 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMGSM-Pro: A Simple Strategy for Robust Multilingual Mathematical Reasoning Evaluation
Jan 29, 2026Large language models have made substantial progress in mathematical reasoning. However, benchmark development for multilingual evaluation has lagged behind English in both difficulty and recency. Recently, GSM-Symbolic showed a strong evidence of high variance when models are evaluated on different instantiations of the same question; however, the evaluation was conducted only in English. In this paper, we introduce MGSM-Pro, an extension of MGSM dataset with GSM-Symbolic approach. Our dataset provides five instantiations per MGSM question by varying names, digits and irrelevant context. Evaluations across nine languages reveal that many low-resource languages suffer large performance drops when tested on digit instantiations different from those in the original test set. We further find that some proprietary models, notably Gemini 2.5 Flash and GPT-4.1, are less robust to digit instantiation, whereas Claude 4.0 Sonnet is more robust. Among open models, GPT-OSS 120B and DeepSeek V3 show stronger robustness. Based on these findings, we recommend evaluating each problem using at least five digit-varying instantiations to obtain a more robust and realistic assessment of math reasoning.
Translation as a Scalable Proxy for Multilingual Evaluation
Jan 16, 2026The rapid proliferation of LLMs has created a critical evaluation paradox: while LLMs claim multilingual proficiency, comprehensive non-machine-translated benchmarks exist for fewer than 30 languages, leaving >98% of the world's 7,000 languages in an empirical void. Traditional benchmark construction faces scaling challenges such as cost, scarcity of domain experts, and data contamination. We evaluate the validity of a simpler alternative: can translation quality alone indicate a model's broader multilingual capabilities? Through systematic evaluation of 14 models (1B-72B parameters) across 9 diverse benchmarks and 7 translation metrics, we find that translation performance is a good indicator of downstream task success (e.g., Phi-4, median Pearson r: MetricX = 0.89, xCOMET = 0.91, SSA-COMET = 0.87). These results suggest that the representational abilities supporting faithful translation overlap with those required for multilingual understanding. Translation quality, thus emerges as a strong, inexpensive first-pass proxy of multilingual performance, enabling a translation-first screening with targeted follow-up for specific tasks.
Multilinguality as Sense Adaptation
Jan 15, 2026We approach multilinguality as sense adaptation: aligning latent meaning representations across languages rather than relying solely on shared parameters and scale. In this paper, we introduce SENse-based Symmetric Interlingual Alignment (SENSIA), which adapts a Backpack language model from one language to another by explicitly aligning sense-level mixtures and contextual representations on parallel data, while jointly training a target-language language modeling loss to preserve fluency. Across benchmarks on four typologically diverse languages, SENSIA generally outperforms comparable multilingual alignment methods and achieves competitive accuracy against monolingual from-scratch baselines while using 2-4x less target-language data. Analyses of learned sense geometry indicate that local sense topology and global structure relative to English are largely preserved, and ablations show that the method is robust in terms of design and scale.
AfriqueLLM: How Data Mixing and Model Architecture Impact Continued Pre-training for African Languages
Jan 10, 2026Large language models (LLMs) are increasingly multilingual, yet open models continue to underperform relative to proprietary systems, with the gap most pronounced for African languages. Continued pre-training (CPT) offers a practical route to language adaptation, but improvements on demanding capabilities such as mathematical reasoning often remain limited. This limitation is driven in part by the uneven domain coverage and missing task-relevant knowledge that characterize many low-resource language corpora. We present \texttt{AfriqueLLM}, a suite of open LLMs adapted to 20 African languages through CPT on 26B tokens. We perform a comprehensive empirical study across five base models spanning sizes and architectures, including Llama 3.1, Gemma 3, and Qwen 3, and systematically analyze how CPT data composition shapes downstream performance. In particular, we vary mixtures that include math, code, and synthetic translated data, and evaluate the resulting models on a range of multilingual benchmarks. Our results identify data composition as the primary driver of CPT gains. Adding math, code, and synthetic translated data yields consistent improvements, including on reasoning-oriented evaluations. Within a fixed architecture, larger models typically improve performance, but architectural choices dominate scale when comparing across model families. Moreover, strong multilingual performance in the base model does not reliably predict post-CPT outcomes; robust architectures coupled with task-aligned data provide a more dependable recipe. Finally, our best models improve long-context performance, including document-level translation. Models have been released on [Huggingface](https://huggingface.co/collections/McGill-NLP/afriquellm).
