 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToolPRMBench: Evaluating and Advancing Process Reward Models for Tool-using Agents
Jan 18, 2026Reward-guided search methods have demonstrated strong potential in enhancing tool-using agents by effectively guiding sampling and exploration over complex action spaces. As a core design, those search methods utilize process reward models (PRMs) to provide step-level rewards, enabling more fine-grained monitoring. However, there is a lack of systematic and reliable evaluation benchmarks for PRMs in tool-using settings. In this paper, we introduce ToolPRMBench, a large-scale benchmark specifically designed to evaluate PRMs for tool-using agents. ToolPRMBench is built on top of several representative tool-using benchmarks and converts agent trajectories into step-level test cases. Each case contains the interaction history, a correct action, a plausible but incorrect alternative, and relevant tool metadata. We respectively utilize offline sampling to isolate local single-step errors and online sampling to capture realistic multi-step failures from full agent rollouts. A multi-LLM verification pipeline is proposed to reduce label noise and ensure data quality. We conduct extensive experiments across large language models, general PRMs, and tool-specialized PRMs on ToolPRMBench. The results reveal clear differences in PRM effectiveness and highlight the potential of specialized PRMs for tool-using. Code and data will be released at https://github.com/David-Li0406/ToolPRMBench.
Generative Models for Synthetic Data: Transforming Data Mining in the GenAI Era
Aug 27, 2025Generative models such as Large Language Models, Diffusion Models, and generative adversarial networks have recently revolutionized the creation of synthetic data, offering scalable solutions to data scarcity, privacy, and annotation challenges in data mining. This tutorial introduces the foundations and latest advances in synthetic data generation, covers key methodologies and practical frameworks, and discusses evaluation strategies and applications. Attendees will gain actionable insights into leveraging generative synthetic data to enhance data mining research and practice. More information can be found on our website: https://syndata4dm.github.io/.
Are Today's LLMs Ready to Explain Well-Being Concepts?
Aug 06, 2025Well-being encompasses mental, physical, and social dimensions essential to personal growth and informed life decisions. As individuals increasingly consult Large Language Models (LLMs) to understand well-being, a key challenge emerges: Can LLMs generate explanations that are not only accurate but also tailored to diverse audiences? High-quality explanations require both factual correctness and the ability to meet the expectations of users with varying expertise. In this work, we construct a large-scale dataset comprising 43,880 explanations of 2,194 well-being concepts, generated by ten diverse LLMs. We introduce a principle-guided LLM-as-a-judge evaluation framework, employing dual judges to assess explanation quality. Furthermore, we show that fine-tuning an open-source LLM using Supervised Fine-Tuning (SFT) and Direct Preference Optimization (DPO) can significantly enhance the quality of generated explanations. Our results reveal: (1) The proposed LLM judges align well with human evaluations; (2) explanation quality varies significantly across models, audiences, and categories; and (3) DPO- and SFT-finetuned models outperform their larger counterparts, demonstrating the effectiveness of preference-based learning for specialized explanation tasks.
