 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVISOR: VIsual Spatial Object Reasoning for Language-driven Object Navigation
Feb 07, 2026Language-driven object navigation requires agents to interpret natural language descriptions of target objects, which combine intrinsic and extrinsic attributes for instance recognition and commonsense navigation. Existing methods either (i) use end-to-end trained models with vision-language embeddings, which struggle to generalize beyond training data and lack action-level explainability, or (ii) rely on modular zero-shot pipelines with large language models (LLMs) and open-set object detectors, which suffer from error propagation, high computational cost, and difficulty integrating their reasoning back into the navigation policy. To this end, we propose a compact 3B-parameter Vision-Language-Action (VLA) agent that performs human-like embodied reasoning for both object recognition and action selection, removing the need for stitched multi-model pipelines. Instead of raw embedding matching, our agent employs explicit image-grounded reasoning to directly answer "Is this the target object?" and "Why should I take this action?" The reasoning process unfolds in three stages: "think", "think summary", and "action", yielding improved explainability, stronger generalization, and more efficient navigation. Code and dataset available upon acceptance.
Quantifying the Robustness of Retrieval-Augmented Language Models Against Spurious Features in Grounding Data
Mar 07, 2025Robustness has become a critical attribute for the deployment of RAG systems in real-world applications. Existing research focuses on robustness to explicit noise (e.g., document semantics) but overlooks spurious features (a.k.a. implicit noise). While previous works have explored spurious features in LLMs, they are limited to specific features (e.g., formats) and narrow scenarios (e.g., ICL). In this work, we statistically confirm the presence of spurious features in the RAG paradigm, a robustness problem caused by the sensitivity of LLMs to semantic-agnostic features. Moreover, we provide a comprehensive taxonomy of spurious features and empirically quantify their impact through controlled experiments. Further analysis reveals that not all spurious features are harmful and they can even be beneficial sometimes. Extensive evaluation results across multiple LLMs suggest that spurious features are a widespread and challenging problem in the field of RAG. The code and dataset will be released to facilitate future research. We release all codes and data at: $\\\href{https://github.com/maybenotime/RAG-SpuriousFeatures}{https://github.com/maybenotime/RAG-SpuriousFeatures}$.
MuDAF: Long-Context Multi-Document Attention Focusing through Contrastive Learning on Attention Heads
Feb 19, 2025Large Language Models (LLMs) frequently show distracted attention due to irrelevant information in the input, which severely impairs their long-context capabilities. Inspired by recent studies on the effectiveness of retrieval heads in long-context factutality, we aim at addressing this distraction issue through improving such retrieval heads directly. We propose Multi-Document Attention Focusing (MuDAF), a novel method that explicitly optimizes the attention distribution at the head level through contrastive learning. According to the experimental results, MuDAF can significantly improve the long-context question answering performance of LLMs, especially in multi-document question answering. Extensive evaluations on retrieval scores and attention visualizations show that MuDAF possesses great potential in making attention heads more focused on relevant information and reducing attention distractions.
