 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDIALECTBENCH: A NLP Benchmark for Dialects, Varieties, and Closely-Related Languages
Paper and Code
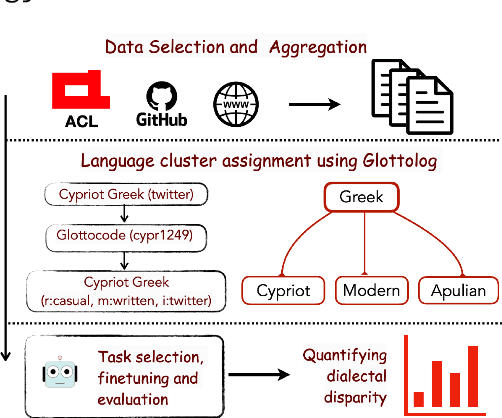
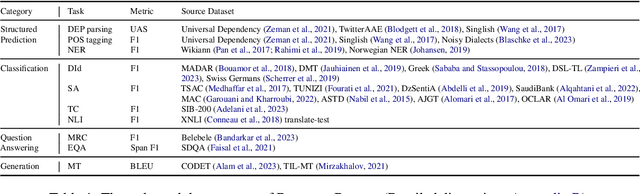
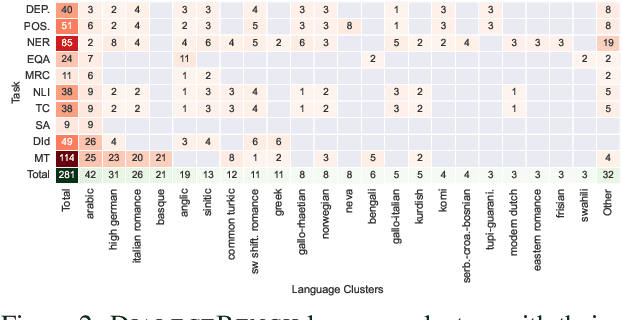

Language technologies should be judged on their usefulness in real-world use cases. An often overlooked aspect in natural language processing (NLP) research and evaluation is language variation in the form of non-standard dialects or language varieties (hereafter, varieties). Most NLP benchmarks are limited to standard language varieties. To fill this gap, we propose DIALECTBENCH, the first-ever large-scale benchmark for NLP on varieties, which aggregates an extensive set of task-varied variety datasets (10 text-level tasks covering 281 varieties). This allows for a comprehensive evaluation of NLP system performance on different language varieties. We provide substantial evidence of performance disparities between standard and non-standard language varieties, and we also identify language clusters with large performance divergence across tasks. We believe DIALECTBENCH provides a comprehensive view of the current state of NLP for language varieties and one step towards advancing it further. Code/data: https://github.com/ffaisal93/DialectBench