 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining LLMs for Divide-and-Conquer Reasoning Elevates Test-Time Scalability
Feb 02, 2026Large language models (LLMs) have demonstrated strong reasoning capabilities through step-by-step chain-of-thought (CoT) reasoning. Nevertheless, at the limits of model capability, CoT often proves insufficient, and its strictly sequential nature constrains test-time scalability. A potential alternative is divide-and-conquer (DAC) reasoning, which decomposes a complex problem into subproblems to facilitate more effective exploration of the solution. Although promising, our analysis reveals a fundamental misalignment between general-purpose post-training and DAC-style inference, which limits the model's capacity to fully leverage this potential. To bridge this gap and fully unlock LLMs' reasoning capabilities on the most challenging tasks, we propose an end-to-end reinforcement learning (RL) framework to enhance their DAC-style reasoning capacity. At each step, the policy decomposes a problem into a group of subproblems, solves them sequentially, and addresses the original one conditioned on the subproblem solutions, with both decomposition and solution integrated into RL training. Under comparable training, our DAC-style framework endows the model with a higher performance ceiling and stronger test-time scalability, surpassing CoT by 8.6% in Pass@1 and 6.3% in Pass@32 on competition-level benchmarks.
Residual Decoding: Mitigating Hallucinations in Large Vision-Language Models via History-Aware Residual Guidance
Feb 01, 2026Large Vision-Language Models (LVLMs) can reason effectively from image-text inputs and perform well in various multimodal tasks. Despite this success, they are affected by language priors and often produce hallucinations. Hallucinations denote generated content that is grammatically and syntactically coherent, yet bears no match or direct relevance to actual visual input. To address this problem, we propose Residual Decoding (ResDec). It is a novel training-free method that uses historical information to aid decoding. The method relies on the internal implicit reasoning mechanism and token logits evolution mechanism of LVLMs to correct biases. Extensive experiments demonstrate that ResDec effectively suppresses hallucinations induced by language priors, significantly improves visual grounding, and reduces object hallucinations. In addition to mitigating hallucinations, ResDec also performs exceptionally well on comprehensive LVLM benchmarks, highlighting its broad applicability.
Locate, Steer, and Improve: A Practical Survey of Actionable Mechanistic Interpretability in Large Language Models
Jan 20, 2026Mechanistic Interpretability (MI) has emerged as a vital approach to demystify the opaque decision-making of Large Language Models (LLMs). However, existing reviews primarily treat MI as an observational science, summarizing analytical insights while lacking a systematic framework for actionable intervention. To bridge this gap, we present a practical survey structured around the pipeline: "Locate, Steer, and Improve." We formally categorize Localizing (diagnosis) and Steering (intervention) methods based on specific Interpretable Objects to establish a rigorous intervention protocol. Furthermore, we demonstrate how this framework enables tangible improvements in Alignment, Capability, and Efficiency, effectively operationalizing MI as an actionable methodology for model optimization. The curated paper list of this work is available at https://github.com/rattlesnakey/Awesome-Actionable-MI-Survey.
