 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWith a Little Help From My Friends: Collective Manipulation in Risk-Controlling Recommender Systems
Mar 30, 2026Recommendation systems have become central gatekeepers of online information, shaping user behaviour across a wide range of activities. In response, users increasingly organize and coordinate to steer algorithmic outcomes toward diverse goals, such as promoting relevant content or limiting harmful material, relying on platform affordances -- such as likes, reviews, or ratings. While these mechanisms can serve beneficial purposes, they can also be leveraged for adversarial manipulation, particularly in systems where such feedback directly informs safety guarantees. In this paper, we study this vulnerability in recently proposed risk-controlling recommender systems, which use binary user feedback (e.g., "Not Interested") to provably limit exposure to unwanted content via conformal risk control. We empirically demonstrate that their reliance on aggregate feedback signals makes them inherently susceptible to coordinated adversarial user behaviour. Using data from a large-scale online video-sharing platform, we show that a small coordinated group (comprising only 1% of the user population) can induce up to a 20% degradation in nDCG for non-adversarial users by exploiting the affordances provided by risk-controlling recommender systems. We evaluate simple, realistic attack strategies that require little to no knowledge of the underlying recommendation algorithm and find that, while coordinated users can significantly harm overall recommendation quality, they cannot selectively suppress specific content groups through reporting alone. Finally, we propose a mitigation strategy that shifts guarantees from the group level to the user level, showing empirically how it can reduce the impact of adversarial coordinated behaviour while ensuring personalized safety for individuals.
SokoBench: Evaluating Long-Horizon Planning and Reasoning in Large Language Models
Jan 28, 2026Although the capabilities of large language models have been increasingly tested on complex reasoning tasks, their long-horizon planning abilities have not yet been extensively investigated. In this work, we provide a systematic assessment of the planning and long-horizon reasoning capabilities of state-of-the-art Large Reasoning Models (LRMs). We propose a novel benchmark based on Sokoban puzzles, intentionally simplified to isolate long-horizon planning from state persistence. Our findings reveal a consistent degradation in planning performance when more than 25 moves are required to reach the solution, suggesting a fundamental constraint on forward planning capacity. We show that equipping LRMs with Planning Domain Definition Language (PDDL) parsing, validation, and solving tools allows for modest improvements, suggesting inherent architectural limitations which might not be overcome by test-time scaling approaches alone.
GNN Explanations that do not Explain and How to find Them
Jan 28, 2026Explanations provided by Self-explainable Graph Neural Networks (SE-GNNs) are fundamental for understanding the model's inner workings and for identifying potential misuse of sensitive attributes. Although recent works have highlighted that these explanations can be suboptimal and potentially misleading, a characterization of their failure cases is unavailable. In this work, we identify a critical failure of SE-GNN explanations: explanations can be unambiguously unrelated to how the SE-GNNs infer labels. We show that, on the one hand, many SE-GNNs can achieve optimal true risk while producing these degenerate explanations, and on the other, most faithfulness metrics can fail to identify these failure modes. Our empirical analysis reveals that degenerate explanations can be maliciously planted (allowing an attacker to hide the use of sensitive attributes) and can also emerge naturally, highlighting the need for reliable auditing. To address this, we introduce a novel faithfulness metric that reliably marks degenerate explanations as unfaithful, in both malicious and natural settings. Our code is available in the supplemental.
POCI-Diff: Position Objects Consistently and Interactively with 3D-Layout Guided Diffusion
Jan 20, 2026We propose a diffusion-based approach for Text-to-Image (T2I) generation with consistent and interactive 3D layout control and editing. While prior methods improve spatial adherence using 2D cues or iterative copy-warp-paste strategies, they often distort object geometry and fail to preserve consistency across edits. To address these limitations, we introduce a framework for Positioning Objects Consistently and Interactively (POCI-Diff), a novel formulation for jointly enforcing 3D geometric constraints and instance-level semantic binding within a unified diffusion process. Our method enables explicit per-object semantic control by binding individual text descriptions to specific 3D bounding boxes through Blended Latent Diffusion, allowing one-shot synthesis of complex multi-object scenes. We further propose a warping-free generative editing pipeline that supports object insertion, removal, and transformation via regeneration rather than pixel deformation. To preserve object identity and consistency across edits, we condition the diffusion process on reference images using IP-Adapter, enabling coherent object appearance throughout interactive 3D editing while maintaining global scene coherence. Experimental results demonstrate that POCI-Diff produces high-quality images consistent with the specified 3D layouts and edits, outperforming state-of-the-art methods in both visual fidelity and layout adherence while eliminating warping-induced geometric artifacts.
Generative AI collective behavior needs an interactionist paradigm
Jan 15, 2026In this article, we argue that understanding the collective behavior of agents based on large language models (LLMs) is an essential area of inquiry, with important implications in terms of risks and benefits, impacting us as a society at many levels. We claim that the distinctive nature of LLMs--namely, their initialization with extensive pre-trained knowledge and implicit social priors, together with their capability of adaptation through in-context learning--motivates the need for an interactionist paradigm consisting of alternative theoretical foundations, methodologies, and analytical tools, in order to systematically examine how prior knowledge and embedded values interact with social context to shape emergent phenomena in multi-agent generative AI systems. We propose and discuss four directions that we consider crucial for the development and deployment of LLM-based collectives, focusing on theory, methods, and trans-disciplinary dialogue.
