 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocate, Steer, and Improve: A Practical Survey of Actionable Mechanistic Interpretability in Large Language Models
Jan 20, 2026Mechanistic Interpretability (MI) has emerged as a vital approach to demystify the opaque decision-making of Large Language Models (LLMs). However, existing reviews primarily treat MI as an observational science, summarizing analytical insights while lacking a systematic framework for actionable intervention. To bridge this gap, we present a practical survey structured around the pipeline: "Locate, Steer, and Improve." We formally categorize Localizing (diagnosis) and Steering (intervention) methods based on specific Interpretable Objects to establish a rigorous intervention protocol. Furthermore, we demonstrate how this framework enables tangible improvements in Alignment, Capability, and Efficiency, effectively operationalizing MI as an actionable methodology for model optimization. The curated paper list of this work is available at https://github.com/rattlesnakey/Awesome-Actionable-MI-Survey.
Memory in the Age of AI Agents
Dec 15, 2025Memory has emerged, and will continue to remain, a core capability of foundation model-based agents. As research on agent memory rapidly expands and attracts unprecedented attention, the field has also become increasingly fragmented. Existing works that fall under the umbrella of agent memory often differ substantially in their motivations, implementations, and evaluation protocols, while the proliferation of loosely defined memory terminologies has further obscured conceptual clarity. Traditional taxonomies such as long/short-term memory have proven insufficient to capture the diversity of contemporary agent memory systems. This work aims to provide an up-to-date landscape of current agent memory research. We begin by clearly delineating the scope of agent memory and distinguishing it from related concepts such as LLM memory, retrieval augmented generation (RAG), and context engineering. We then examine agent memory through the unified lenses of forms, functions, and dynamics. From the perspective of forms, we identify three dominant realizations of agent memory, namely token-level, parametric, and latent memory. From the perspective of functions, we propose a finer-grained taxonomy that distinguishes factual, experiential, and working memory. From the perspective of dynamics, we analyze how memory is formed, evolved, and retrieved over time. To support practical development, we compile a comprehensive summary of memory benchmarks and open-source frameworks. Beyond consolidation, we articulate a forward-looking perspective on emerging research frontiers, including memory automation, reinforcement learning integration, multimodal memory, multi-agent memory, and trustworthiness issues. We hope this survey serves not only as a reference for existing work, but also as a conceptual foundation for rethinking memory as a first-class primitive in the design of future agentic intelligence.
AgentPRM: Process Reward Models for LLM Agents via Step-Wise Promise and Progress
Nov 11, 2025Despite rapid development, large language models (LLMs) still encounter challenges in multi-turn decision-making tasks (i.e., agent tasks) like web shopping and browser navigation, which require making a sequence of intelligent decisions based on environmental feedback. Previous work for LLM agents typically relies on elaborate prompt engineering or fine-tuning with expert trajectories to improve performance. In this work, we take a different perspective: we explore constructing process reward models (PRMs) to evaluate each decision and guide the agent's decision-making process. Unlike LLM reasoning, where each step is scored based on correctness, actions in agent tasks do not have a clear-cut correctness. Instead, they should be evaluated based on their proximity to the goal and the progress they have made. Building on this insight, we propose a re-defined PRM for agent tasks, named AgentPRM, to capture both the interdependence between sequential decisions and their contribution to the final goal. This enables better progress tracking and exploration-exploitation balance. To scalably obtain labeled data for training AgentPRM, we employ a Temporal Difference-based (TD-based) estimation method combined with Generalized Advantage Estimation (GAE), which proves more sample-efficient than prior methods. Extensive experiments across different agentic tasks show that AgentPRM is over $8\times$ more compute-efficient than baselines, and it demonstrates robust improvement when scaling up test-time compute. Moreover, we perform detailed analyses to show how our method works and offer more insights, e.g., applying AgentPRM to the reinforcement learning of LLM agents.
