 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBASS: Benchmarking Audio LMs for Musical Structure and Semantic Reasoning
Feb 03, 2026Music understanding is a complex task that often requires reasoning over both structural and semantic elements of audio. We introduce BASS, designed to evaluate music understanding and reasoning in audio language models across four broad categories: structural segmentation, lyric transcription, musicological analysis, and artist collaboration. BASS comprises 2658 questions spanning 12 tasks, 1993 unique songs and covering over 138 hours of music from a wide range of genres and tracks, crafted to assess musicological knowledge and reasoning in real-world scenarios. We evaluate 14 open-source and frontier multimodal LMs, finding that even state-of-the-art models struggle on higher-level reasoning tasks such as structural segmentation and artist collaboration, while performing best on lyric transcription. Our analysis reveals that current models leverage linguistic priors effectively but remain limited in reasoning over musical structure, vocal, and musicological attributes. BASS provides an evaluation framework with widespread applications in music recommendation and search and has the potential to guide the development of audio LMs.
Broken Tokens? Your Language Model can Secretly Handle Non-Canonical Tokenizations
Jun 23, 2025Modern tokenizers employ deterministic algorithms to map text into a single "canonical" token sequence, yet the same string can be encoded as many non-canonical tokenizations using the tokenizer vocabulary. In this work, we investigate the robustness of LMs to text encoded with non-canonical tokenizations entirely unseen during training. Surprisingly, when evaluated across 20 benchmarks, we find that instruction-tuned models retain up to 93.4% of their original performance when given a randomly sampled tokenization, and 90.8% with character-level tokenization. We see that overall stronger models tend to be more robust, and robustness diminishes as the tokenization departs farther from the canonical form. Motivated by these results, we then identify settings where non-canonical tokenization schemes can *improve* performance, finding that character-level segmentation improves string manipulation and code understanding tasks by up to +14%, and right-aligned digit grouping enhances large-number arithmetic by +33%. Finally, we investigate the source of this robustness, finding that it arises in the instruction-tuning phase. We show that while both base and post-trained models grasp the semantics of non-canonical tokenizations (perceiving them as containing misspellings), base models try to mimic the imagined mistakes and degenerate into nonsensical output, while post-trained models are committed to fluent responses. Overall, our findings suggest that models are less tied to their tokenizer than previously believed, and demonstrate the promise of intervening on tokenization at inference time to boost performance.
BLAB: Brutally Long Audio Bench
May 05, 2025Developing large audio language models (LMs) capable of understanding diverse spoken interactions is essential for accommodating the multimodal nature of human communication and can increase the accessibility of language technologies across different user populations. Recent work on audio LMs has primarily evaluated their performance on short audio segments, typically under 30 seconds, with limited exploration of long-form conversational speech segments that more closely reflect natural user interactions with these models. We introduce Brutally Long Audio Bench (BLAB), a challenging long-form audio benchmark that evaluates audio LMs on localization, duration estimation, emotion, and counting tasks using audio segments averaging 51 minutes in length. BLAB consists of 833+ hours of diverse, full-length audio clips, each paired with human-annotated, text-based natural language questions and answers. Our audio data were collected from permissively licensed sources and underwent a human-assisted filtering process to ensure task compliance. We evaluate six open-source and proprietary audio LMs on BLAB and find that all of them, including advanced models such as Gemini 2.0 Pro and GPT-4o, struggle with the tasks in BLAB. Our comprehensive analysis reveals key insights into the trade-offs between task difficulty and audio duration. In general, we find that audio LMs struggle with long-form speech, with performance declining as duration increases. They perform poorly on localization, temporal reasoning, counting, and struggle to understand non-phonemic information, relying more on prompts than audio content. BLAB serves as a challenging evaluation framework to develop audio LMs with robust long-form audio understanding capabilities.
MAGNET: Improving the Multilingual Fairness of Language Models with Adaptive Gradient-Based Tokenization
Jul 11, 2024



In multilingual settings, non-Latin scripts and low-resource languages are usually disadvantaged in terms of language models' utility, efficiency, and cost. Specifically, previous studies have reported multiple modeling biases that the current tokenization algorithms introduce to non-Latin script languages, the main one being over-segmentation. In this work, we propose MAGNET; multilingual adaptive gradient-based tokenization to reduce over-segmentation via adaptive gradient-based subword tokenization. MAGNET learns to predict segment boundaries between byte tokens in a sequence via sub-modules within the model, which act as internal boundary predictors (tokenizers). Previous gradient-based tokenization methods aimed for uniform compression across sequences by integrating a single boundary predictor during training and optimizing it end-to-end through stochastic reparameterization alongside the next token prediction objective. However, this approach still results in over-segmentation for non-Latin script languages in multilingual settings. In contrast, MAGNET offers a customizable architecture where byte-level sequences are routed through language-script-specific predictors, each optimized for its respective language script. This modularity enforces equitable segmentation granularity across different language scripts compared to previous methods. Through extensive experiments, we demonstrate that in addition to reducing segmentation disparities, MAGNET also enables faster language modelling and improves downstream utility.
