 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne Script Instead of Hundreds? On Pretraining Romanized Encoder Language Models
Jan 09, 2026Exposing latent lexical overlap, script romanization has emerged as an effective strategy for improving cross-lingual transfer (XLT) in multilingual language models (mLMs). Most prior work, however, focused on setups that favor romanization the most: (1) transfer from high-resource Latin-script to low-resource non-Latin-script languages and/or (2) between genealogically closely related languages with different scripts. It thus remains unclear whether romanization is a good representation choice for pretraining general-purpose mLMs, or, more precisely, if information loss associated with romanization harms performance for high-resource languages. We address this gap by pretraining encoder LMs from scratch on both romanized and original texts for six typologically diverse high-resource languages, investigating two potential sources of degradation: (i) loss of script-specific information and (ii) negative cross-lingual interference from increased vocabulary overlap. Using two romanizers with different fidelity profiles, we observe negligible performance loss for languages with segmental scripts, whereas languages with morphosyllabic scripts (Chinese and Japanese) suffer degradation that higher-fidelity romanization mitigates but cannot fully recover. Importantly, comparing monolingual LMs with their mLM counterpart, we find no evidence that increased subword overlap induces negative interference. We further show that romanization improves encoding efficiency (i.e., fertility) for segmental scripts at a negligible performance cost.
Compositional Steering of Large Language Models with Steering Tokens
Jan 08, 2026Deploying LLMs in real-world applications requires controllable output that satisfies multiple desiderata at the same time. While existing work extensively addresses LLM steering for a single behavior, \textit{compositional steering} -- i.e., steering LLMs simultaneously towards multiple behaviors -- remains an underexplored problem. In this work, we propose \emph{compositional steering tokens} for multi-behavior steering. We first embed individual behaviors, expressed as natural language instructions, into dedicated tokens via self-distillation. Contrary to most prior work, which operates in the activation space, our behavior steers live in the space of input tokens, enabling more effective zero-shot composition. We then train a dedicated \textit{composition token} on pairs of behaviors and show that it successfully captures the notion of composition: it generalizes well to \textit{unseen} compositions, including those with unseen behaviors as well as those with an unseen \textit{number} of behaviors. Our experiments across different LLM architectures show that steering tokens lead to superior multi-behavior control compared to competing approaches (instructions, activation steering, and LoRA merging). Moreover, we show that steering tokens complement natural language instructions, with their combination resulting in further gains.
TransAlign: Machine Translation Encoders are Strong Word Aligners, Too
Oct 31, 2025In the absence of sizable training data for most world languages and NLP tasks, translation-based strategies such as translate-test -- evaluating on noisy source language data translated from the target language -- and translate-train -- training on noisy target language data translated from the source language -- have been established as competitive approaches for cross-lingual transfer (XLT). For token classification tasks, these strategies require label projection: mapping the labels from each token in the original sentence to its counterpart(s) in the translation. To this end, it is common to leverage multilingual word aligners (WAs) derived from encoder language models such as mBERT or LaBSE. Despite obvious associations between machine translation (MT) and WA, research on extracting alignments with MT models is largely limited to exploiting cross-attention in encoder-decoder architectures, yielding poor WA results. In this work, in contrast, we propose TransAlign, a novel word aligner that utilizes the encoder of a massively multilingual MT model. We show that TransAlign not only achieves strong WA performance but substantially outperforms popular WA and state-of-the-art non-WA-based label projection methods in MT-based XLT for token classification.
ReCoVeR the Target Language: Language Steering without Sacrificing Task Performance
Sep 18, 2025


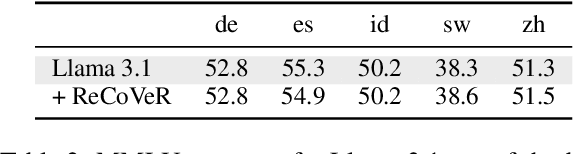
As they become increasingly multilingual, Large Language Models (LLMs) exhibit more language confusion, i.e., they tend to generate answers in a language different from the language of the prompt or the answer language explicitly requested by the user. In this work, we propose ReCoVeR (REducing language COnfusion in VEctor Representations), a novel lightweight approach for reducing language confusion based on language-specific steering vectors. We first isolate language vectors with the help of multi-parallel corpus and then effectively leverage those vectors for effective LLM steering via fixed (i.e., unsupervised) as well as trainable steering functions. Our extensive evaluation, encompassing three benchmarks and 18 languages, shows that ReCoVeR effectively mitigates language confusion in both monolingual and cross-lingual setups while at the same time -- and in contrast to prior language steering methods -- retaining task performance. Our data code is available at https://github.com/hSterz/recover.