Speech-Language Models with Decoupled Tokenizers and Multi-Token Prediction
Jun 14, 2025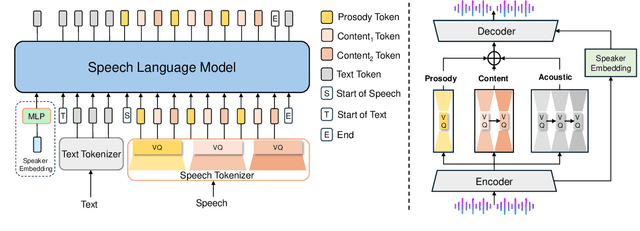
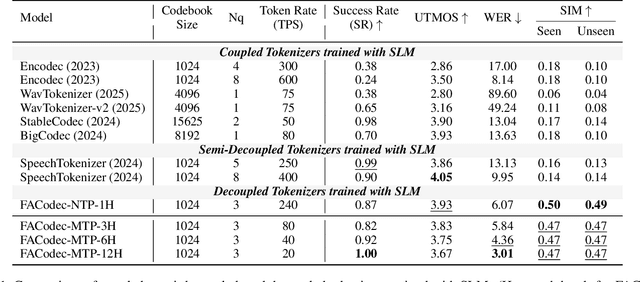
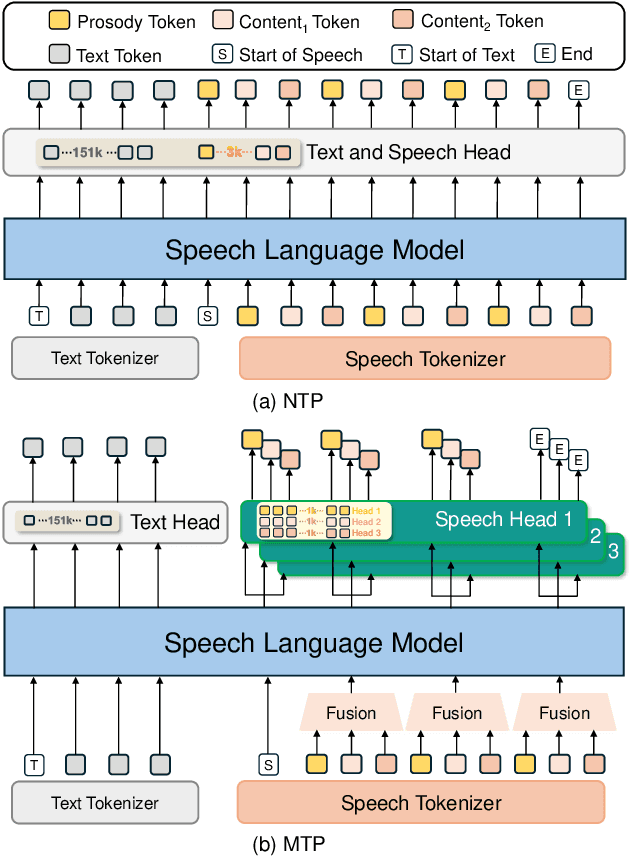
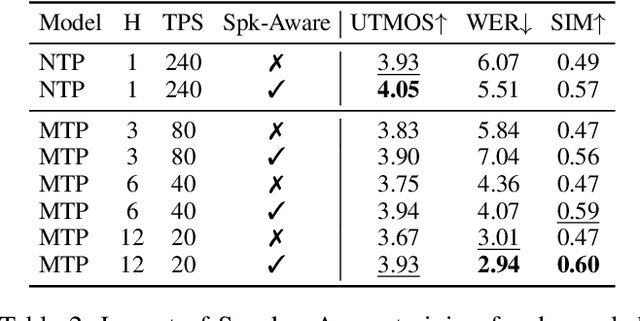
Speech-language models (SLMs) offer a promising path toward unifying speech and text understanding and generation. However, challenges remain in achieving effective cross-modal alignment and high-quality speech generation. In this work, we systematically investigate the impact of key components (i.e., speech tokenizers, speech heads, and speaker modeling) on the performance of LLM-centric SLMs. We compare coupled, semi-decoupled, and fully decoupled speech tokenizers under a fair SLM framework and find that decoupled tokenization significantly improves alignment and synthesis quality. To address the information density mismatch between speech and text, we introduce multi-token prediction (MTP) into SLMs, enabling each hidden state to decode multiple speech tokens. This leads to up to 12$\times$ faster decoding and a substantial drop in word error rate (from 6.07 to 3.01). Furthermore, we propose a speaker-aware generation paradigm and introduce RoleTriviaQA, a large-scale role-playing knowledge QA benchmark with diverse speaker identities. Experiments demonstrate that our methods enhance both knowledge understanding and speaker consistency.