Rethinking GNNs and Missing Features: Challenges, Evaluation and a Robust Solution
Jan 08, 2026Handling missing node features is a key challenge for deploying Graph Neural Networks (GNNs) in real-world domains such as healthcare and sensor networks. Existing studies mostly address relatively benign scenarios, namely benchmark datasets with (a) high-dimensional but sparse node features and (b) incomplete data generated under Missing Completely At Random (MCAR) mechanisms. For (a), we theoretically prove that high sparsity substantially limits the information loss caused by missingness, making all models appear robust and preventing a meaningful comparison of their performance. To overcome this limitation, we introduce one synthetic and three real-world datasets with dense, semantically meaningful features. For (b), we move beyond MCAR and design evaluation protocols with more realistic missingness mechanisms. Moreover, we provide a theoretical background to state explicit assumptions on the missingness process and analyze their implications for different methods. Building on this analysis, we propose GNNmim, a simple yet effective baseline for node classification with incomplete feature data. Experiments show that GNNmim is competitive with respect to specialized architectures across diverse datasets and missingness regimes.
LLMberjack: Guided Trimming of Debate Trees for Multi-Party Conversation Creation
Jan 07, 2026We present LLMberjack, a platform for creating multi-party conversations starting from existing debates, originally structured as reply trees. The system offers an interactive interface that visualizes discussion trees and enables users to construct coherent linearized dialogue sequences while preserving participant identity and discourse relations. It integrates optional large language model (LLM) assistance to support automatic editing of the messages and speakers' descriptions. We demonstrate the platform's utility by showing how tree visualization facilitates the creation of coherent, meaningful conversation threads and how LLM support enhances output quality while reducing human effort. The tool is open-source and designed to promote transparent and reproducible workflows to create multi-party conversations, addressing a lack of resources of this type.
Organ-Agents: Virtual Human Physiology Simulator via LLMs
Aug 20, 2025Recent advances in large language models (LLMs) have enabled new possibilities in simulating complex physiological systems. We introduce Organ-Agents, a multi-agent framework that simulates human physiology via LLM-driven agents. Each Simulator models a specific system (e.g., cardiovascular, renal, immune). Training consists of supervised fine-tuning on system-specific time-series data, followed by reinforcement-guided coordination using dynamic reference selection and error correction. We curated data from 7,134 sepsis patients and 7,895 controls, generating high-resolution trajectories across 9 systems and 125 variables. Organ-Agents achieved high simulation accuracy on 4,509 held-out patients, with per-system MSEs <0.16 and robustness across SOFA-based severity strata. External validation on 22,689 ICU patients from two hospitals showed moderate degradation under distribution shifts with stable simulation. Organ-Agents faithfully reproduces critical multi-system events (e.g., hypotension, hyperlactatemia, hypoxemia) with coherent timing and phase progression. Evaluation by 15 critical care physicians confirmed realism and physiological plausibility (mean Likert ratings 3.9 and 3.7). Organ-Agents also enables counterfactual simulations under alternative sepsis treatment strategies, generating trajectories and APACHE II scores aligned with matched real-world patients. In downstream early warning tasks, classifiers trained on synthetic data showed minimal AUROC drops (<0.04), indicating preserved decision-relevant patterns. These results position Organ-Agents as a credible, interpretable, and generalizable digital twin for precision diagnosis, treatment simulation, and hypothesis testing in critical care.
Time Series Foundation Models are Flow Predictors
Jul 01, 2025
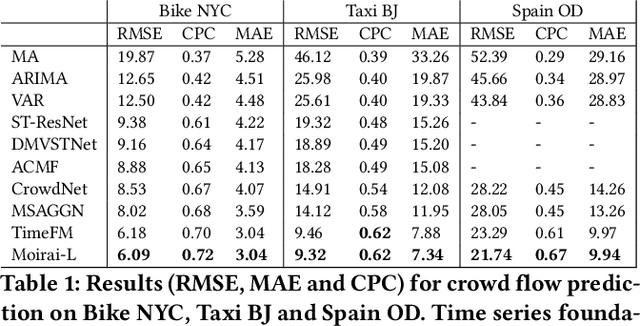
We investigate the effectiveness of time series foundation models (TSFMs) for crowd flow prediction, focusing on Moirai and TimesFM. Evaluated on three real-world mobility datasets-Bike NYC, Taxi Beijing, and Spanish national OD flows-these models are deployed in a strict zero-shot setting, using only the temporal evolution of each OD flow and no explicit spatial information. Moirai and TimesFM outperform both statistical and deep learning baselines, achieving up to 33% lower RMSE, 39% lower MAE and up to 49% higher CPC compared to state-of-the-art competitors. Our results highlight the practical value of TSFMs for accurate, scalable flow prediction, even in scenarios with limited annotated data or missing spatial context.
FreeInsert: Disentangled Text-Guided Object Insertion in 3D Gaussian Scene without Spatial Priors
May 02, 2025Text-driven object insertion in 3D scenes is an emerging task that enables intuitive scene editing through natural language. However, existing 2D editing-based methods often rely on spatial priors such as 2D masks or 3D bounding boxes, and they struggle to ensure consistency of the inserted object. These limitations hinder flexibility and scalability in real-world applications. In this paper, we propose FreeInsert, a novel framework that leverages foundation models including MLLMs, LGMs, and diffusion models to disentangle object generation from spatial placement. This enables unsupervised and flexible object insertion in 3D scenes without spatial priors. FreeInsert starts with an MLLM-based parser that extracts structured semantics, including object types, spatial relationships, and attachment regions, from user instructions. These semantics guide both the reconstruction of the inserted object for 3D consistency and the learning of its degrees of freedom. We leverage the spatial reasoning capabilities of MLLMs to initialize object pose and scale. A hierarchical, spatially aware refinement stage further integrates spatial semantics and MLLM-inferred priors to enhance placement. Finally, the appearance of the object is improved using the inserted-object image to enhance visual fidelity. Experimental results demonstrate that FreeInsert achieves semantically coherent, spatially precise, and visually realistic 3D insertions without relying on spatial priors, offering a user-friendly and flexible editing experience.