 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Multilingual Math Reasoning for African Languages
May 26, 2025
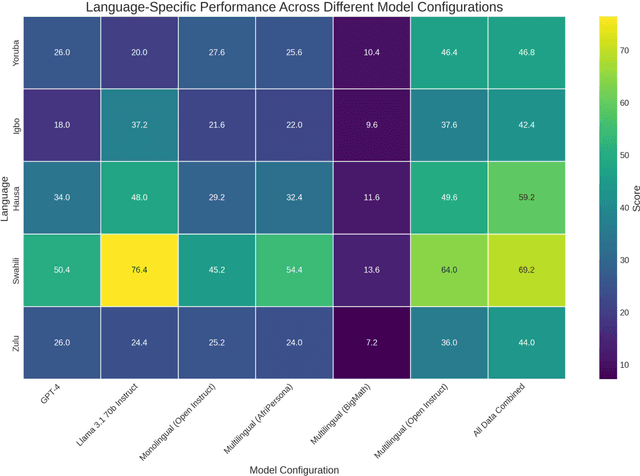
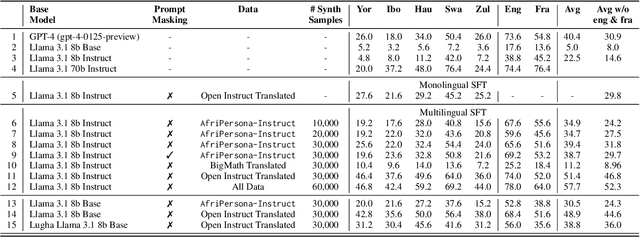

Researchers working on low-resource languages face persistent challenges due to limited data availability and restricted access to computational resources. Although most large language models (LLMs) are predominantly trained in high-resource languages, adapting them to low-resource contexts, particularly African languages, requires specialized techniques. Several strategies have emerged for adapting models to low-resource languages in todays LLM landscape, defined by multi-stage pre-training and post-training paradigms. However, the most effective approaches remain uncertain. This work systematically investigates which adaptation strategies yield the best performance when extending existing LLMs to African languages. We conduct extensive experiments and ablation studies to evaluate different combinations of data types (translated versus synthetically generated), training stages (pre-training versus post-training), and other model adaptation configurations. Our experiments focuses on mathematical reasoning tasks, using the Llama 3.1 model family as our base model.
NoMIRACL: Knowing When You Don't Know for Robust Multilingual Retrieval-Augmented Generation
Dec 18, 2023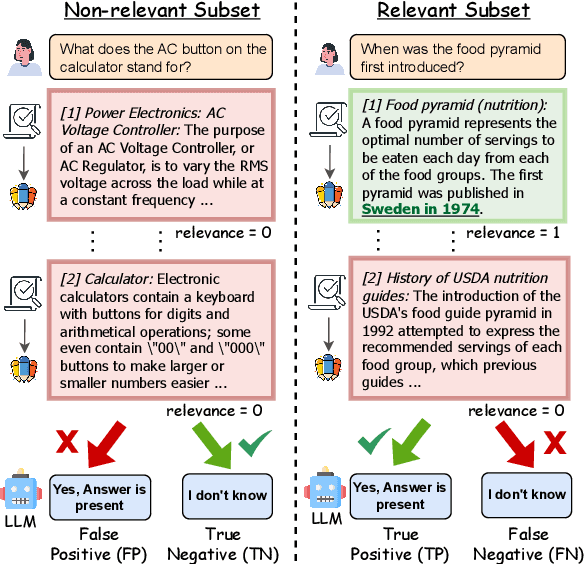

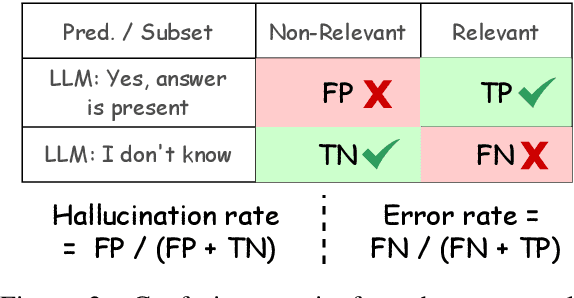
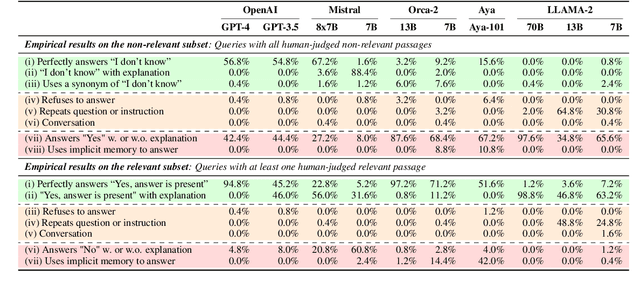
Retrieval-augmented generation (RAG) grounds large language model (LLM) output by leveraging external knowledge sources to reduce factual hallucinations. However, prior works lack a comprehensive evaluation of different language families, making it challenging to evaluate LLM robustness against errors in external retrieved knowledge. To overcome this, we establish NoMIRACL, a human-annotated dataset for evaluating LLM robustness in RAG across 18 typologically diverse languages. NoMIRACL includes both a non-relevant and a relevant subset. Queries in the non-relevant subset contain passages manually judged as non-relevant or noisy, whereas queries in the relevant subset include at least a single judged relevant passage. We measure LLM robustness using two metrics: (i) hallucination rate, measuring model tendency to hallucinate an answer, when the answer is not present in passages in the non-relevant subset, and (ii) error rate, measuring model inaccuracy to recognize relevant passages in the relevant subset. We build a GPT-4 baseline which achieves a 33.2% hallucination rate on the non-relevant and a 14.9% error rate on the relevant subset on average. Our evaluation reveals that GPT-4 hallucinates frequently in high-resource languages, such as French or English. This work highlights an important avenue for future research to improve LLM robustness to learn how to better reject non-relevant information in RAG.