EliteKV: Scalable KV Cache Compression via RoPE Frequency Selection and Joint Low-Rank Projection
Mar 03, 2025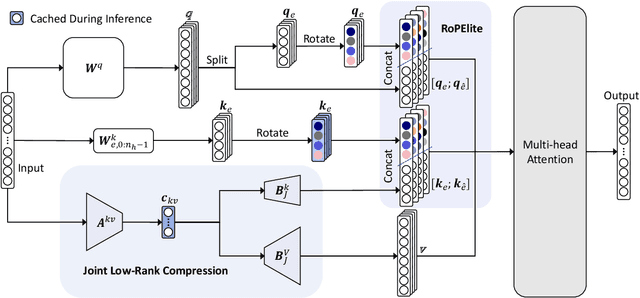
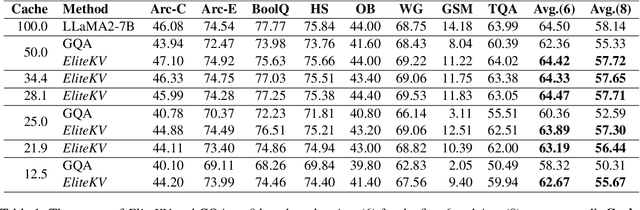


Rotary Position Embedding (RoPE) enables each attention head to capture multi-frequency information along the sequence dimension and is widely applied in foundation models. However, the nonlinearity introduced by RoPE complicates optimization of the key state in the Key-Value (KV) cache for RoPE-based attention. Existing KV cache compression methods typically store key state before rotation and apply the transformation during decoding, introducing additional computational overhead. This paper introduces EliteKV, a flexible modification framework for RoPE-based models supporting variable KV cache compression ratios. EliteKV first identifies the intrinsic frequency preference of each head using RoPElite, selectively restoring linearity to certain dimensions of key within attention computation. Building on this, joint low-rank compression of key and value enables partial cache sharing. Experimental results show that with minimal uptraining on only $0.6\%$ of the original training data, RoPE-based models achieve a $75\%$ reduction in KV cache size while preserving performance within a negligible margin. Furthermore, EliteKV consistently performs well across models of different scales within the same family.
SPA-VL: A Comprehensive Safety Preference Alignment Dataset for Vision Language Model
Jun 17, 2024



The emergence of Vision Language Models (VLMs) has brought unprecedented advances in understanding multimodal information. The combination of textual and visual semantics in VLMs is highly complex and diverse, making the safety alignment of these models challenging. Furthermore, due to the limited study on the safety alignment of VLMs, there is a lack of large-scale, high-quality datasets. To address these limitations, we propose a Safety Preference Alignment dataset for Vision Language Models named SPA-VL. In terms of breadth, SPA-VL covers 6 harmfulness domains, 13 categories, and 53 subcategories, and contains 100,788 samples of the quadruple (question, image, chosen response, rejected response). In terms of depth, the responses are collected from 12 open- (e.g., QwenVL) and closed-source (e.g., Gemini) VLMs to ensure diversity. The experimental results indicate that models trained with alignment techniques on the SPA-VL dataset exhibit substantial improvements in harmlessness and helpfulness while maintaining core capabilities. SPA-VL, as a large-scale, high-quality, and diverse dataset, represents a significant milestone in ensuring that VLMs achieve both harmlessness and helpfulness. We have made our code https://github.com/EchoseChen/SPA-VL-RLHF and SPA-VL dataset url https://huggingface.co/datasets/sqrti/SPA-VL publicly available.
