 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAfri-MCQA: Multimodal Cultural Question Answering for African Languages
Jan 09, 2026Africa is home to over one-third of the world's languages, yet remains underrepresented in AI research. We introduce Afri-MCQA, the first Multilingual Cultural Question-Answering benchmark covering 7.5k Q&A pairs across 15 African languages from 12 countries. The benchmark offers parallel English-African language Q&A pairs across text and speech modalities and was entirely created by native speakers. Benchmarking large language models (LLMs) on Afri-MCQA shows that open-weight models perform poorly across evaluated cultures, with near-zero accuracy on open-ended VQA when queried in native language or speech. To evaluate linguistic competence, we include control experiments meant to assess this specific aspect separate from cultural knowledge, and we observe significant performance gaps between native languages and English for both text and speech. These findings underscore the need for speech-first approaches, culturally grounded pretraining, and cross-lingual cultural transfer. To support more inclusive multimodal AI development in African languages, we release our Afri-MCQA under academic license or CC BY-NC 4.0 on HuggingFace (https://huggingface.co/datasets/Atnafu/Afri-MCQA)
MERLIN: Multi-Stage Curriculum Alignment for Multilingual Encoder and LLM Fusion
Sep 09, 2025Large language models excel in English but still struggle with complex reasoning in many low-resource languages (LRLs). Existing encoder-plus-decoder methods such as LangBridge and MindMerger raise accuracy on mid and high-resource languages, yet they leave a large gap on LRLs. We present MERLIN, a two-stage model-stacking framework that applies a curriculum learning strategy -- from general bilingual bitext to task-specific data -- and adapts only a small set of DoRA weights. On the AfriMGSM benchmark MERLIN improves exact-match accuracy by +12.9 pp over MindMerger and outperforms GPT-4o-mini. It also yields consistent gains on MGSM and MSVAMP (+0.9 and +2.8 pp), demonstrating effectiveness across both low and high-resource settings.
MasakhaNEWS: News Topic Classification for African languages
Apr 19, 2023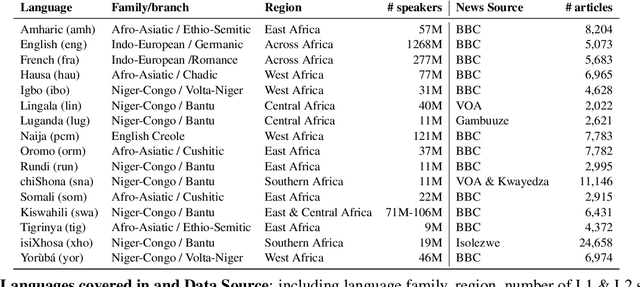
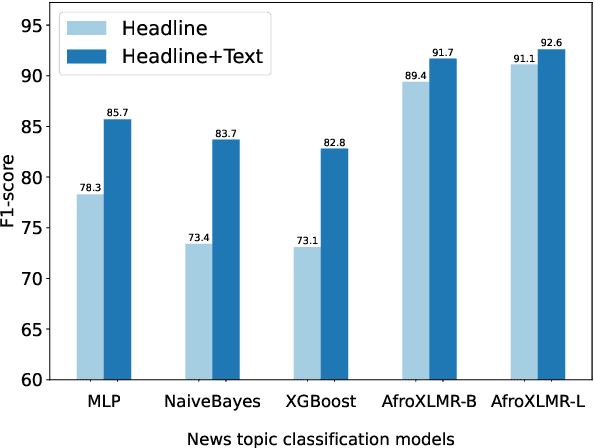
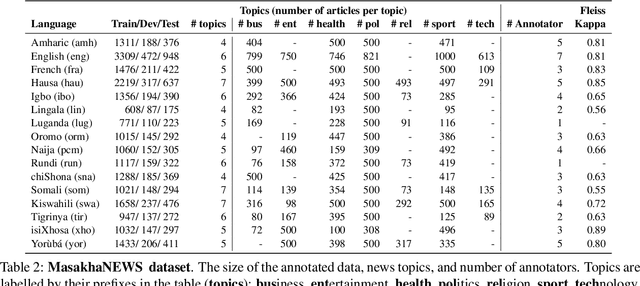
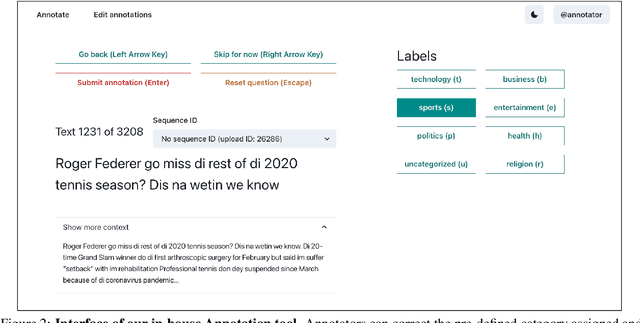
