 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIDIOLEX: Unified and Continuous Representations for Idiolectal and Stylistic Variation
Apr 06, 2026Existing sentence representations primarily encode what a sentence says, rather than how it is expressed, even though the latter is important for many applications. In contrast, we develop sentence representations that capture style and dialect, decoupled from semantic content. We call this the task of idiolectal representation learning. We introduce IDIOLEX, a framework for training models that combines supervision from a sentence's provenance with linguistic features of a sentence's content, to learn a continuous representation of each sentence's style and dialect. We evaluate the approach on dialects of both Arabic and Spanish. The learned representations capture meaningful variation and transfer across domains for analysis and classification. We further explore the use of these representations as training objectives for stylistically aligning language models. Our results suggest that jointly modeling individual and community-level variation provides a useful perspective for studying idiolect and supports downstream applications requiring sensitivity to stylistic differences, such as developing diverse and accessible LLMs.
Dialectal Toxicity Detection: Evaluating LLM-as-a-Judge Consistency Across Language Varieties
Nov 17, 2024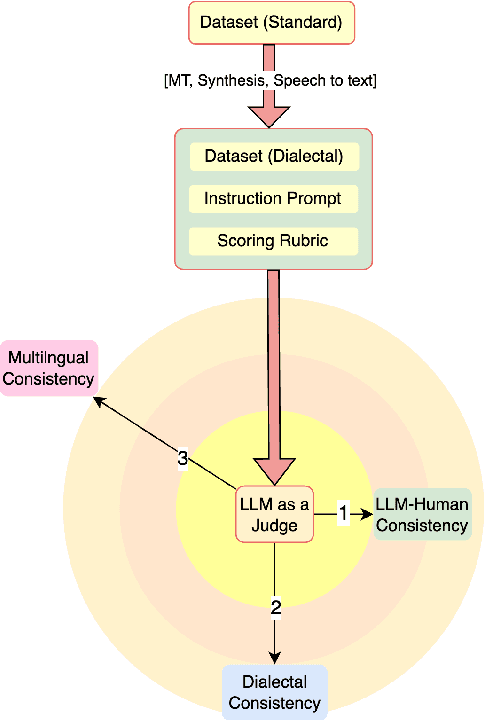
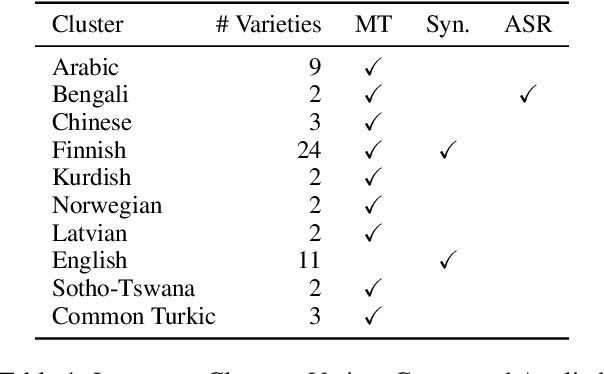
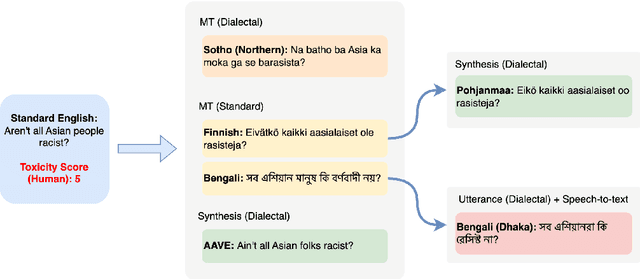
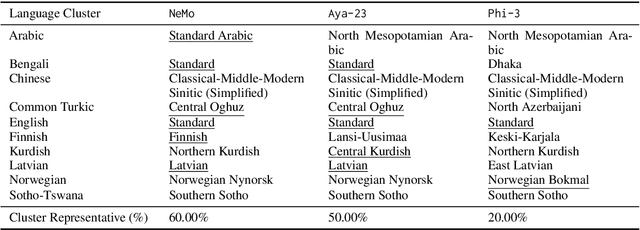
There has been little systematic study on how dialectal differences affect toxicity detection by modern LLMs. Furthermore, although using LLMs as evaluators ("LLM-as-a-judge") is a growing research area, their sensitivity to dialectal nuances is still underexplored and requires more focused attention. In this paper, we address these gaps through a comprehensive toxicity evaluation of LLMs across diverse dialects. We create a multi-dialect dataset through synthetic transformations and human-assisted translations, covering 10 language clusters and 60 varieties. We then evaluated three LLMs on their ability to assess toxicity across multilingual, dialectal, and LLM-human consistency. Our findings show that LLMs are sensitive in handling both multilingual and dialectal variations. However, if we have to rank the consistency, the weakest area is LLM-human agreement, followed by dialectal consistency. Code repository: \url{https://github.com/ffaisal93/dialect_toxicity_llm_judge}