Fostering Natural Conversation in Large Language Models with NICO: a Natural Interactive COnversation dataset
Aug 18, 2024
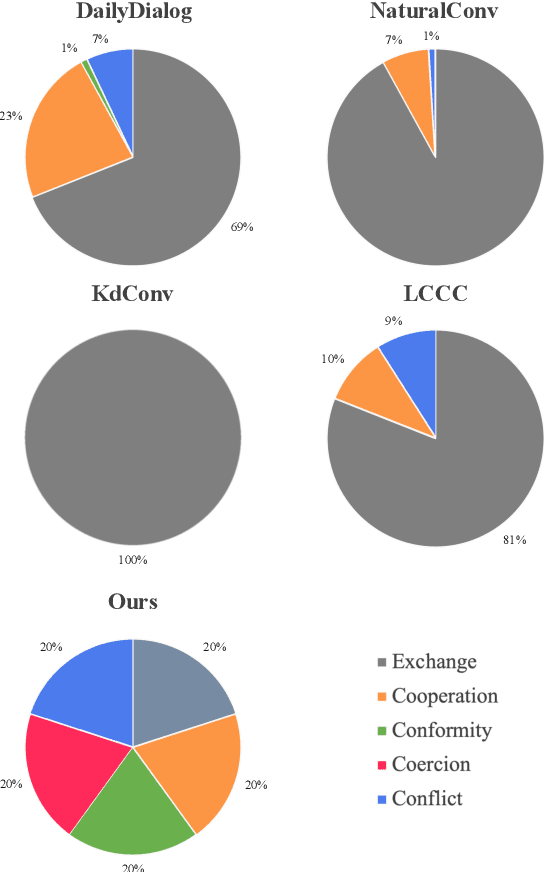
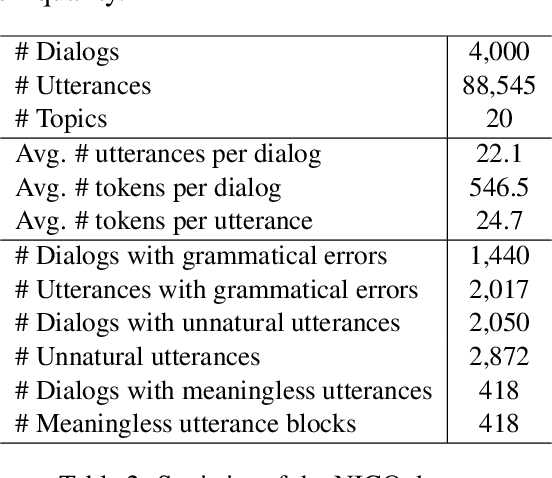
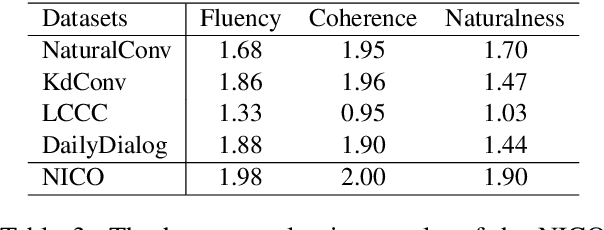
Benefiting from diverse instruction datasets, contemporary Large Language Models (LLMs) perform effectively as AI assistants in collaborating with humans. However, LLMs still struggle to generate natural and colloquial responses in real-world applications such as chatbots and psychological counseling that require more human-like interactions. To address these limitations, we introduce NICO, a Natural Interactive COnversation dataset in Chinese. We first use GPT-4-turbo to generate dialogue drafts and make them cover 20 daily-life topics and 5 types of social interactions. Then, we hire workers to revise these dialogues to ensure that they are free of grammatical errors and unnatural utterances. We define two dialogue-level natural conversation tasks and two sentence-level tasks for identifying and rewriting unnatural sentences. Multiple open-source and closed-source LLMs are tested and analyzed in detail. The experimental results highlight the challenge of the tasks and demonstrate how NICO can help foster the natural dialogue capabilities of LLMs. The dataset will be released.
A New Benchmark and Reverse Validation Method for Passage-level Hallucination Detection
Oct 24, 2023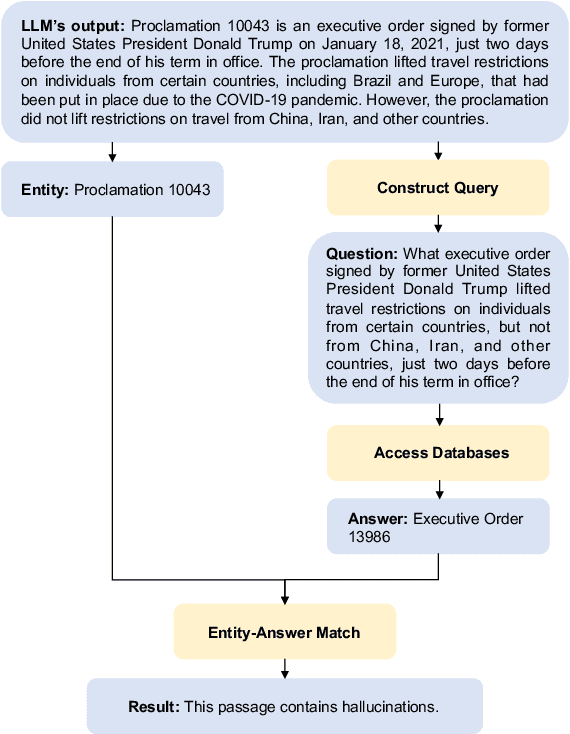
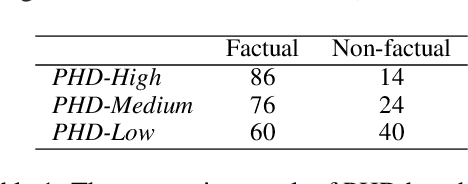

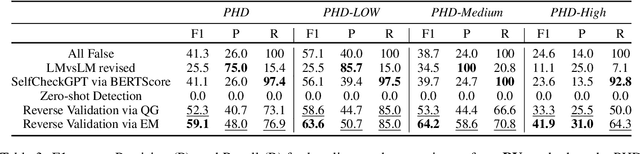
Large Language Models (LLMs) have shown their ability to collaborate effectively with humans in real-world scenarios. However, LLMs are apt to generate hallucinations, i.e., makeup incorrect text and unverified information, which can cause significant damage when deployed for mission-critical tasks. In this paper, we propose a self-check approach based on reverse validation to detect factual errors automatically in a zero-resource fashion. To facilitate future studies and assess different methods, we construct a hallucination detection benchmark named PHD, which is generated by ChatGPT and annotated by human annotators. Contrasting previous studies of zero-resource hallucination detection, our method and benchmark concentrate on passage-level detection instead of sentence-level. We empirically evaluate our method and existing zero-resource detection methods on two datasets. The experimental results demonstrate that the proposed method considerably outperforms the baselines while costing fewer tokens and less time. Furthermore, we manually analyze some hallucination cases that LLM failed to capture, revealing the shared limitation of zero-resource methods.