Afri-MCQA: Multimodal Cultural Question Answering for African Languages
Jan 09, 2026Africa is home to over one-third of the world's languages, yet remains underrepresented in AI research. We introduce Afri-MCQA, the first Multilingual Cultural Question-Answering benchmark covering 7.5k Q&A pairs across 15 African languages from 12 countries. The benchmark offers parallel English-African language Q&A pairs across text and speech modalities and was entirely created by native speakers. Benchmarking large language models (LLMs) on Afri-MCQA shows that open-weight models perform poorly across evaluated cultures, with near-zero accuracy on open-ended VQA when queried in native language or speech. To evaluate linguistic competence, we include control experiments meant to assess this specific aspect separate from cultural knowledge, and we observe significant performance gaps between native languages and English for both text and speech. These findings underscore the need for speech-first approaches, culturally grounded pretraining, and cross-lingual cultural transfer. To support more inclusive multimodal AI development in African languages, we release our Afri-MCQA under academic license or CC BY-NC 4.0 on HuggingFace (https://huggingface.co/datasets/Atnafu/Afri-MCQA)
Ibom NLP: A Step Toward Inclusive Natural Language Processing for Nigeria's Minority Languages
Nov 09, 2025Nigeria is the most populous country in Africa with a population of more than 200 million people. More than 500 languages are spoken in Nigeria and it is one of the most linguistically diverse countries in the world. Despite this, natural language processing (NLP) research has mostly focused on the following four languages: Hausa, Igbo, Nigerian-Pidgin, and Yoruba (i.e <1% of the languages spoken in Nigeria). This is in part due to the unavailability of textual data in these languages to train and apply NLP algorithms. In this work, we introduce ibom -- a dataset for machine translation and topic classification in four Coastal Nigerian languages from the Akwa Ibom State region: Anaang, Efik, Ibibio, and Oro. These languages are not represented in Google Translate or in major benchmarks such as Flores-200 or SIB-200. We focus on extending Flores-200 benchmark to these languages, and further align the translated texts with topic labels based on SIB-200 classification dataset. Our evaluation shows that current LLMs perform poorly on machine translation for these languages in both zero-and-few shot settings. However, we find the few-shot samples to steadily improve topic classification with more shots.
MERLIN: Multi-Stage Curriculum Alignment for Multilingual Encoder and LLM Fusion
Sep 09, 2025Large language models excel in English but still struggle with complex reasoning in many low-resource languages (LRLs). Existing encoder-plus-decoder methods such as LangBridge and MindMerger raise accuracy on mid and high-resource languages, yet they leave a large gap on LRLs. We present MERLIN, a two-stage model-stacking framework that applies a curriculum learning strategy -- from general bilingual bitext to task-specific data -- and adapts only a small set of DoRA weights. On the AfriMGSM benchmark MERLIN improves exact-match accuracy by +12.9 pp over MindMerger and outperforms GPT-4o-mini. It also yields consistent gains on MGSM and MSVAMP (+0.9 and +2.8 pp), demonstrating effectiveness across both low and high-resource settings.
mSTEB: Massively Multilingual Evaluation of LLMs on Speech and Text Tasks
Jun 10, 2025Large Language models (LLMs) have demonstrated impressive performance on a wide range of tasks, including in multimodal settings such as speech. However, their evaluation is often limited to English and a few high-resource languages. For low-resource languages, there is no standardized evaluation benchmark. In this paper, we address this gap by introducing mSTEB, a new benchmark to evaluate the performance of LLMs on a wide range of tasks covering language identification, text classification, question answering, and translation tasks on both speech and text modalities. We evaluated the performance of leading LLMs such as Gemini 2.0 Flash and GPT-4o (Audio) and state-of-the-art open models such as Qwen 2 Audio and Gemma 3 27B. Our evaluation shows a wide gap in performance between high-resource and low-resource languages, especially for languages spoken in Africa and Americas/Oceania. Our findings show that more investment is needed to address their under-representation in LLMs coverage.
SSA-COMET: Do LLMs Outperform Learned Metrics in Evaluating MT for Under-Resourced African Languages?
