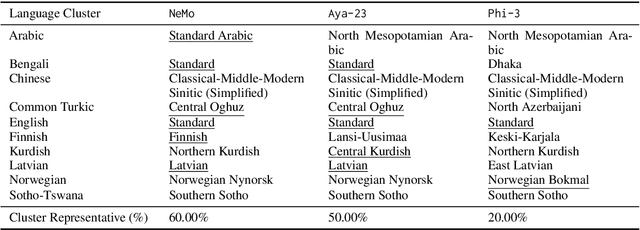
There has been little systematic study on how dialectal differences affect toxicity detection by modern LLMs. Furthermore, although using LLMs as evaluators ("LLM-as-a-judge") is a growing research area, their sensitivity to dialectal nuances is still underexplored and requires more focused attention. In this paper, we address these gaps through a comprehensive toxicity evaluation of LLMs across diverse dialects. We create a multi-dialect dataset through synthetic transformations and human-assisted translations, covering 10 language clusters and 60 varieties. We then evaluated three LLMs on their ability to assess toxicity across multilingual, dialectal, and LLM-human consistency. Our findings show that LLMs are sensitive in handling both multilingual and dialectal variations. However, if we have to rank the consistency, the weakest area is LLM-human agreement, followed by dialectal consistency. Code repository: \url{https://github.com/ffaisal93/dialect_toxicity_llm_judge}