Training Large Language Models for Reasoning through Reverse Curriculum Reinforcement Learning
Feb 08, 2024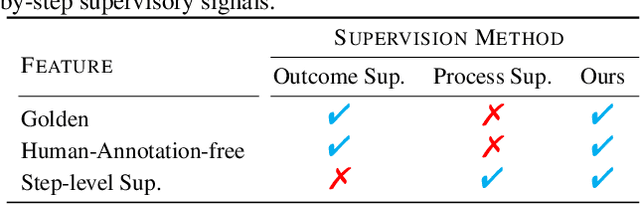
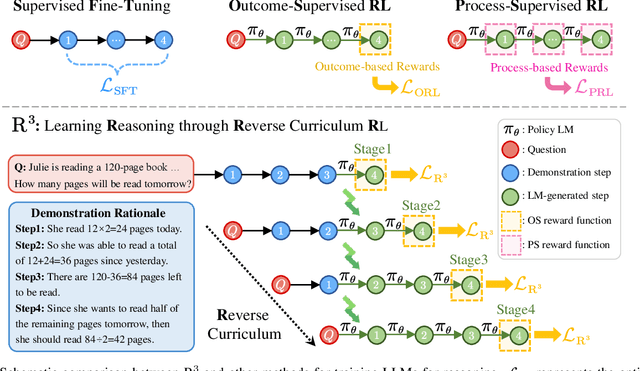
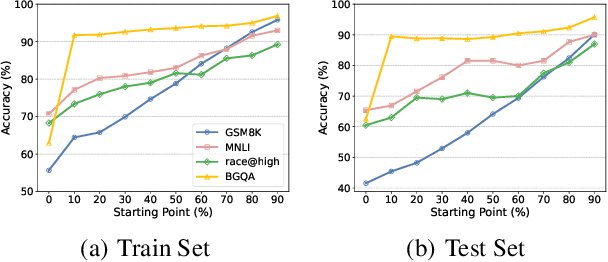

In this paper, we propose R$^3$: Learning Reasoning through Reverse Curriculum Reinforcement Learning (RL), a novel method that employs only outcome supervision to achieve the benefits of process supervision for large language models. The core challenge in applying RL to complex reasoning is to identify a sequence of actions that result in positive rewards and provide appropriate supervision for optimization. Outcome supervision provides sparse rewards for final results without identifying error locations, whereas process supervision offers step-wise rewards but requires extensive manual annotation. R$^3$ overcomes these limitations by learning from correct demonstrations. Specifically, R$^3$ progressively slides the start state of reasoning from a demonstration's end to its beginning, facilitating easier model exploration at all stages. Thus, R$^3$ establishes a step-wise curriculum, allowing outcome supervision to offer step-level signals and precisely pinpoint errors. Using Llama2-7B, our method surpasses RL baseline on eight reasoning tasks by $4.1$ points on average. Notebaly, in program-based reasoning on GSM8K, it exceeds the baseline by $4.2$ points across three backbone models, and without any extra data, Codellama-7B + R$^3$ performs comparable to larger models or closed-source models.
MouSi: Poly-Visual-Expert Vision-Language Models
Jan 30, 2024Current large vision-language models (VLMs) often encounter challenges such as insufficient capabilities of a single visual component and excessively long visual tokens. These issues can limit the model's effectiveness in accurately interpreting complex visual information and over-lengthy contextual information. Addressing these challenges is crucial for enhancing the performance and applicability of VLMs. This paper proposes the use of ensemble experts technique to synergizes the capabilities of individual visual encoders, including those skilled in image-text matching, OCR, image segmentation, etc. This technique introduces a fusion network to unify the processing of outputs from different visual experts, while bridging the gap between image encoders and pre-trained LLMs. In addition, we explore different positional encoding schemes to alleviate the waste of positional encoding caused by lengthy image feature sequences, effectively addressing the issue of position overflow and length limitations. For instance, in our implementation, this technique significantly reduces the positional occupancy in models like SAM, from a substantial 4096 to a more efficient and manageable 64 or even down to 1. Experimental results demonstrate that VLMs with multiple experts exhibit consistently superior performance over isolated visual encoders and mark a significant performance boost as more experts are integrated. We have open-sourced the training code used in this report. All of these resources can be found on our project website.