GAIA Search: Hugging Face and Pyserini Interoperability for NLP Training Data Exploration
Jun 02, 2023Noticing the urgent need to provide tools for fast and user-friendly qualitative analysis of large-scale textual corpora of the modern NLP, we propose to turn to the mature and well-tested methods from the domain of Information Retrieval (IR) - a research field with a long history of tackling TB-scale document collections. We discuss how Pyserini - a widely used toolkit for reproducible IR research can be integrated with the Hugging Face ecosystem of open-source AI libraries and artifacts. We leverage the existing functionalities of both platforms while proposing novel features further facilitating their integration. Our goal is to give NLP researchers tools that will allow them to develop retrieval-based instrumentation for their data analytics needs with ease and agility. We include a Jupyter Notebook-based walk through the core interoperability features, available on GitHub at https://github.com/huggingface/gaia. We then demonstrate how the ideas we present can be operationalized to create a powerful tool for qualitative data analysis in NLP. We present GAIA Search - a search engine built following previously laid out principles, giving access to four popular large-scale text collections. GAIA serves a dual purpose of illustrating the potential of methodologies we discuss but also as a standalone qualitative analysis tool that can be leveraged by NLP researchers aiming to understand datasets prior to using them in training. GAIA is hosted live on Hugging Face Spaces - https://huggingface.co/spaces/spacerini/gaia.
AfriQA: Cross-lingual Open-Retrieval Question Answering for African Languages
May 11, 2023



African languages have far less in-language content available digitally, making it challenging for question answering systems to satisfy the information needs of users. Cross-lingual open-retrieval question answering (XOR QA) systems -- those that retrieve answer content from other languages while serving people in their native language -- offer a means of filling this gap. To this end, we create AfriQA, the first cross-lingual QA dataset with a focus on African languages. AfriQA includes 12,000+ XOR QA examples across 10 African languages. While previous datasets have focused primarily on languages where cross-lingual QA augments coverage from the target language, AfriQA focuses on languages where cross-lingual answer content is the only high-coverage source of answer content. Because of this, we argue that African languages are one of the most important and realistic use cases for XOR QA. Our experiments demonstrate the poor performance of automatic translation and multilingual retrieval methods. Overall, AfriQA proves challenging for state-of-the-art QA models. We hope that the dataset enables the development of more equitable QA technology.