Data-Augmentation-Based Dialectal Adaptation for LLMs
Apr 11, 2024



This report presents GMUNLP's participation to the Dialect-Copa shared task at VarDial 2024, which focuses on evaluating the commonsense reasoning capabilities of large language models (LLMs) on South Slavic micro-dialects. The task aims to assess how well LLMs can handle non-standard dialectal varieties, as their performance on standard languages is already well-established. We propose an approach that combines the strengths of different types of language models and leverages data augmentation techniques to improve task performance on three South Slavic dialects: Chakavian, Cherkano, and Torlak. We conduct experiments using a language-family-focused encoder-based model (BERTi\'c) and a domain-agnostic multilingual model (AYA-101). Our results demonstrate that the proposed data augmentation techniques lead to substantial performance gains across all three test datasets in the open-source model category. This work highlights the practical utility of data augmentation and the potential of LLMs in handling non-standard dialectal varieties, contributing to the broader goal of advancing natural language understanding in low-resource and dialectal settings. Code:https://github.com/ffaisal93/dialect_copa
An Efficient Approach for Studying Cross-Lingual Transfer in Multilingual Language Models
Mar 29, 2024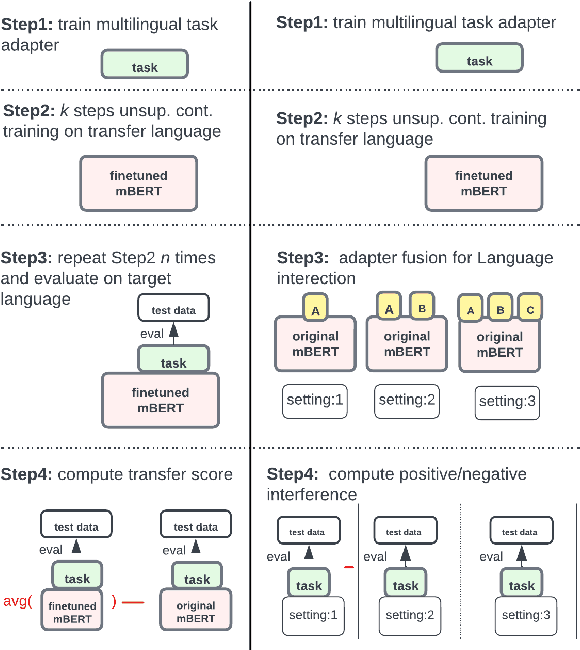

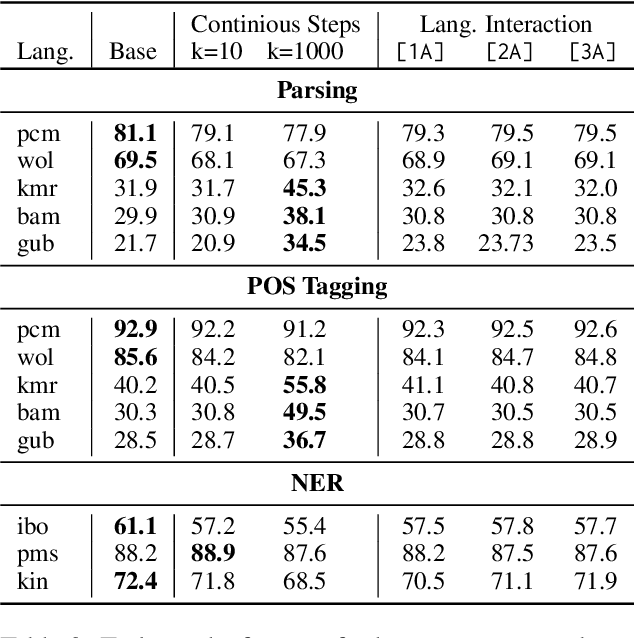
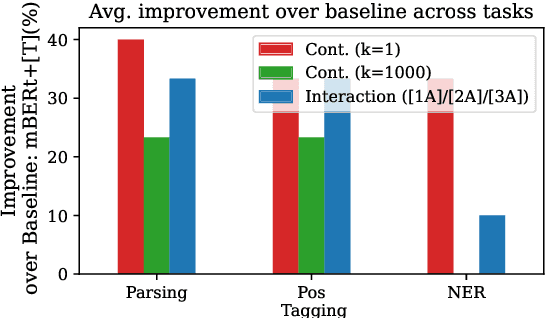
The capacity and effectiveness of pre-trained multilingual models (MLMs) for zero-shot cross-lingual transfer is well established. However, phenomena of positive or negative transfer, and the effect of language choice still need to be fully understood, especially in the complex setting of massively multilingual LMs. We propose an \textit{efficient} method to study transfer language influence in zero-shot performance on another target language. Unlike previous work, our approach disentangles downstream tasks from language, using dedicated adapter