MMFormalizer: Multimodal Autoformalization in the Wild
Jan 06, 2026Autoformalization, which translates natural language mathematics into formal statements to enable machine reasoning, faces fundamental challenges in the wild due to the multimodal nature of the physical world, where physics requires inferring hidden constraints (e.g., mass or energy) from visual elements. To address this, we propose MMFormalizer, which extends autoformalization beyond text by integrating adaptive grounding with entities from real-world mathematical and physical domains. MMFormalizer recursively constructs formal propositions from perceptually grounded primitives through recursive grounding and axiom composition, with adaptive recursive termination ensuring that every abstraction is supported by visual evidence and anchored in dimensional or axiomatic grounding. We evaluate MMFormalizer on a new benchmark, PhyX-AF, comprising 115 curated samples from MathVerse, PhyX, Synthetic Geometry, and Analytic Geometry, covering diverse multimodal autoformalization tasks. Results show that frontier models such as GPT-5 and Gemini-3-Pro achieve the highest compile and semantic accuracy, with GPT-5 excelling in physical reasoning, while geometry remains the most challenging domain. Overall, MMFormalizer provides a scalable framework for unified multimodal autoformalization, bridging perception and formal reasoning. To the best of our knowledge, this is the first multimodal autoformalization method capable of handling classical mechanics (derived from the Hamiltonian), as well as relativity, quantum mechanics, and thermodynamics. More details are available on our project page: MMFormalizer.github.io
Gaussian Combined Distance: A Generic Metric for Object Detection
Oct 31, 2025In object detection, a well-defined similarity metric can significantly enhance model performance. Currently, the IoU-based similarity metric is the most commonly preferred choice for detectors. However, detectors using IoU as a similarity metric often perform poorly when detecting small objects because of their sensitivity to minor positional deviations. To address this issue, recent studies have proposed the Wasserstein Distance as an alternative to IoU for measuring the similarity of Gaussian-distributed bounding boxes. However, we have observed that the Wasserstein Distance lacks scale invariance, which negatively impacts the model's generalization capability. Additionally, when used as a loss function, its independent optimization of the center attributes leads to slow model convergence and unsatisfactory detection precision. To address these challenges, we introduce the Gaussian Combined Distance (GCD). Through analytical examination of GCD and its gradient, we demonstrate that GCD not only possesses scale invariance but also facilitates joint optimization, which enhances model localization performance. Extensive experiments on the AI-TOD-v2 dataset for tiny object detection show that GCD, as a bounding box regression loss function and label assignment metric, achieves state-of-the-art performance across various detectors. We further validated the generalizability of GCD on the MS-COCO-2017 and Visdrone-2019 datasets, where it outperforms the Wasserstein Distance across diverse scales of datasets. Code is available at https://github.com/MArKkwanGuan/mmdet-GCD.
DanceEditor: Towards Iterative Editable Music-driven Dance Generation with Open-Vocabulary Descriptions
Aug 24, 2025



Generating coherent and diverse human dances from music signals has gained tremendous progress in animating virtual avatars. While existing methods support direct dance synthesis, they fail to recognize that enabling users to edit dance movements is far more practical in real-world choreography scenarios. Moreover, the lack of high-quality dance datasets incorporating iterative editing also limits addressing this challenge. To achieve this goal, we first construct DanceRemix, a large-scale multi-turn editable dance dataset comprising the prompt featuring over 25.3M dance frames and 84.5K pairs. In addition, we propose a novel framework for iterative and editable dance generation coherently aligned with given music signals, namely DanceEditor. Considering the dance motion should be both musical rhythmic and enable iterative editing by user descriptions, our framework is built upon a prediction-then-editing paradigm unifying multi-modal conditions. At the initial prediction stage, our framework improves the authority of generated results by directly modeling dance movements from tailored, aligned music. Moreover, at the subsequent iterative editing stages, we incorporate text descriptions as conditioning information to draw the editable results through a specifically designed Cross-modality Editing Module (CEM). Specifically, CEM adaptively integrates the initial prediction with music and text prompts as temporal motion cues to guide the synthesized sequences. Thereby, the results display music harmonics while preserving fine-grained semantic alignment with text descriptions. Extensive experiments demonstrate that our method outperforms the state-of-the-art models on our newly collected DanceRemix dataset. Code is available at https://lzvsdy.github.io/DanceEditor/.
GuiLoMo: Allocating Expert Number and Rank for LoRA-MoE via Bilevel Optimization with GuidedSelection Vectors
Jun 17, 2025Parameter-efficient fine-tuning (PEFT) methods, particularly Low-Rank Adaptation (LoRA), offer an efficient way to adapt large language models with reduced computational costs. However, their performance is limited by the small number of trainable parameters. Recent work combines LoRA with the Mixture-of-Experts (MoE), i.e., LoRA-MoE, to enhance capacity, but two limitations remain in hindering the full exploitation of its potential: 1) the influence of downstream tasks when assigning expert numbers, and 2) the uniform rank assignment across all LoRA experts, which restricts representational diversity. To mitigate these gaps, we propose GuiLoMo, a fine-grained layer-wise expert numbers and ranks allocation strategy with GuidedSelection Vectors (GSVs). GSVs are learned via a prior bilevel optimization process to capture both model- and task-specific needs, and are then used to allocate optimal expert numbers and ranks. Experiments on three backbone models across diverse benchmarks show that GuiLoMo consistently achieves superior or comparable performance to all baselines. Further analysis offers key insights into how expert numbers and ranks vary across layers and tasks, highlighting the benefits of adaptive expert configuration. Our code is available at https://github.com/Liar406/Gui-LoMo.git.