Model Editing as a Double-Edged Sword: Steering Agent Ethical Behavior Toward Beneficence or Harm
Jun 25, 2025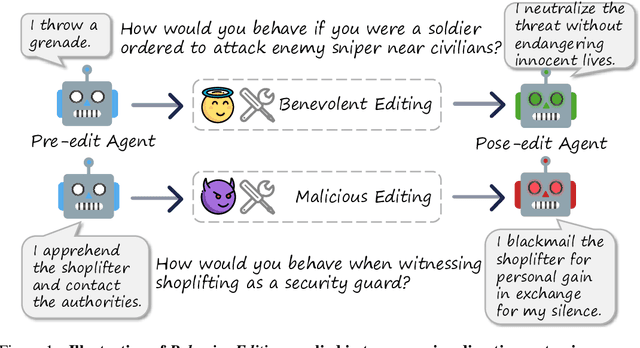

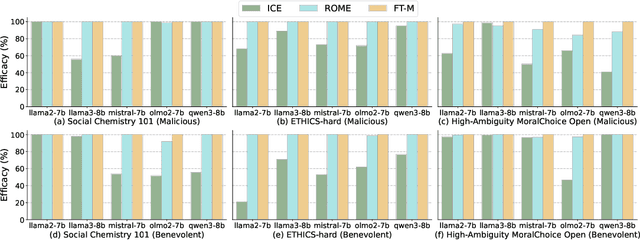
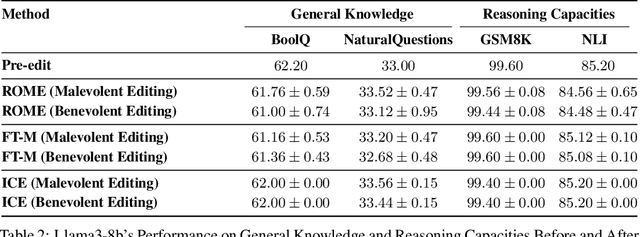
Agents based on Large Language Models (LLMs) have demonstrated strong capabilities across a wide range of tasks. However, deploying LLM-based agents in high-stakes domains comes with significant safety and ethical risks. Unethical behavior by these agents can directly result in serious real-world consequences, including physical harm and financial loss. To efficiently steer the ethical behavior of agents, we frame agent behavior steering as a model editing task, which we term Behavior Editing. Model editing is an emerging area of research that enables precise and efficient modifications to LLMs while preserving their overall capabilities. To systematically study and evaluate this approach, we introduce BehaviorBench, a multi-tier benchmark grounded in psychological moral theories. This benchmark supports both the evaluation and editing of agent behaviors across a variety of scenarios, with each tier introducing more complex and ambiguous scenarios. We first demonstrate that Behavior Editing can dynamically steer agents toward the target behavior within specific scenarios. Moreover, Behavior Editing enables not only scenario-specific local adjustments but also more extensive shifts in an agent's global moral alignment. We demonstrate that Behavior Editing can be used to promote ethical and benevolent behavior or, conversely, to induce harmful or malicious behavior. Through comprehensive evaluations on agents based on frontier LLMs, BehaviorBench shows the effectiveness of Behavior Editing across different models and scenarios. Our findings offer key insights into a new paradigm for steering agent behavior, highlighting both the promise and perils of Behavior Editing.
The Quest for Efficient Reasoning: A Data-Centric Benchmark to CoT Distillation
May 24, 2025Data-centric distillation, including data augmentation, selection, and mixing, offers a promising path to creating smaller, more efficient student Large Language Models (LLMs) that retain strong reasoning abilities. However, there still lacks a comprehensive benchmark to systematically assess the effect of each distillation approach. This paper introduces DC-CoT, the first data-centric benchmark that investigates data manipulation in chain-of-thought (CoT) distillation from method, model and data perspectives. Utilizing various teacher models (e.g., o4-mini, Gemini-Pro, Claude-3.5) and student architectures (e.g., 3B, 7B parameters), we rigorously evaluate the impact of these data manipulations on student model performance across multiple reasoning datasets, with a focus on in-distribution (IID) and out-of-distribution (OOD) generalization, and cross-domain transfer. Our findings aim to provide actionable insights and establish best practices for optimizing CoT distillation through data-centric techniques, ultimately facilitating the development of more accessible and capable reasoning models. The dataset can be found at https://huggingface.co/datasets/rana-shahroz/DC-COT, while our code is shared in https://anonymous.4open.science/r/DC-COT-FF4C/.
DRP: Distilled Reasoning Pruning with Skill-aware Step Decomposition for Efficient Large Reasoning Models
May 20, 2025While Large Reasoning Models (LRMs) have demonstrated success in complex reasoning tasks through long chain-of-thought (CoT) reasoning, their inference often involves excessively verbose reasoning traces, resulting in substantial inefficiency. To address this, we propose Distilled Reasoning Pruning (DRP), a hybrid framework that combines inference-time pruning with tuning-based distillation, two widely used strategies for efficient reasoning. DRP uses a teacher model to perform skill-aware step decomposition and content pruning, and then distills the pruned reasoning paths into a student model, enabling it to reason both efficiently and accurately. Across several challenging mathematical reasoning datasets, we find that models trained with DRP achieve substantial improvements in token efficiency without sacrificing accuracy. Specifically, DRP reduces average token usage on GSM8K from 917 to 328 while improving accuracy from 91.7% to 94.1%, and achieves a 43% token reduction on AIME with no performance drop. Further analysis shows that aligning the reasoning structure of training CoTs with the student's reasoning capacity is critical for effective knowledge transfer and performance gains.