Multi-level Contrastive Learning for Script-based Character Understanding
Oct 20, 2023In this work, we tackle the scenario of understanding characters in scripts, which aims to learn the characters' personalities and identities from their utterances. We begin by analyzing several challenges in this scenario, and then propose a multi-level contrastive learning framework to capture characters' global information in a fine-grained manner. To validate the proposed framework, we conduct extensive experiments on three character understanding sub-tasks by comparing with strong pre-trained language models, including SpanBERT, Longformer, BigBird and ChatGPT-3.5. Experimental results demonstrate that our method improves the performances by a considerable margin. Through further in-depth analysis, we show the effectiveness of our method in addressing the challenges and provide more hints on the scenario of character understanding. We will open-source our work on github at https://github.com/David-Li0406/Script-based-Character-Understanding.
A New Dataset and Empirical Study for Sentence Simplification in Chinese
Jun 07, 2023
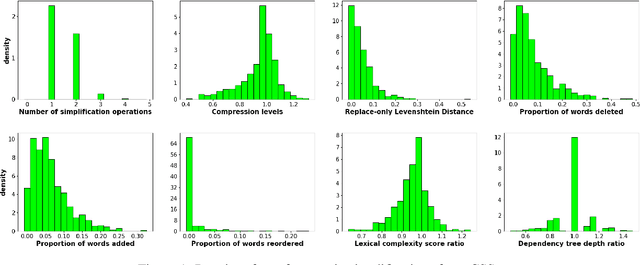
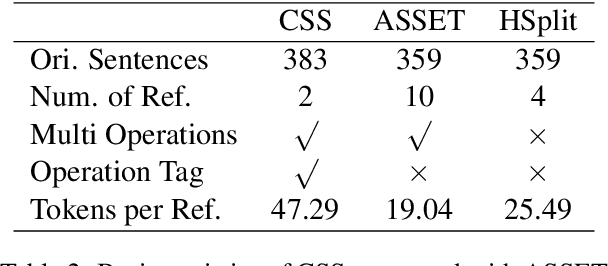

Sentence Simplification is a valuable technique that can benefit language learners and children a lot. However, current research focuses more on English sentence simplification. The development of Chinese sentence simplification is relatively slow due to the lack of data. To alleviate this limitation, this paper introduces CSS, a new dataset for assessing sentence simplification in Chinese. We collect manual simplifications from human annotators and perform data analysis to show the difference between English and Chinese sentence simplifications. Furthermore, we test several unsupervised and zero/few-shot learning methods on CSS and analyze the automatic evaluation and human evaluation results. In the end, we explore whether Large Language Models can serve as high-quality Chinese sentence simplification systems by evaluating them on CSS.