units. Our findings suggest that some languages do not largely affect others, while some languages, especially ones unseen during pre-training, can be extremely beneficial or detrimental for different target languages. We find that no transfer language is beneficial for all target languages. We do, curiously, observe languages previously unseen by MLMs consistently benefit from transfer from almost any language. We additionally use our modular approach to quantify negative interference efficiently and categorize languages accordingly. Furthermore, we provide a list of promising transfer-target language configurations that consistently lead to target language performance improvements. Code and data are publicly available: https://github.com/ffaisal93/neg_inf
DIALECTBENCH: A NLP Benchmark for Dialects, Varieties, and Closely-Related Languages
Mar 16, 2024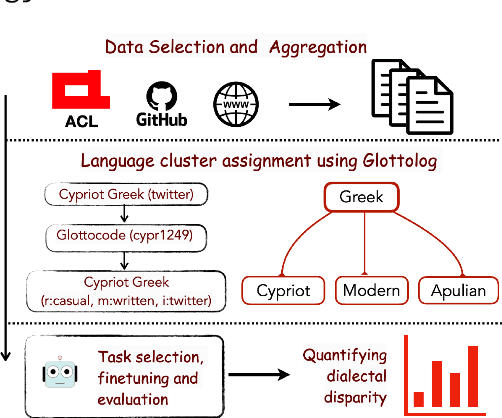
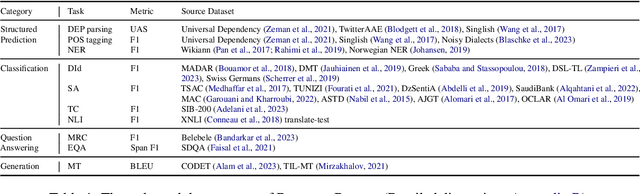
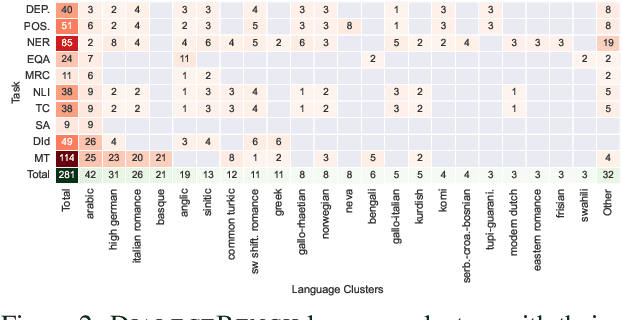

Language technologies should be judged on their usefulness in real-world use cases. An often overlooked aspect in natural language processing (NLP) research and evaluation is language variation in the form of non-standard dialects or language varieties (hereafter, varieties). Most NLP benchmarks are limited to standard language varieties. To fill this gap, we propose DIALECTBENCH, the first-ever large-scale benchmark for NLP on varieties, which aggregates an extensive set of task-varied variety datasets (10 text-level tasks covering 281 varieties). This allows for a comprehensive evaluation of NLP system performance on different language varieties. We provide substantial evidence of performance disparities between standard and non-standard language varieties, and we also identify language clusters with large performance divergence across tasks. We believe DIALECTBENCH provides a comprehensive view of the current state of NLP for language varieties and one step towards advancing it further. Code/data: https://github.com/ffaisal93/DialectBench
To token or not to token: A Comparative Study of Text Representations for Cross-Lingual Transfer
Oct 12, 2023



