 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOctoBench: Benchmarking Scaffold-Aware Instruction Following in Repository-Grounded Agentic Coding
Jan 16, 2026Modern coding scaffolds turn LLMs into capable software agents, but their ability to follow scaffold-specified instructions remains under-examined, especially when constraints are heterogeneous and persist across interactions. To fill this gap, we introduce OctoBench, which benchmarks scaffold-aware instruction following in repository-grounded agentic coding. OctoBench includes 34 environments and 217 tasks instantiated under three scaffold types, and is paired with 7,098 objective checklist items. To disentangle solving the task from following the rules, we provide an automated observation-and-scoring toolkit that captures full trajectories and performs fine-grained checks. Experiments on eight representative models reveal a systematic gap between task-solving and scaffold-aware compliance, underscoring the need for training and evaluation that explicitly targets heterogeneous instruction following. We release the benchmark to support reproducible benchmarking and to accelerate the development of more scaffold-aware coding agents.
ABC-Bench: Benchmarking Agentic Backend Coding in Real-World Development
Jan 16, 2026The evolution of Large Language Models (LLMs) into autonomous agents has expanded the scope of AI coding from localized code generation to complex, repository-level, and execution-driven problem solving. However, current benchmarks predominantly evaluate code logic in static contexts, neglecting the dynamic, full-process requirements of real-world engineering, particularly in backend development which demands rigorous environment configuration and service deployment. To address this gap, we introduce ABC-Bench, a benchmark explicitly designed to evaluate agentic backend coding within a realistic, executable workflow. Using a scalable automated pipeline, we curated 224 practical tasks spanning 8 languages and 19 frameworks from open-source repositories. Distinct from previous evaluations, ABC-Bench require the agents to manage the entire development lifecycle from repository exploration to instantiating containerized services and pass the external end-to-end API tests. Our extensive evaluation reveals that even state-of-the-art models struggle to deliver reliable performance on these holistic tasks, highlighting a substantial disparity between current model capabilities and the demands of practical backend engineering. Our code is available at https://github.com/OpenMOSS/ABC-Bench.
Memory in the Age of AI Agents
Dec 15, 2025Memory has emerged, and will continue to remain, a core capability of foundation model-based agents. As research on agent memory rapidly expands and attracts unprecedented attention, the field has also become increasingly fragmented. Existing works that fall under the umbrella of agent memory often differ substantially in their motivations, implementations, and evaluation protocols, while the proliferation of loosely defined memory terminologies has further obscured conceptual clarity. Traditional taxonomies such as long/short-term memory have proven insufficient to capture the diversity of contemporary agent memory systems. This work aims to provide an up-to-date landscape of current agent memory research. We begin by clearly delineating the scope of agent memory and distinguishing it from related concepts such as LLM memory, retrieval augmented generation (RAG), and context engineering. We then examine agent memory through the unified lenses of forms, functions, and dynamics. From the perspective of forms, we identify three dominant realizations of agent memory, namely token-level, parametric, and latent memory. From the perspective of functions, we propose a finer-grained taxonomy that distinguishes factual, experiential, and working memory. From the perspective of dynamics, we analyze how memory is formed, evolved, and retrieved over time. To support practical development, we compile a comprehensive summary of memory benchmarks and open-source frameworks. Beyond consolidation, we articulate a forward-looking perspective on emerging research frontiers, including memory automation, reinforcement learning integration, multimodal memory, multi-agent memory, and trustworthiness issues. We hope this survey serves not only as a reference for existing work, but also as a conceptual foundation for rethinking memory as a first-class primitive in the design of future agentic intelligence.
AgentGym-RL: Training LLM Agents for Long-Horizon Decision Making through Multi-Turn Reinforcement Learning
Sep 10, 2025Developing autonomous LLM agents capable of making a series of intelligent decisions to solve complex, real-world tasks is a fast-evolving frontier. Like human cognitive development, agents are expected to acquire knowledge and skills through exploration and interaction with the environment. Despite advances, the community still lacks a unified, interactive reinforcement learning (RL) framework that can effectively train such agents from scratch -- without relying on supervised fine-tuning (SFT) -- across diverse and realistic environments. To bridge this gap, we introduce AgentGym-RL, a new framework to train LLM agents for multi-turn interactive decision-making through RL. The framework features a modular and decoupled architecture, ensuring high flexibility and extensibility. It encompasses a wide variety of real-world scenarios, and supports mainstream RL algorithms. Furthermore, we propose ScalingInter-RL, a training approach designed for exploration-exploitation balance and stable RL optimization. In early stages, it emphasizes exploitation by restricting the number of interactions, and gradually shifts towards exploration with larger horizons to encourage diverse problem-solving strategies. In this way, the agent develops more diverse behaviors and is less prone to collapse under long horizons. We perform extensive experiments to validate the stability and effectiveness of both the AgentGym-RL framework and the ScalingInter-RL approach. Our agents match or surpass commercial models on 27 tasks across diverse environments. We offer key insights and will open-source the complete AgentGym-RL framework -- including code and datasets -- to empower the research community in developing the next generation of intelligent agents.