Jun 05, 2025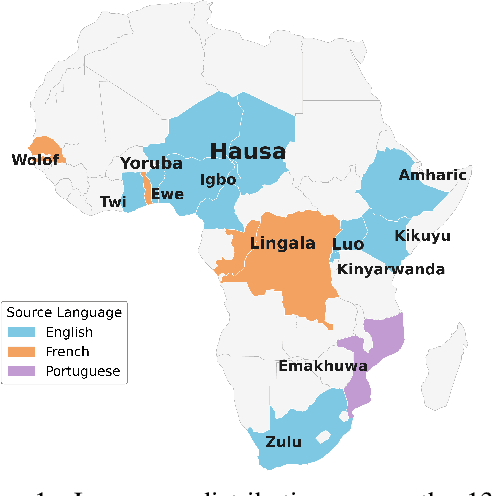
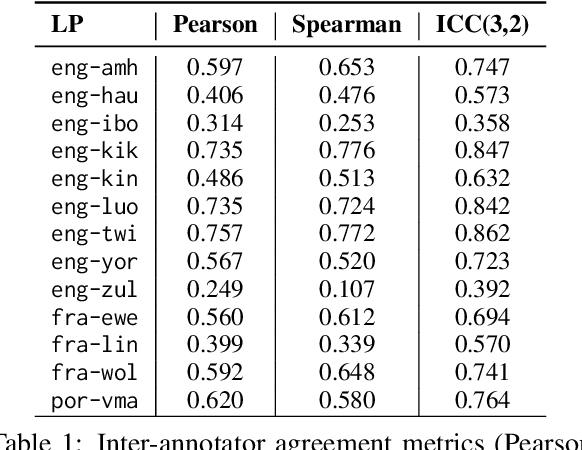
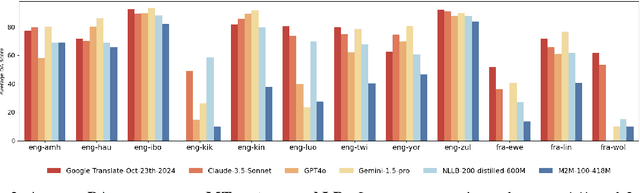
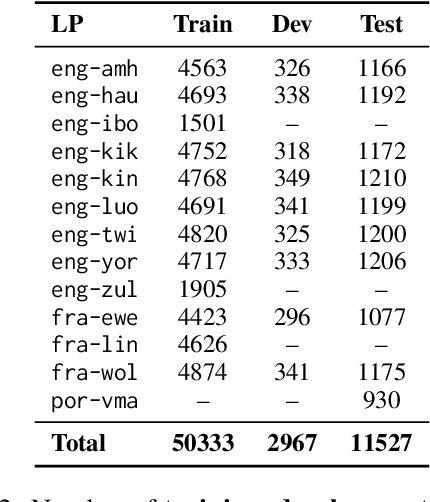
Evaluating machine translation (MT) quality for under-resourced African languages remains a significant challenge, as existing metrics often suffer from limited language coverage and poor performance in low-resource settings. While recent efforts, such as AfriCOMET, have addressed some of the issues, they are still constrained by small evaluation sets, a lack of publicly available training data tailored to African languages, and inconsistent performance in extremely low-resource scenarios. In this work, we introduce SSA-MTE, a large-scale human-annotated MT evaluation (MTE) dataset covering 13 African language pairs from the News domain, with over 63,000 sentence-level annotations from a diverse set of MT systems. Based on this data, we develop SSA-COMET and SSA-COMET-QE, improved reference-based and reference-free evaluation metrics. We also benchmark prompting-based approaches using state-of-the-art LLMs like GPT-4o and Claude. Our experimental results show that SSA-COMET models significantly outperform AfriCOMET and are competitive with the strongest LLM (Gemini 2.5 Pro) evaluated in our study, particularly on low-resource languages such as Twi, Luo, and Yoruba. All resources are released under open licenses to support future research.
Charting the Landscape of African NLP: Mapping Progress and Shaping the Road Ahead
May 28, 2025With over 2,000 languages and potentially millions of speakers, Africa represents one of the richest linguistic regions in the world. Yet, this diversity is scarcely reflected in state-of-the-art natural language processing (NLP) systems and large language models (LLMs), which predominantly support a narrow set of high-resource languages. This exclusion not only limits the reach and utility of modern NLP technologies but also risks widening the digital divide across linguistic communities. Nevertheless, NLP research on African languages is active and growing. In recent years, there has been a surge of interest in this area, driven by several factors-including the creation of multilingual language resources, the rise of community-led initiatives, and increased support through funding programs. In this survey, we analyze 734 research papers on NLP for African languages published over the past five years, offering a comprehensive overview of recent progress across core tasks. We identify key trends shaping the field and conclude by outlining promising directions to foster more inclusive and sustainable NLP research for African languages.