The Devil Is in the Word Alignment Details: On Translation-Based Cross-Lingual Transfer for Token Classification Tasks
May 15, 2025Translation-based strategies for cross-lingual transfer XLT such as translate-train -- training on noisy target language data translated from the source language -- and translate-test -- evaluating on noisy source language data translated from the target language -- are competitive XLT baselines. In XLT for token classification tasks, however, these strategies include label projection, the challenging step of mapping the labels from each token in the original sentence to its counterpart(s) in the translation. Although word aligners (WAs) are commonly used for label projection, the low-level design decisions for applying them to translation-based XLT have not been systematically investigated. Moreover, recent marker-based methods, which project labeled spans by inserting tags around them before (or after) translation, claim to outperform WAs in label projection for XLT. In this work, we revisit WAs for label projection, systematically investigating the effects of low-level design decisions on token-level XLT: (i) the algorithm for projecting labels between (multi-)token spans, (ii) filtering strategies to reduce the number of noisily mapped labels, and (iii) the pre-tokenization of the translated sentences. We find that all of these substantially impact translation-based XLT performance and show that, with optimized choices, XLT with WA offers performance at least comparable to that of marker-based methods. We then introduce a new projection strategy that ensembles translate-train and translate-test predictions and demonstrate that it substantially outperforms the marker-based projection. Crucially, we show that our proposed ensembling also reduces sensitivity to low-level WA design choices, resulting in more robust XLT for token classification tasks.
On the Potential of Large Language Models to Solve Semantics-Aware Process Mining Tasks
Apr 29, 2025


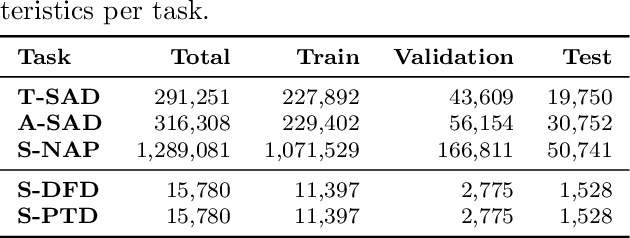
Large language models (LLMs) have shown to be valuable tools for tackling process mining tasks. Existing studies report on their capability to support various data-driven process analyses and even, to some extent, that they are able to reason about how processes work. This reasoning ability suggests that there is potential for LLMs to tackle semantics-aware process mining tasks, which are tasks that rely on an understanding of the meaning of activities and their relationships. Examples of these include process discovery, where the meaning of activities can indicate their dependency, whereas in anomaly detection the meaning can be used to recognize process behavior that is abnormal. In this paper, we systematically explore the capabilities of LLMs for such tasks. Unlike prior work, which largely evaluates LLMs in their default state, we investigate their utility through both in-context learning and supervised fine-tuning. Concretely, we define five process mining tasks requiring semantic understanding and provide extensive benchmarking datasets for evaluation. Our experiments reveal that while LLMs struggle with challenging process mining tasks when used out of the box or with minimal in-context examples, they achieve strong performance when fine-tuned for these tasks across a broad range of process types and industries.
How Much Do LLMs Hallucinate across Languages? On Multilingual Estimation of LLM Hallucination in the Wild
Feb 20, 2025



In the age of misinformation, hallucination -- the tendency of Large Language Models (LLMs) to generate non-factual or unfaithful responses -- represents the main risk for their global utility. Despite LLMs becoming increasingly multilingual, the vast majority of research on detecting and quantifying LLM hallucination are (a) English-centric and (b) focus on machine translation (MT) and summarization, tasks that are less common ``in the wild'' than open information seeking. In contrast, we aim to quantify the extent of LLM hallucination across languages in knowledge-intensive long-form question answering. To this end, we train a multilingual hallucination detection model and conduct a large-scale study across 30 languages and 6 open-source LLM families. We start from an English hallucination detection dataset and rely on MT to generate (noisy) training data in other languages. We also manually annotate gold data for five high-resource languages; we then demonstrate, for these languages, that the estimates of hallucination rates are similar between silver (LLM-generated) and gold test sets, validating the use of silver data for estimating hallucination rates for other languages. For the final rates estimation, we build a knowledge-intensive QA dataset for 30 languages with LLM-generated prompts and Wikipedia articles as references. We find that, while LLMs generate longer responses with more hallucinated tokens for higher-resource languages, there is no correlation between length-normalized hallucination rates of languages and their digital representation. Further, we find that smaller LLMs exhibit larger hallucination rates than larger models.