Voices Unheard: NLP Resources and Models for Yorùbá Regional Dialects
Jun 27, 2024Yor\`ub\'a an African language with roughly 47 million speakers encompasses a continuum with several dialects. Recent efforts to develop NLP technologies for African languages have focused on their standard dialects, resulting in disparities for dialects and varieties for which there are little to no resources or tools. We take steps towards bridging this gap by introducing a new high-quality parallel text and speech corpus YOR\`ULECT across three domains and four regional Yor\`ub\'a dialects. To develop this corpus, we engaged native speakers, travelling to communities where these dialects are spoken, to collect text and speech data. Using our newly created corpus, we conducted extensive experiments on (text) machine translation, automatic speech recognition, and speech-to-text translation. Our results reveal substantial performance disparities between standard Yor\`ub\'a and the other dialects across all tasks. However, we also show that with dialect-adaptive finetuning, we are able to narrow this gap. We believe our dataset and experimental analysis will contribute greatly to developing NLP tools for Yor\`ub\'a and its dialects, and potentially for other African languages, by improving our understanding of existing challenges and offering a high-quality dataset for further development. We release YOR\`ULECT dataset and models publicly under an open license.
Teaching LLMs to Abstain across Languages via Multilingual Feedback
Jun 22, 2024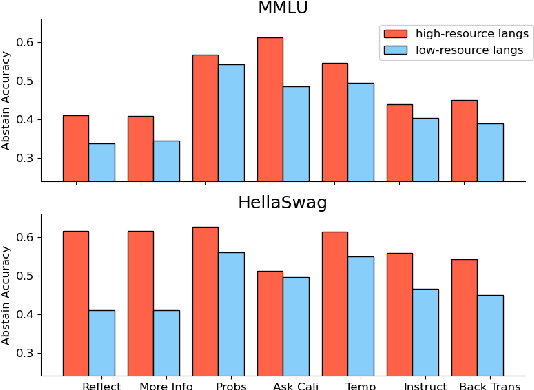
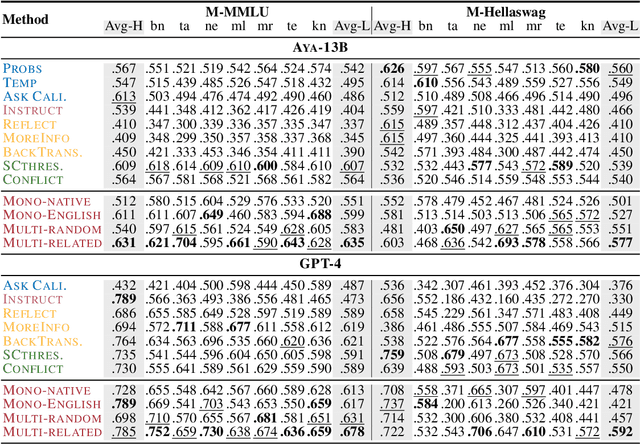
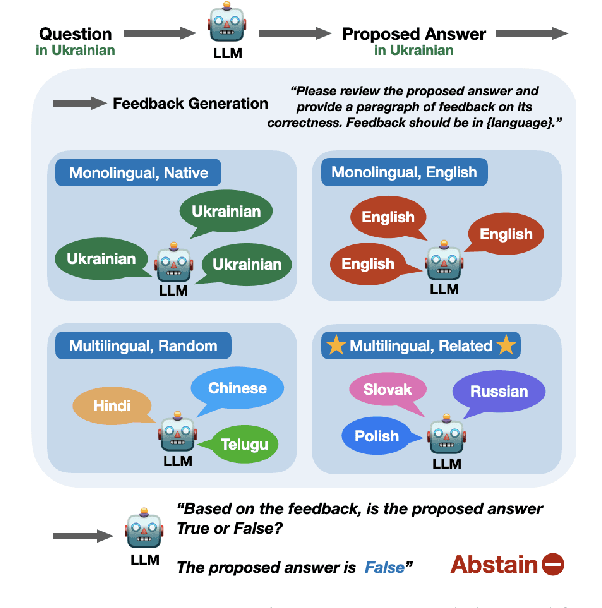
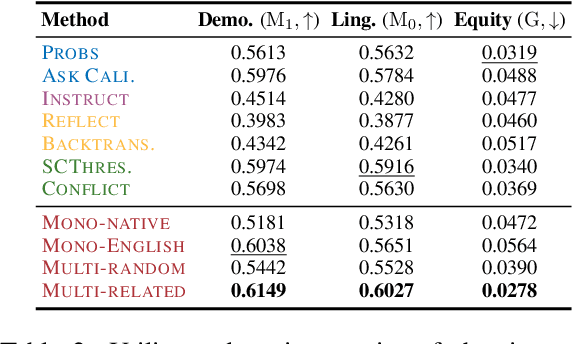
Multilingual LLMs often have knowledge disparities across languages, with larger gaps in under-resourced languages. Teaching LLMs to abstain in the face of knowledge gaps is thus a promising strategy to mitigate hallucinations in multilingual settings. However, previous studies on LLM abstention primarily focus on English; we find that directly applying existing solutions beyond English results in up to 20.5% performance gaps between high and low-resource languages, potentially due to LLMs' drop in calibration and reasoning