African languages are severely under-represented in NLP research due to lack of datasets covering several NLP tasks. While there are individual language specific datasets that are being expanded to different tasks, only a handful of NLP tasks (e.g. named entity recognition and machine translation) have standardized benchmark datasets covering several geographical and typologically-diverse African languages. In this paper, we develop MasakhaNEWS -- a new benchmark dataset for news topic classification covering 16 languages widely spoken in Africa. We provide an evaluation of baseline models by training classical machine learning models and fine-tuning several language models. Furthermore, we explore several alternatives to full fine-tuning of language models that are better suited for zero-shot and few-shot learning such as cross-lingual parameter-efficient fine-tuning (like MAD-X), pattern exploiting training (PET), prompting language models (like ChatGPT), and prompt-free sentence transformer fine-tuning (SetFit and Cohere Embedding API). Our evaluation in zero-shot setting shows the potential of prompting ChatGPT for news topic classification in low-resource African languages, achieving an average performance of 70 F1 points without leveraging additional supervision like MAD-X. In few-shot setting, we show that with as little as 10 examples per label, we achieved more than 90\% (i.e. 86.0 F1 points) of the performance of full supervised training (92.6 F1 points) leveraging the PET approach.
A Few Thousand Translations Go a Long Way! Leveraging Pre-trained Models for African News Translation
May 04, 2022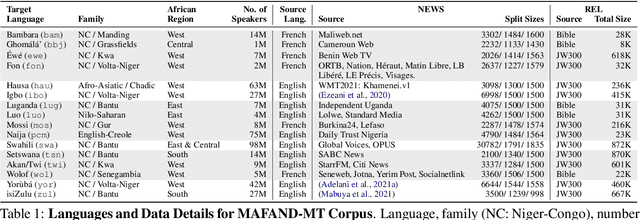
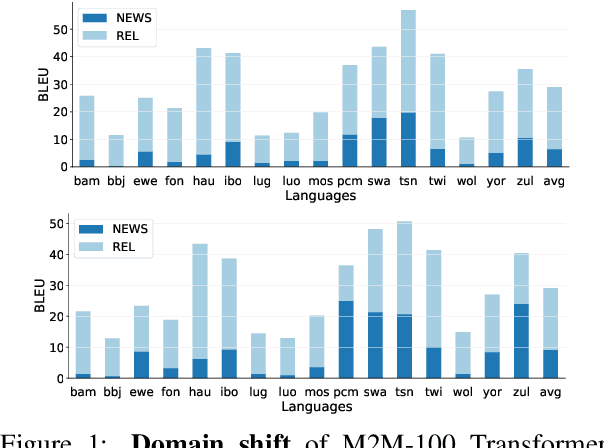

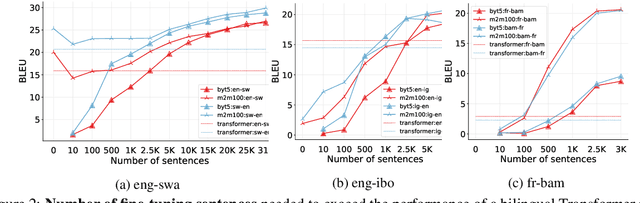
Recent advances in the pre-training of language models leverage large-scale datasets to create multilingual models. However, low-resource languages are mostly left out in these datasets. This is primarily because many widely spoken languages are not well represented on the web and therefore excluded from the large-scale crawls used to create datasets. Furthermore, downstream users of these models are restricted to the selection of languages originally chosen for pre-training. This work investigates how to optimally leverage existing pre-trained models to create low-resource translation systems for 16 African languages. We focus on two questions: 1) How can pre-trained models be used for languages not included in the initial pre-training? and 2) How can the resulting translation models effectively transfer to new domains? To answer these questions, we create a new African news corpus covering 16 languages, of which eight languages are not part of any existing evaluation dataset. We demonstrate that the most effective strategy for transferring both to additional languages and to additional domains is to fine-tune large pre-trained models on small quantities of high-quality translation data.