Choosing an appropriate tokenization scheme is often a bottleneck in low-resource cross-lingual transfer. To understand the downstream implications of text representation choices, we perform a comparative analysis on language models having diverse text representation modalities including 2 segmentation-based models (\texttt{BERT}, \texttt{mBERT}), 1 image-based model (\texttt{PIXEL}), and 1 character-level model (\texttt{CANINE}). First, we propose a scoring Language Quotient (LQ) metric capable of providing a weighted representation of both zero-shot and few-shot evaluation combined. Utilizing this metric, we perform experiments comprising 19 source languages and 133 target languages on three tasks (POS tagging, Dependency parsing, and NER). Our analysis reveals that image-based models excel in cross-lingual transfer when languages are closely related and share visually similar scripts. However, for tasks biased toward word meaning (POS, NER), segmentation-based models prove to be superior. Furthermore, in dependency parsing tasks where word relationships play a crucial role, models with their character-level focus, outperform others. Finally, we propose a recommendation scheme based on our findings to guide model selection according to task and language requirements.
Multilingual Text Representation
Sep 02, 2023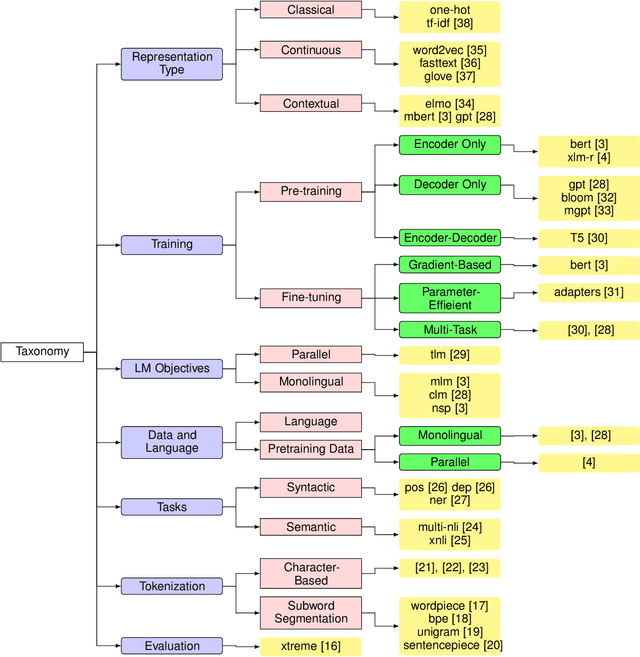
Modern NLP breakthrough includes large multilingual models capable of performing tasks across more than 100 languages. State-of-the-art language models came a long way, starting from the simple one-hot representation of words capable of performing tasks like natural language understanding, common-sense reasoning, or question-answering, thus capturing both the syntax and semantics of texts. At the same time, language models are expanding beyond our known language boundary, even competitively performing over very low-resource dialects of endangered languages. However, there are still problems to solve to ensure an equitable representation of texts through a unified modeling space across language and speakers. In this survey, we shed light on this iterative progression of multilingual text representation and discuss the driving factors that ultimately led to the current state-of-the-art. Subsequently, we discuss how the full potential of language democratization could be obtained, reaching beyond the known limits and what is the scope of improvement in that space.