beyond a few resource-rich languages. To this end, we propose strategies to enhance LLM abstention by learning from multilingual feedback, where LLMs self-reflect on proposed answers in one language by generating multiple feedback items in related languages: we show that this helps identifying the knowledge gaps across diverse languages, cultures, and communities. Extensive experiments demonstrate that our multilingual feedback approach outperforms various strong baselines, achieving up to 9.2% improvement for low-resource languages across three black-box and open models on three datasets, featuring open-book, closed-book, and commonsense QA. Further analysis reveals that multilingual feedback is both an effective and a more equitable abstain strategy to serve diverse language speakers, and cultural factors have great impact on language selection and LLM abstention behavior, highlighting future directions for multilingual and multi-cultural reliable language modeling.
Critical Learning Periods: Leveraging Early Training Dynamics for Efficient Data Pruning
May 29, 2024
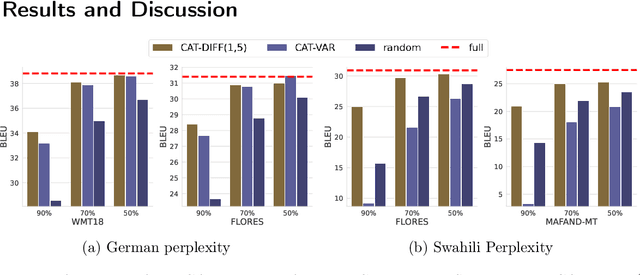
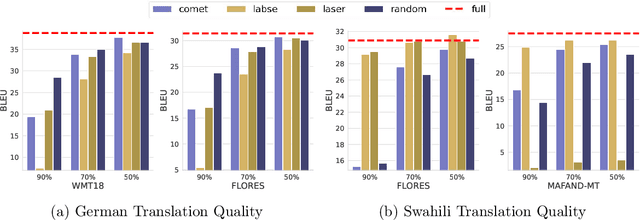
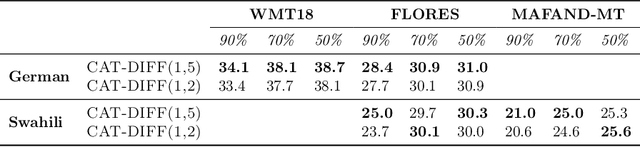
Neural Machine Translation models are extremely data and compute-hungry. However, not all data points contribute equally to model training and generalization. Data pruning to remove the low-value data points has the benefit of drastically reducing the compute budget without significant drop in model performance. In this paper, we propose a new data pruning technique: Checkpoints Across Time (CAT), that leverages early model training dynamics to identify the most relevant data points for model performance. We benchmark CAT against several data pruning techniques including COMET-QE, LASER and LaBSE. We find that CAT outperforms the benchmarks on Indo-European languages on multiple test sets. When applied to English-German, English-French and English-Swahili translation tasks, CAT achieves comparable performance to using the full dataset, while pruning up to 50% of training data. We inspect the data points that CAT selects and find that it tends to favour longer sentences and sentences with unique or rare words.