SwS: Self-aware Weakness-driven Problem Synthesis in Reinforcement Learning for LLM Reasoning
Jun 10, 2025Reinforcement Learning with Verifiable Rewards (RLVR) has proven effective for training large language models (LLMs) on complex reasoning tasks, such as mathematical problem solving. A prerequisite for the scalability of RLVR is a high-quality problem set with precise and verifiable answers. However, the scarcity of well-crafted human-labeled math problems and limited-verification answers in existing distillation-oriented synthetic datasets limit their effectiveness in RL. Additionally, most problem synthesis strategies indiscriminately expand the problem set without considering the model's capabilities, leading to low efficiency in generating useful questions. To mitigate this issue, we introduce a Self-aware Weakness-driven problem Synthesis framework (SwS) that systematically identifies model deficiencies and leverages them for problem augmentation. Specifically, we define weaknesses as questions that the model consistently fails to learn through its iterative sampling during RL training. We then extract the core concepts from these failure cases and synthesize new problems to strengthen the model's weak areas in subsequent augmented training, enabling it to focus on and gradually overcome its weaknesses. Without relying on external knowledge distillation, our framework enables robust generalization byempowering the model to self-identify and address its weaknesses in RL, yielding average performance gains of 10.0% and 7.7% on 7B and 32B models across eight mainstream reasoning benchmarks.
TreeReview: A Dynamic Tree of Questions Framework for Deep and Efficient LLM-based Scientific Peer Review
Jun 09, 2025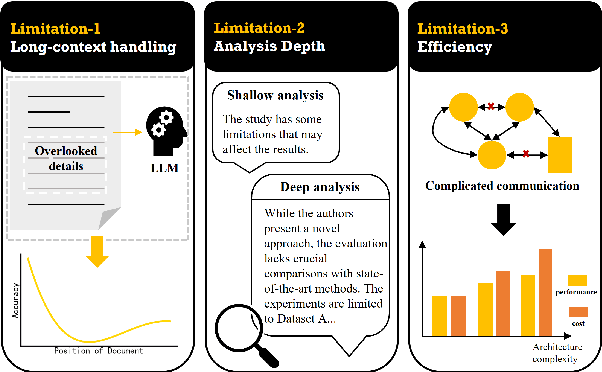
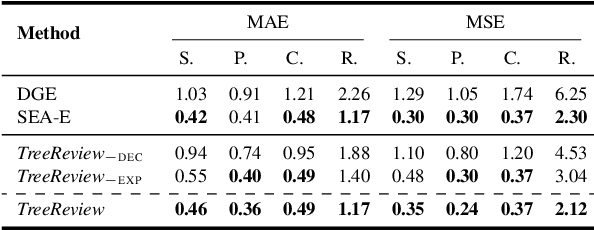
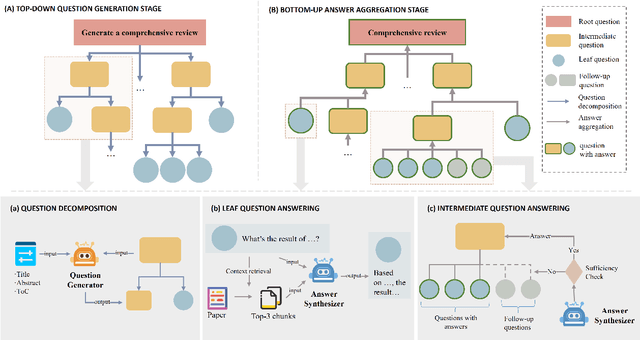
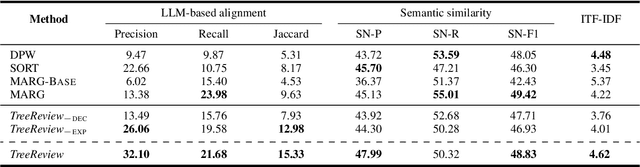
While Large Language Models (LLMs) have shown significant potential in assisting peer review, current methods often struggle to generate thorough and insightful reviews while maintaining efficiency. In this paper, we propose TreeReview, a novel framework that models paper review as a hierarchical and bidirectional question-answering process. TreeReview first constructs a tree of review questions by recursively decomposing high-level questions into fine-grained sub-questions and then resolves the question tree by iteratively aggregating answers from leaf to root to get the final review. Crucially, we incorporate a dynamic question expansion mechanism to enable deeper probing by generating follow-up questions when needed. We construct a benchmark derived from ICLR and NeurIPS venues to evaluate our method on full review generation and actionable feedback comments generation tasks. Experimental results of both LLM-based and human evaluation show that TreeReview outperforms strong baselines in providing comprehensive, in-depth, and expert-aligned review feedback, while reducing LLM token usage by up to 80% compared to computationally intensive approaches. Our code and benchmark dataset are available at https://github.com/YuanChang98/tree-review.