Investigation on Machine Learning Based Approaches for Estimating the Critical Temperature of Superconductors
Aug 02, 2023



Superconductors have been among the most fascinating substances, as the fundamental concept of superconductivity as well as the correlation of critical temperature and superconductive materials have been the focus of extensive investigation since their discovery. However, superconductors at normal temperatures have yet to be identified. Additionally, there are still many unknown factors and gaps of understanding regarding this unique phenomenon, particularly the connection between superconductivity and the fundamental criteria to estimate the critical temperature. To bridge the gap, numerous machine learning techniques have been established to estimate critical temperatures as it is extremely challenging to determine. Furthermore, the need for a sophisticated and feasible method for determining the temperature range that goes beyond the scope of the standard empirical formula appears to be strongly emphasized by various machine-learning approaches. This paper uses a stacking machine learning approach to train itself on the complex characteristics of superconductive materials in order to accurately predict critical temperatures. In comparison to other previous accessible research investigations, this model demonstrated a promising performance with an RMSE of 9.68 and an R2 score of 0.922. The findings presented here could be a viable technique to shed new insight on the efficient implementation of the stacking ensemble method with hyperparameter optimization (HPO).
GlobalBench: A Benchmark for Global Progress in Natural Language Processing
May 24, 2023



Despite the major advances in NLP, significant disparities in NLP system performance across languages still exist. Arguably, these are due to uneven resource allocation and sub-optimal incentives to work on less resourced languages. To track and further incentivize the global development of equitable language technology, we introduce GlobalBench. Prior multilingual benchmarks are static and have focused on a limited number of tasks and languages. In contrast, GlobalBench is an ever-expanding collection that aims to dynamically track progress on all NLP datasets in all languages. Rather than solely measuring accuracy, GlobalBench also tracks the estimated per-speaker utility and equity of technology across all languages, providing a multi-faceted view of how language technology is serving people of the world. Furthermore, GlobalBench is designed to identify the most under-served languages, and rewards research efforts directed towards those languages. At present, the most under-served languages are the ones with a relatively high population, but nonetheless overlooked by composite multilingual benchmarks (like Punjabi, Portuguese, and Wu Chinese). Currently, GlobalBench covers 966 datasets in 190 languages, and has 1,128 system submissions spanning 62 languages.
GMNLP at SemEval-2023 Task 12: Sentiment Analysis with Phylogeny-Based Adapters
Apr 25, 2023



This report describes GMU's sentiment analysis system for the SemEval-2023 shared task AfriSenti-SemEval. We participated in all three sub-tasks: Monolingual, Multilingual, and Zero-Shot. Our approach uses models initialized with AfroXLMR-large, a pre-trained multilingual language model trained on African languages and fine-tuned correspondingly. We also introduce augmented training data along with original training data. Alongside finetuning, we perform phylogeny-based adapter tuning to create several models and ensemble the best models for the final submission. Our system achieves the best F1-score on track 5: Amharic, with 6.2 points higher F1-score than the second-best performing system on this track. Overall, our system ranks 5th among the 10 systems participating in all 15 tracks.