Evaluating Embedding APIs for Information Retrieval
May 10, 2023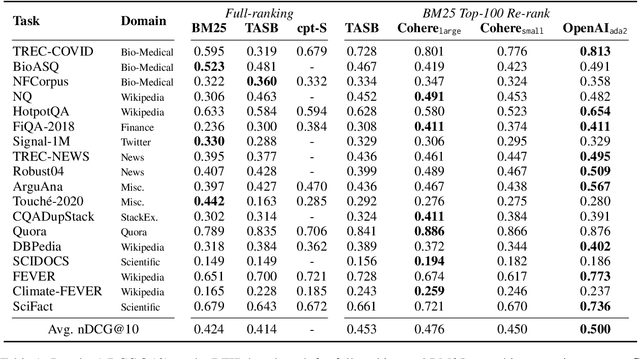
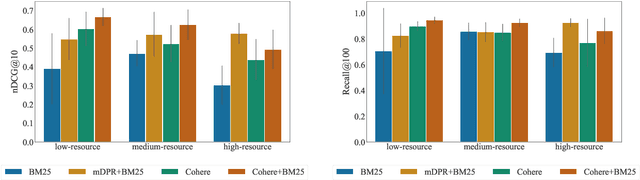
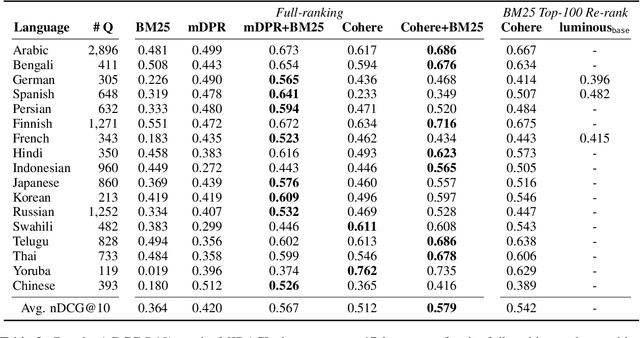
The ever-increasing size of language models curtails their widespread access to the community, thereby galvanizing many companies and startups into offering access to large language models through APIs. One particular API, suitable for dense retrieval, is the semantic embedding API that builds vector representations of a given text. With a growing number of APIs at our disposal, in this paper, our goal is to analyze semantic embedding APIs in realistic retrieval scenarios in order to assist practitioners and researchers in finding suitable services according to their needs. Specifically, we wish to investigate the capabilities of existing APIs on domain generalization and multilingual retrieval. For this purpose, we evaluate the embedding APIs on two standard benchmarks, BEIR, and MIRACL. We find that re-ranking BM25 results using the APIs is a budget-friendly approach and is most effective on English, in contrast to the standard practice, i.e., employing them as first-stage retrievers. For non-English retrieval, re-ranking still improves the results, but a hybrid model with BM25 works best albeit at a higher cost. We hope our work lays the groundwork for thoroughly evaluating APIs that are critical in search and more broadly, in information retrieval.