Human-like Summarization Evaluation with ChatGPT
Apr 05, 2023



Evaluating text summarization is a challenging problem, and existing evaluation metrics are far from satisfactory. In this study, we explored ChatGPT's ability to perform human-like summarization evaluation using four human evaluation methods on five datasets. We found that ChatGPT was able to complete annotations relatively smoothly using Likert scale scoring, pairwise comparison, Pyramid, and binary factuality evaluation. Additionally, it outperformed commonly used automatic evaluation metrics on some datasets. Furthermore, we discussed the impact of different prompts, compared its performance with that of human evaluation, and analyzed the generated explanations and invalid responses.
LAD-RCNN:A Powerful Tool for Livestock Face Detection and Normalization
Nov 05, 2022With the demand for standardized large-scale livestock farming and the development of artificial intelligence technology, a lot of research in area of animal face recognition were carried on pigs, cattle, sheep and other livestock. Face recognition consists of three sub-task: face detection, face normalizing and face identification. Most of animal face recognition study focuses on face detection and face identification. Animals are often uncooperative when taking photos, so the collected animal face images are often in arbitrary directions. The use of non-standard images may significantly reduce the performance of face recognition system. However, there is no study on normalizing of the animal face image with arbitrary directions. In this study, we developed a light-weight angle detection and region-based convolutional network (LAD-RCNN) containing a new rotation angle coding method that can detect the rotation angle and the location of animal face in one-stage. LAD-RCNN has a frame rate of 72.74 FPS (including all steps) on a single GeForce RTX 2080 Ti GPU. LAD-RCNN has been evaluated on multiple dataset including goat dataset and gaot infrared image. Evaluation result show that the AP of face detection was more than 95% and the deviation between the detected rotation angle and the ground-truth rotation angle were less than 0.036 (i.e. 6.48{\deg}) on all the test dataset. This shows that LAD-RCNN has excellent performance on livestock face and its direction detection, and therefore it is very suitable for livestock face detection and Normalizing. Code is available at https://github.com/SheepBreedingLab-HZAU/LAD-RCNN/
Fine-grained Contrastive Learning for Definition Generation
Oct 02, 2022
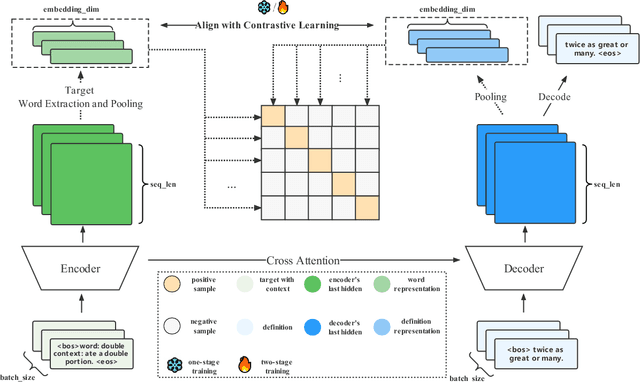

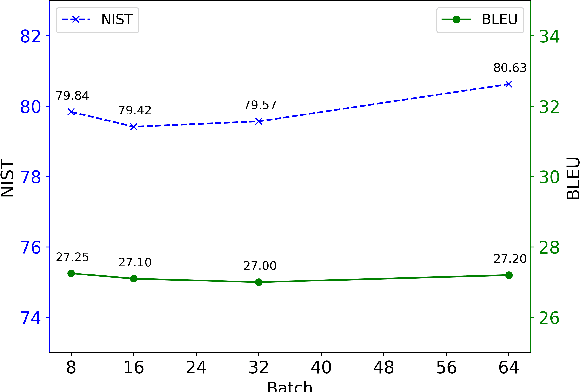
Recently, pre-trained transformer-based models have achieved great success in the task of definition generation (DG). However, previous encoder-decoder models lack effective representation learning to contain full semantic components of the given word, which leads to generating under-specific definitions. To address this problem, we propose a novel contrastive learning method, encouraging the model to capture more detailed semantic representations from the definition sequence encoding. According to both automatic and manual evaluation, the experimental results on three mainstream benchmarks demonstrate that the proposed method could generate more specific and high-quality definitions compared with several state-of-the-art models.