Don't Stop the Multi-Party! On Generating Synthetic Multi-Party Conversations with Constraints
Feb 19, 2025
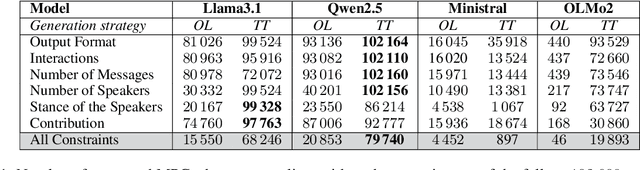
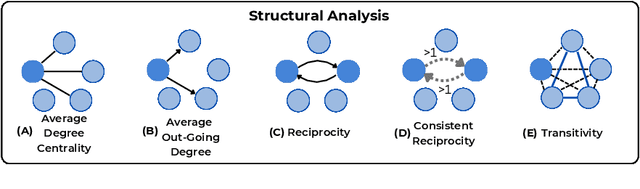
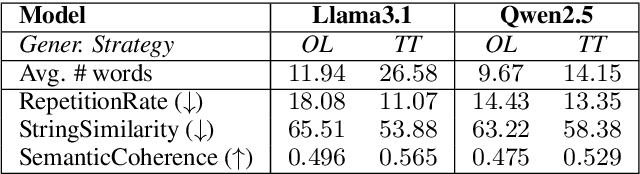
Multi-Party Conversations (MPCs) are widely studied across disciplines, with social media as a primary data source due to their accessibility. However, these datasets raise privacy concerns and often reflect platform-specific properties. For example, interactions between speakers may be limited due to rigid platform structures (e.g., threads, tree-like discussions), which yield overly simplistic interaction patterns (e.g., as a consequence of ``reply-to'' links). This work explores the feasibility of generating diverse MPCs with instruction-tuned Large Language Models (LLMs) by providing deterministic constraints such as dialogue structure and participants' stance. We investigate two complementary strategies of leveraging LLMs in this context: (i.) LLMs as MPC generators, where we task the LLM to generate a whole MPC at once and (ii.) LLMs as MPC parties, where the LLM generates one turn of the conversation at a time, provided the conversation history. We next introduce an analytical framework to evaluate compliance with the constraints, content quality, and interaction complexity for both strategies. Finally, we assess the quality of obtained MPCs via human annotation and LLM-as-a-judge evaluations. We find stark differences among LLMs, with only some being able to generate high-quality MPCs. We also find that turn-by-turn generation yields better conformance to constraints and higher linguistic variability than generating MPCs in one pass. Nonetheless, our structural and qualitative evaluation indicates that both generation strategies can yield high-quality MPCs.
MVL-SIB: A Massively Multilingual Vision-Language Benchmark for Cross-Modal Topical Matching
Feb 18, 2025



Existing multilingual vision-language (VL) benchmarks often only cover a handful of languages. Consequently, evaluations of large vision-language models (LVLMs) predominantly target high-resource languages, underscoring the need for evaluation data for low-resource languages. To address this limitation, we introduce MVL-SIB, a massively multilingual vision-language benchmark that evaluates both cross-modal and text-only topical matching across 205 languages -- over 100 more than the most multilingual existing VL benchmarks encompass. We then benchmark a range of of open-weight LVLMs together with GPT-4o(-mini) on MVL-SIB. Our results reveal that LVLMs struggle in cross-modal topic matching in lower-resource languages, performing no better than chance on languages like N'Koo. Our analysis further reveals that VL support in LVLMs declines disproportionately relative to textual support for lower-resource languages, as evidenced by comparison of cross-modal and text-only topical matching performance. We further observe that open-weight LVLMs do not benefit from representing a topic with more than one image, suggesting that these models are not yet fully effective at handling multi-image tasks. By correlating performance on MVL-SIB with other multilingual VL benchmarks, we highlight that MVL-SIB serves as a comprehensive probe of multilingual VL understanding in LVLMs.
Fleurs-SLU: A Massively Multilingual Benchmark for Spoken Language Understanding
Jan 10, 2025While recent multilingual automatic speech recognition models claim to support thousands of languages, ASR for low-resource languages remains highly unreliable due to limited bimodal speech and text training data. Better multilingual spoken language understanding (SLU) can strengthen massively the robustness of multilingual ASR by levering language semantics to compensate for scarce training data, such as disambiguating utterances via context or exploiting semantic similarities across languages. Even more so, SLU is indispensable for inclusive speech technology in roughly half of all living languages that lack a formal writing system. However, the evaluation of multilingual SLU remains limited to shallower tasks such as intent classification or language identification. To address this, we present Fleurs-SLU, a multilingual SLU benchmark that encompasses topical speech classification in 102 languages and multiple-choice question answering through listening comprehension in 92 languages. We extensively evaluate both end-to-end speech classification models and cascaded systems that combine speech-to-text transcription with subsequent classification by large language models on Fleurs-SLU. Our results show that cascaded systems exhibit greater robustness in multilingual SLU tasks, though speech encoders can achieve competitive performance in topical speech classification when appropriately pre-trained. We further find a strong correlation between robust multilingual ASR, effective speech-to-text translation, and strong multilingual SLU, highlighting the mutual benefits between acoustic and semantic speech representations.