MasakhaNEWS: News Topic Classification for African languages
Apr 19, 2023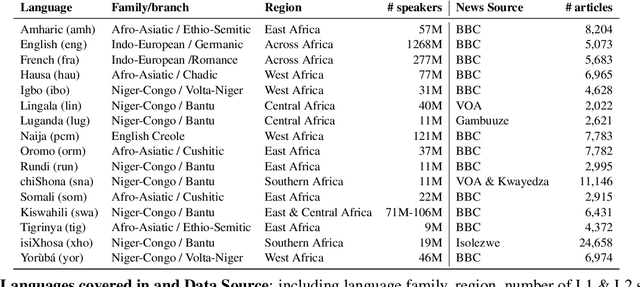
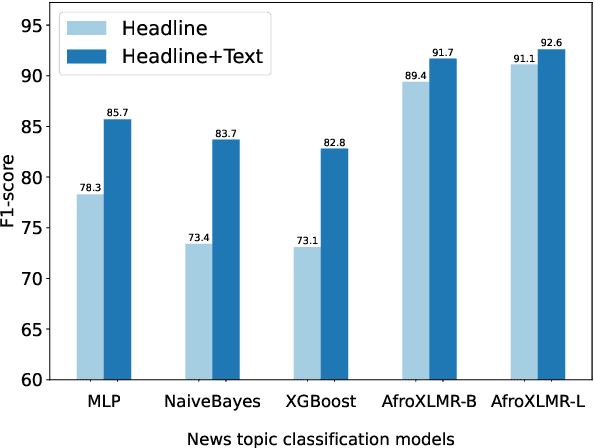
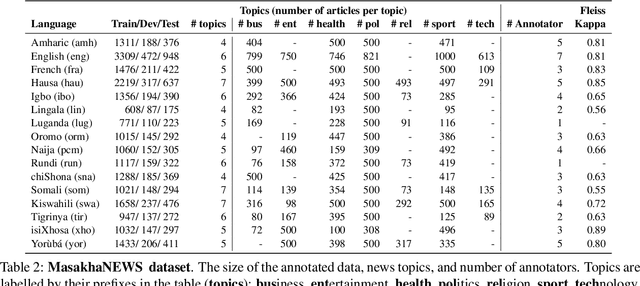
African languages are severely under-represented in NLP research due to lack of datasets covering several NLP tasks. While there are individual language specific datasets that are being expanded to different tasks, only a handful of NLP tasks (e.g. named entity recognition and machine translation) have standardized benchmark datasets covering several geographical and typologically-diverse African languages. In this paper, we develop MasakhaNEWS -- a new benchmark dataset for news topic classification covering 16 languages widely spoken in Africa. We provide an evaluation of baseline models by training classical machine learning models and fine-tuning several language models. Furthermore, we explore several alternatives to full fine-tuning of language models that are better suited for zero-shot and few-shot learning such as cross-lingual parameter-efficient fine-tuning (like MAD-X), pattern exploiting training (PET), prompting language models (like ChatGPT), and prompt-free sentence transformer fine-tuning (SetFit and Cohere Embedding API). Our evaluation in zero-shot setting shows the potential of prompting ChatGPT for news topic classification in low-resource African languages, achieving an average performance of 70 F1 points without leveraging additional supervision like MAD-X. In few-shot setting, we show that with as little as 10 examples per label, we achieved more than 90\% (i.e. 86.0 F1 points) of the performance of full supervised training (92.6 F1 points) leveraging the PET approach.
Simple Yet Effective Neural Ranking and Reranking Baselines for Cross-Lingual Information Retrieval
Apr 03, 2023The advent of multilingual language models has generated a resurgence of interest in cross-lingual information retrieval (CLIR), which is the task of searching documents in one language with queries from another. However, the rapid pace of progress has led to a confusing panoply of methods and reproducibility has lagged behind the state of the art. In this context, our work makes two important contributions: First, we provide a conceptual framework for organizing different approaches to cross-lingual retrieval using multi-stage architectures for mono-lingual retrieval as a scaffold. Second, we implement simple yet effective reproducible baselines in the Anserini and Pyserini IR toolkits for test collections from the TREC 2022 NeuCLIR Track, in Persian, Russian, and Chinese. Our efforts are built on a collaboration of the two teams that submitted the most effective runs to the TREC evaluation. These contributions provide a firm foundation for future advances.