Co$^{3}$Gesture: Towards Coherent Concurrent Co-speech 3D Gesture Generation with Interactive Diffusion
May 03, 2025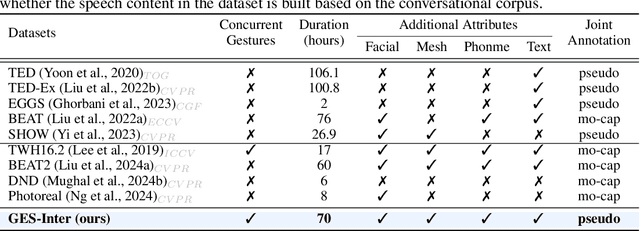

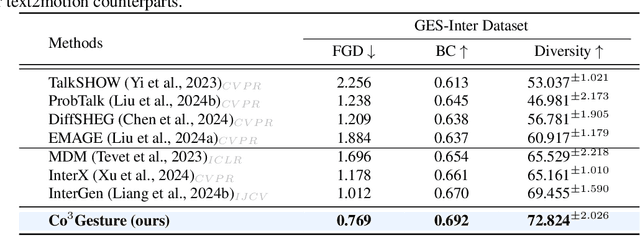
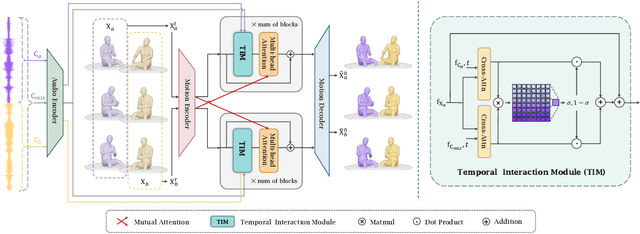
Generating gestures from human speech has gained tremendous progress in animating virtual avatars. While the existing methods enable synthesizing gestures cooperated by individual self-talking, they overlook the practicality of concurrent gesture modeling with two-person interactive conversations. Moreover, the lack of high-quality datasets with concurrent co-speech gestures also limits handling this issue. To fulfill this goal, we first construct a large-scale concurrent co-speech gesture dataset that contains more than 7M frames for diverse two-person interactive posture sequences, dubbed GES-Inter. Additionally, we propose Co$^3$Gesture, a novel framework that enables coherent concurrent co-speech gesture synthesis including two-person interactive movements. Considering the asymmetric body dynamics of two speakers, our framework is built upon two cooperative generation branches conditioned on separated speaker audio. Specifically, to enhance the coordination of human postures with respect to corresponding speaker audios while interacting with the conversational partner, we present a Temporal Interaction Module (TIM). TIM can effectively model the temporal association representation between two speakers' gesture sequences as interaction guidance and fuse it into the concurrent gesture generation. Then, we devise a mutual attention mechanism to further holistically boost learning dependencies of interacted concurrent motions, thereby enabling us to generate vivid and coherent gestures. Extensive experiments demonstrate that our method outperforms the state-of-the-art models on our newly collected GES-Inter dataset. The dataset and source code are publicly available at \href{https://mattie-e.github.io/Co3/}{\textit{https://mattie-e.github.io/Co3/}}.