 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDon't Stop the Multi-Party! On Generating Synthetic Multi-Party Conversations with Constraints
Paper and Code

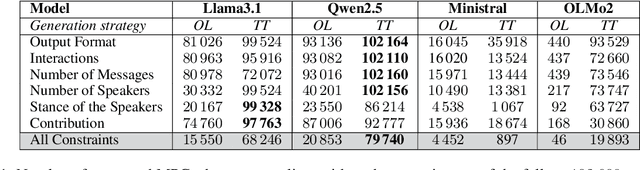
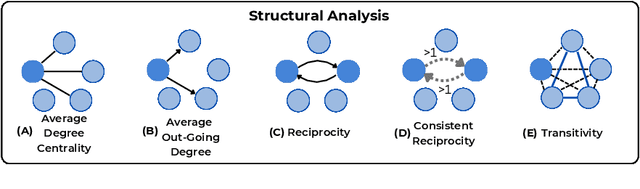
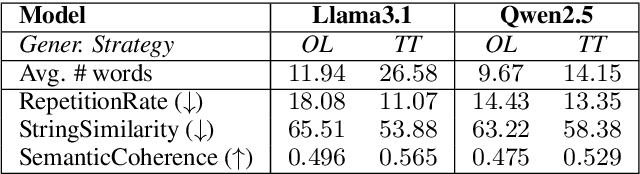
Multi-Party Conversations (MPCs) are widely studied across disciplines, with social media as a primary data source due to their accessibility. However, these datasets raise privacy concerns and often reflect platform-specific properties. For example, interactions between speakers may be limited due to rigid platform structures (e.g., threads, tree-like discussions), which yield overly simplistic interaction patterns (e.g., as a consequence of ``reply-to'' links). This work explores the feasibility of generating diverse MPCs with instruction-tuned Large Language Models (LLMs) by providing deterministic constraints such as dialogue structure and participants' stance. We investigate two complementary strategies of leveraging LLMs in this context: (i.) LLMs as MPC generators, where we task the LLM to generate a whole MPC at once and (ii.) LLMs as MPC parties, where the LLM generates one turn of the conversation at a time, provided the conversation history. We next introduce an analytical framework to evaluate compliance with the constraints, content quality, and interaction complexity for both strategies. Finally, we assess the quality of obtained MPCs via human annotation and LLM-as-a-judge evaluations. We find stark differences among LLMs, with only some being able to generate high-quality MPCs. We also find that turn-by-turn generation yields better conformance to constraints and higher linguistic variability than generating MPCs in one pass. Nonetheless, our structural and qualitative evaluation indicates that both generation strategies can yield high-quality MPCs.