Secrets of RLHF in Large Language Models Part II: Reward Modeling
Jan 12, 2024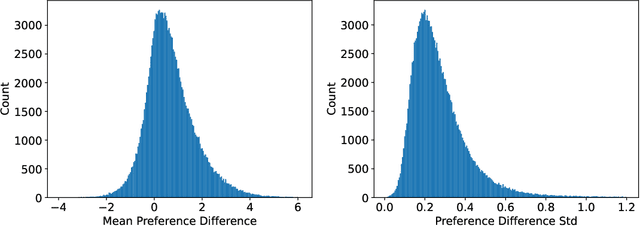

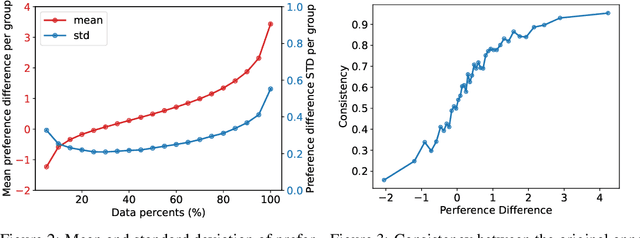
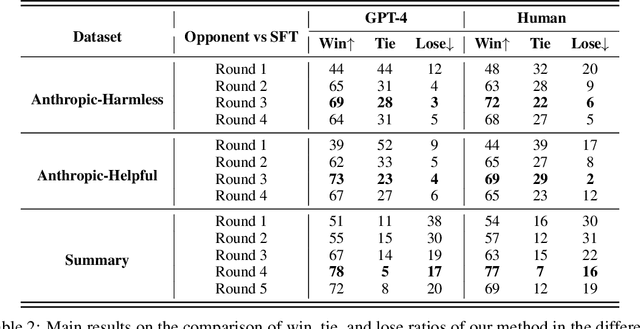
Reinforcement Learning from Human Feedback (RLHF) has become a crucial technology for aligning language models with human values and intentions, enabling models to produce more helpful and harmless responses. Reward models are trained as proxies for human preferences to drive reinforcement learning optimization. While reward models are often considered central to achieving high performance, they face the following challenges in practical applications: (1) Incorrect and ambiguous preference pairs in the dataset may hinder the reward model from accurately capturing human intent. (2) Reward models trained on data from a specific distribution often struggle to generalize to examples outside that distribution and are not suitable for iterative RLHF training. In this report, we attempt to address these two issues. (1) From a data perspective, we propose a method to measure the strength of preferences within the data, based on a voting mechanism of multiple reward models. Experimental results confirm that data with varying preference strengths have different impacts on reward model performance. We introduce a series of novel methods to mitigate the influence of incorrect and ambiguous preferences in the dataset and fully leverage high-quality preference data. (2) From an algorithmic standpoint, we introduce contrastive learning to enhance the ability of reward models to distinguish between chosen and rejected responses, thereby improving model generalization. Furthermore, we employ meta-learning to enable the reward model to maintain the ability to differentiate subtle differences in out-of-distribution samples, and this approach can be utilized for iterative RLHF optimization.
TRACE: A Comprehensive Benchmark for Continual Learning in Large Language Models
Oct 10, 2023Aligned large language models (LLMs) demonstrate exceptional capabilities in task-solving, following instructions, and ensuring safety. However, the continual learning aspect of these aligned LLMs has been largely overlooked. Existing continual learning benchmarks lack sufficient challenge for leading aligned LLMs, owing to both their simplicity and the models' potential exposure during instruction tuning. In this paper, we introduce TRACE, a novel benchmark designed to evaluate continual learning in LLMs. TRACE consists of 8 distinct datasets spanning challenging tasks including domain-specific tasks, multilingual capabilities, code generation, and mathematical reasoning. All datasets are standardized into a unified format, allowing for effortless automatic evaluation of LLMs. Our experiments show that after training on TRACE, aligned LLMs exhibit significant declines in both general ability and instruction-following capabilities. For example, the accuracy of llama2-chat 13B on gsm8k dataset declined precipitously from 28.8\% to 2\% after training on our datasets. This highlights the challenge of finding a suitable tradeoff between achieving performance on specific tasks while preserving the original prowess of LLMs. Empirical findings suggest that tasks inherently equipped with reasoning paths contribute significantly to preserving certain capabilities of LLMs against potential declines. Motivated by this, we introduce the Reasoning-augmented Continual Learning (RCL) approach. RCL integrates task-specific cues with meta-rationales, effectively reducing catastrophic forgetting in LLMs while expediting convergence on novel tasks.