Organ-Agents: Virtual Human Physiology Simulator via LLMs
Aug 20, 2025Recent advances in large language models (LLMs) have enabled new possibilities in simulating complex physiological systems. We introduce Organ-Agents, a multi-agent framework that simulates human physiology via LLM-driven agents. Each Simulator models a specific system (e.g., cardiovascular, renal, immune). Training consists of supervised fine-tuning on system-specific time-series data, followed by reinforcement-guided coordination using dynamic reference selection and error correction. We curated data from 7,134 sepsis patients and 7,895 controls, generating high-resolution trajectories across 9 systems and 125 variables. Organ-Agents achieved high simulation accuracy on 4,509 held-out patients, with per-system MSEs <0.16 and robustness across SOFA-based severity strata. External validation on 22,689 ICU patients from two hospitals showed moderate degradation under distribution shifts with stable simulation. Organ-Agents faithfully reproduces critical multi-system events (e.g., hypotension, hyperlactatemia, hypoxemia) with coherent timing and phase progression. Evaluation by 15 critical care physicians confirmed realism and physiological plausibility (mean Likert ratings 3.9 and 3.7). Organ-Agents also enables counterfactual simulations under alternative sepsis treatment strategies, generating trajectories and APACHE II scores aligned with matched real-world patients. In downstream early warning tasks, classifiers trained on synthetic data showed minimal AUROC drops (<0.04), indicating preserved decision-relevant patterns. These results position Organ-Agents as a credible, interpretable, and generalizable digital twin for precision diagnosis, treatment simulation, and hypothesis testing in critical care.
TRCE: Towards Reliable Malicious Concept Erasure in Text-to-Image Diffusion Models
Mar 10, 2025Recent advances in text-to-image diffusion models enable photorealistic image generation, but they also risk producing malicious content, such as NSFW images. To mitigate risk, concept erasure methods are studied to facilitate the model to unlearn specific concepts. However, current studies struggle to fully erase malicious concepts implicitly embedded in prompts (e.g., metaphorical expressions or adversarial prompts) while preserving the model's normal generation capability. To address this challenge, our study proposes TRCE, using a two-stage concept erasure strategy to achieve an effective trade-off between reliable erasure and knowledge preservation. Firstly, TRCE starts by erasing the malicious semantics implicitly embedded in textual prompts. By identifying a critical mapping objective(i.e., the [EoT] embedding), we optimize the cross-attention layers to map malicious prompts to contextually similar prompts but with safe concepts. This step prevents the model from being overly influenced by malicious semantics during the denoising process. Following this, considering the deterministic properties of the sampling trajectory of the diffusion model, TRCE further steers the early denoising prediction toward the safe direction and away from the unsafe one through contrastive learning, thus further avoiding the generation of malicious content. Finally, we conduct comprehensive evaluations of TRCE on multiple malicious concept erasure benchmarks, and the results demonstrate its effectiveness in erasing malicious concepts while better preserving the model's original generation ability. The code is available at: http://github.com/ddgoodgood/TRCE. CAUTION: This paper includes model-generated content that may contain offensive material.
Better Process Supervision with Bi-directional Rewarding Signals
Mar 06, 2025Process supervision, i.e., evaluating each step, is critical for complex large language model (LLM) reasoning and test-time searching with increased inference compute. Existing approaches, represented by process reward models (PRMs), primarily focus on rewarding signals up to the current step, exhibiting a one-directional nature and lacking a mechanism to model the distance to the final target. To address this problem, we draw inspiration from the A* algorithm, which states that an effective supervisory signal should simultaneously consider the incurred cost and the estimated cost for reaching the target. Building on this key insight, we introduce BiRM, a novel process supervision model that not only evaluates the correctness of previous steps but also models the probability of future success. We conduct extensive experiments on mathematical reasoning tasks and demonstrate that BiRM provides more precise evaluations of LLM reasoning steps, achieving an improvement of 3.1% on Gaokao2023 over PRM under the Best-of-N sampling method. Besides, in search-based strategies, BiRM provides more comprehensive guidance and outperforms ORM by 5.0% and PRM by 3.8% respectively on MATH-500.