DIALECTBENCH: A NLP Benchmark for Dialects, Varieties, and Closely-Related Languages
Mar 16, 2024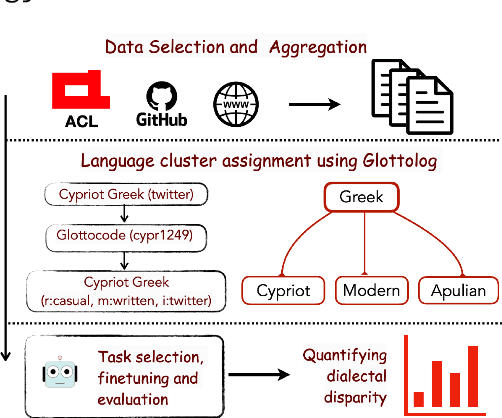
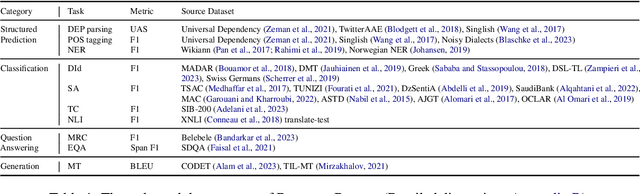
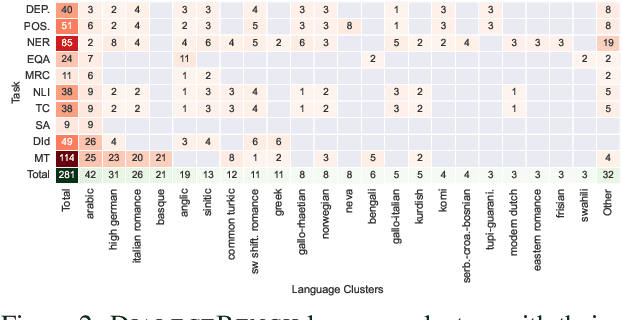

Language technologies should be judged on their usefulness in real-world use cases. An often overlooked aspect in natural language processing (NLP) research and evaluation is language variation in the form of non-standard dialects or language varieties (hereafter, varieties). Most NLP benchmarks are limited to standard language varieties. To fill this gap, we propose DIALECTBENCH, the first-ever large-scale benchmark for NLP on varieties, which aggregates an extensive set of task-varied variety datasets (10 text-level tasks covering 281 varieties). This allows for a comprehensive evaluation of NLP system performance on different language varieties. We provide substantial evidence of performance disparities between standard and non-standard language varieties, and we also identify language clusters with large performance divergence across tasks. We believe DIALECTBENCH provides a comprehensive view of the current state of NLP for language varieties and one step towards advancing it further. Code/data: https://github.com/ffaisal93/DialectBench
MYTE: Morphology-Driven Byte Encoding for Better and Fairer Multilingual Language Modeling
Mar 15, 2024A major consideration in multilingual language modeling is how to best represent languages with diverse vocabularies and scripts. Although contemporary text encoding methods cover most of the world's writing systems, they exhibit bias towards the high-resource languages of the Global West. As a result, texts of underrepresented languages tend to be segmented into long sequences of linguistically meaningless units. To address the disparities, we introduce a new paradigm that encodes the same information with segments of consistent size across diverse languages. Our encoding convention (MYTE) is based on morphemes, as their inventories are more balanced across languages than characters, which are used in previous methods. We show that MYTE produces shorter encodings for all 99 analyzed languages, with the most notable improvements for non-European languages and non-Latin scripts. This, in turn, improves multilingual LM performance and diminishes the perplexity gap throughout diverse languages.
Extracting Lexical Features from Dialects via Interpretable Dialect Classifiers
Feb 27, 2024
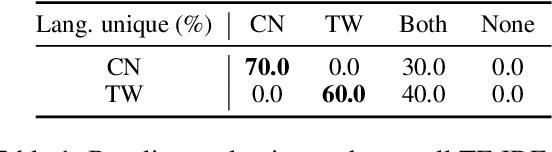
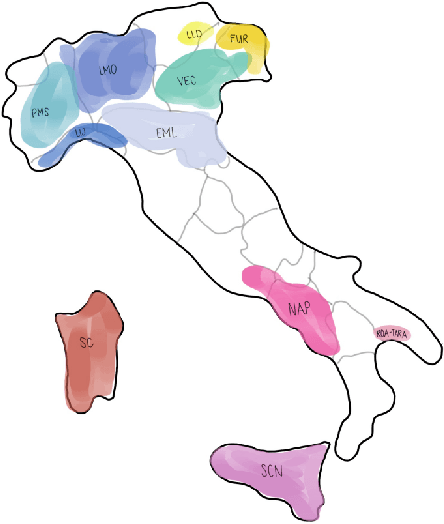
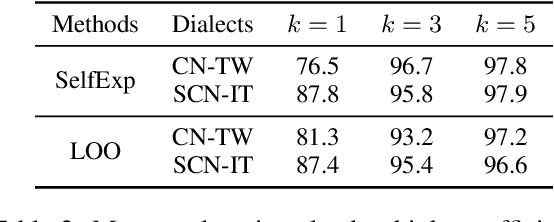
Identifying linguistic differences between dialects of a language often requires expert knowledge and meticulous human analysis. This is largely due to the complexity and nuance involved in studying various dialects. We present a novel approach to extract distinguishing lexical features of dialects by utilizing interpretable dialect classifiers, even in the absence of human experts. We explore both post-hoc and intrinsic approaches to interpretability, conduct experiments on Mandarin, Italian, and Low Saxon, and experimentally demonstrate that our method successfully identifies key language-specific lexical features that contribute to dialectal variations.