Spacerini: Plug-and-play Search Engines with Pyserini and Hugging Face
Feb 28, 2023We present Spacerini, a modular framework for seamless building and deployment of interactive search applications, designed to facilitate the qualitative analysis of large scale research datasets. Spacerini integrates features from both the Pyserini toolkit and the Hugging Face ecosystem to ease the indexing text collections and deploy them as search engines for ad-hoc exploration and to make the retrieval of relevant data points quick and efficient. The user-friendly interface enables searching through massive datasets in a no-code fashion, making Spacerini broadly accessible to anyone looking to qualitatively audit their text collections. This is useful both to IR~researchers aiming to demonstrate the capabilities of their indexes in a simple and interactive way, and to NLP~researchers looking to better understand and audit the failure modes of large language models. The framework is open source and available on GitHub: https://github.com/castorini/hf-spacerini, and includes utilities to load, pre-process, index, and deploy local and web search applications. A portfolio of applications created with Spacerini for a multitude of use cases can be found by visiting https://hf.co/spacerini.
Making a MIRACL: Multilingual Information Retrieval Across a Continuum of Languages
Oct 18, 2022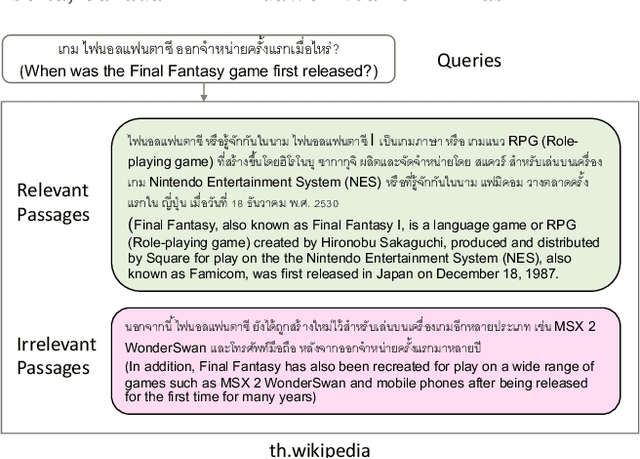
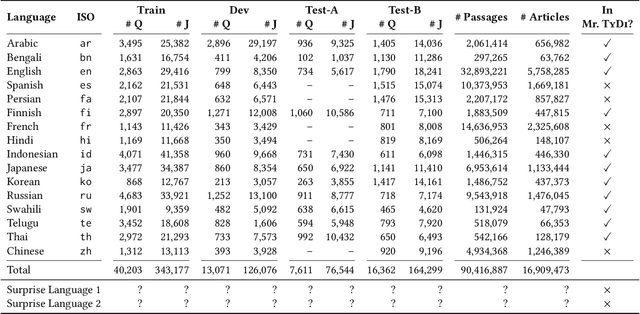
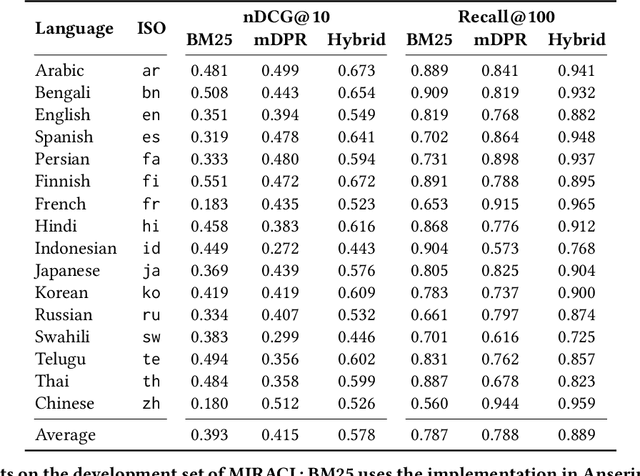
MIRACL (Multilingual Information Retrieval Across a Continuum of Languages) is a multilingual dataset we have built for the WSDM 2023 Cup challenge that focuses on ad hoc retrieval across 18 different languages, which collectively encompass over three billion native speakers around the world. These languages have diverse typologies, originate from many different language families, and are associated with varying amounts of available resources -- including what researchers typically characterize as high-resource as well as low-resource languages. Our dataset is designed to support the creation and evaluation of models for monolingual retrieval, where the queries and the corpora are in the same language. In total, we have gathered over 700k high-quality relevance judgments for around 77k queries over Wikipedia in these 18 languages, where all assessments have been performed by native speakers hired by our team. Our goal is to spur research that will improve retrieval across a continuum of languages, thus enhancing information access capabilities for diverse populations around the world, particularly those that have been traditionally underserved. This overview paper describes the dataset and baselines that we share with the community. The MIRACL website is live at http://miracl.ai/.