CritiQ: Mining Data Quality Criteria from Human Preferences
Feb 26, 2025Language model heavily depends on high-quality data for optimal performance. Existing approaches rely on manually designed heuristics, the perplexity of existing models, training classifiers, or careful prompt engineering, which require significant expert experience and human annotation effort while introduce biases. We introduce CritiQ, a novel data selection method that automatically mines criteria from human preferences for data quality with only $\sim$30 human-annotated pairs and performs efficient data selection. The main component, CritiQ Flow, employs a manager agent to evolve quality criteria and worker agents to make pairwise judgments. We build a knowledge base that extracts quality criteria from previous work to boost CritiQ Flow. Compared to perplexity- and classifier- based methods, verbal criteria are more interpretable and possess reusable value. After deriving the criteria, we train the CritiQ Scorer to give quality scores and perform efficient data selection. We demonstrate the effectiveness of our method in the code, math, and logic domains, achieving high accuracy on human-annotated test sets. To validate the quality of the selected data, we continually train Llama 3.1 models and observe improved performance on downstream tasks compared to uniform sampling. Ablation studies validate the benefits of the knowledge base and the reflection process. We analyze how criteria evolve and the effectiveness of majority voting.
AgentGym: Evolving Large Language Model-based Agents across Diverse Environments
Jun 06, 2024



Building generalist agents that can handle diverse tasks and evolve themselves across different environments is a long-term goal in the AI community. Large language models (LLMs) are considered a promising foundation to build such agents due to their generalized capabilities. Current approaches either have LLM-based agents imitate expert-provided trajectories step-by-step, requiring human supervision, which is hard to scale and limits environmental exploration; or they let agents explore and learn in isolated environments, resulting in specialist agents with limited generalization. In this paper, we take the first step towards building generally-capable LLM-based agents with self-evolution ability. We identify a trinity of ingredients: 1) diverse environments for agent exploration and learning, 2) a trajectory set to equip agents with basic capabilities and prior knowledge, and 3) an effective and scalable evolution method. We propose AgentGym, a new framework featuring a variety of environments and tasks for broad, real-time, uni-format, and concurrent agent exploration. AgentGym also includes a database with expanded instructions, a benchmark suite, and high-quality trajectories across environments. Next, we propose a novel method, AgentEvol, to investigate the potential of agent self-evolution beyond previously seen data across tasks and environments. Experimental results show that the evolved agents can achieve results comparable to SOTA models. We release the AgentGym suite, including the platform, dataset, benchmark, checkpoints, and algorithm implementations. The AgentGym suite is available on https://github.com/WooooDyy/AgentGym.
Code Needs Comments: Enhancing Code LLMs with Comment Augmentation
Feb 20, 2024


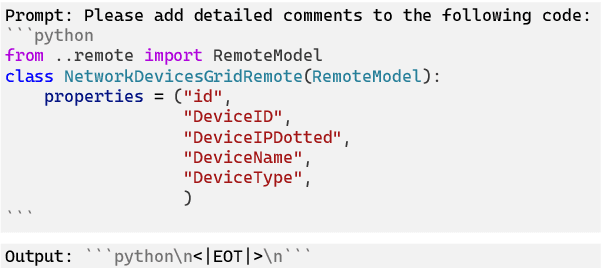
The programming skill is one crucial ability for Large Language Models (LLMs), necessitating a deep understanding of programming languages (PLs) and their correlation with natural languages (NLs). We examine the impact of pre-training data on code-focused LLMs' performance by assessing the comment density as a measure of PL-NL alignment. Given the scarcity of code-comment aligned data in pre-training corpora, we introduce a novel data augmentation method that generates comments for existing code, coupled with a data filtering strategy that filters out code data poorly correlated with natural language. We conducted experiments on three code-focused LLMs and observed consistent improvements in performance on two widely-used programming skill benchmarks. Notably, the model trained on the augmented data outperformed both the model used for generating comments and the model further trained on the data without augmentation.