Better Than Whitespace: Information Retrieval for Languages without Custom Tokenizers
Oct 11, 2022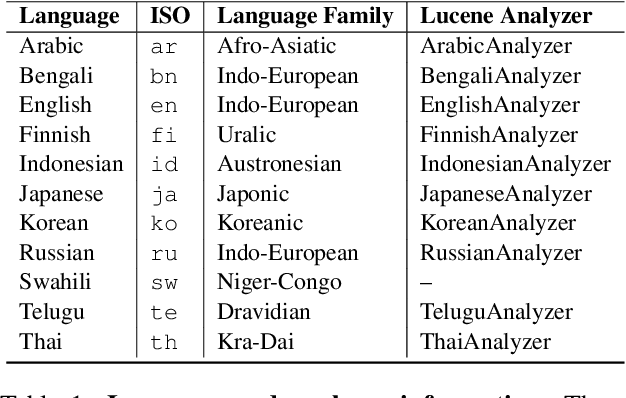
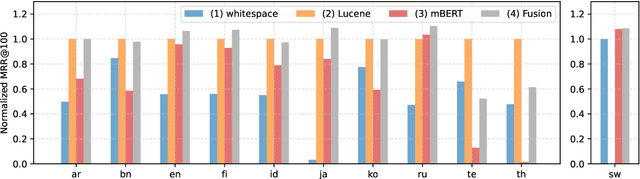
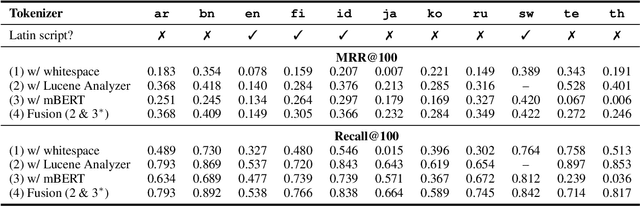
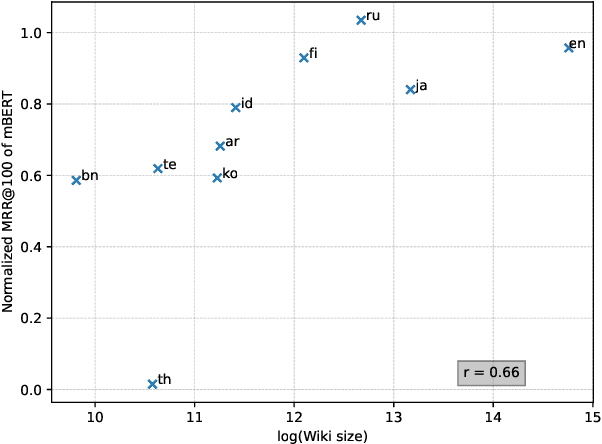
Tokenization is a crucial step in information retrieval, especially for lexical matching algorithms, where the quality of indexable tokens directly impacts the effectiveness of a retrieval system. Since different languages have unique properties, the design of the tokenization algorithm is usually language-specific and requires at least some lingustic knowledge. However, only a handful of the 7000+ languages on the planet benefit from specialized, custom-built tokenization algorithms, while the other languages are stuck with a "default" whitespace tokenizer, which cannot capture the intricacies of different languages. To address this challenge, we propose a different approach to tokenization for lexical matching retrieval algorithms (e.g., BM25): using the WordPiece tokenizer, which can be built automatically from unsupervised data. We test the approach on 11 typologically diverse languages in the MrTyDi collection: results show that the mBERT tokenizer provides strong relevance signals for retrieval "out of the box", outperforming whitespace tokenization on most languages. In many cases, our approach also improves retrieval effectiveness when combined with existing custom-built tokenizers.