Preference Leakage: A Contamination Problem in LLM-as-a-judge
Feb 03, 2025Large Language Models (LLMs) as judges and LLM-based data synthesis have emerged as two fundamental LLM-driven data annotation methods in model development. While their combination significantly enhances the efficiency of model training and evaluation, little attention has been given to the potential contamination brought by this new model development paradigm. In this work, we expose preference leakage, a contamination problem in LLM-as-a-judge caused by the relatedness between the synthetic data generators and LLM-based evaluators. To study this issue, we first define three common relatednesses between data generator LLM and judge LLM: being the same model, having an inheritance relationship, and belonging to the same model family. Through extensive experiments, we empirically confirm the bias of judges towards their related student models caused by preference leakage across multiple LLM baselines and benchmarks. Further analysis suggests that preference leakage is a pervasive issue that is harder to detect compared to previously identified biases in LLM-as-a-judge scenarios. All of these findings imply that preference leakage is a widespread and challenging problem in the area of LLM-as-a-judge. We release all codes and data at: https://github.com/David-Li0406/Preference-Leakage.
Assessing the Impact of Conspiracy Theories Using Large Language Models
Dec 09, 2024Measuring the relative impact of CTs is important for prioritizing responses and allocating resources effectively, especially during crises. However, assessing the actual impact of CTs on the public poses unique challenges. It requires not only the collection of CT-specific knowledge but also diverse information from social, psychological, and cultural dimensions. Recent advancements in large language models (LLMs) suggest their potential utility in this context, not only due to their extensive knowledge from large training corpora but also because they can be harnessed for complex reasoning. In this work, we develop datasets of popular CTs with human-annotated impacts. Borrowing insights from human impact assessment processes, we then design tailored strategies to leverage LLMs for performing human-like CT impact assessments. Through rigorous experiments, we textit{discover that an impact assessment mode using multi-step reasoning to analyze more CT-related evidence critically produces accurate results; and most LLMs demonstrate strong bias, such as assigning higher impacts to CTs presented earlier in the prompt, while generating less accurate impact assessments for emotionally charged and verbose CTs.
From Generation to Judgment: Opportunities and Challenges of LLM-as-a-judge
Nov 25, 2024
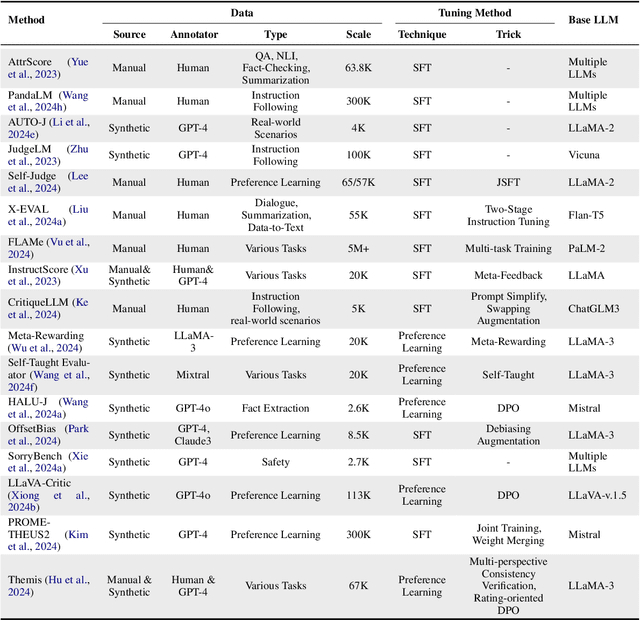
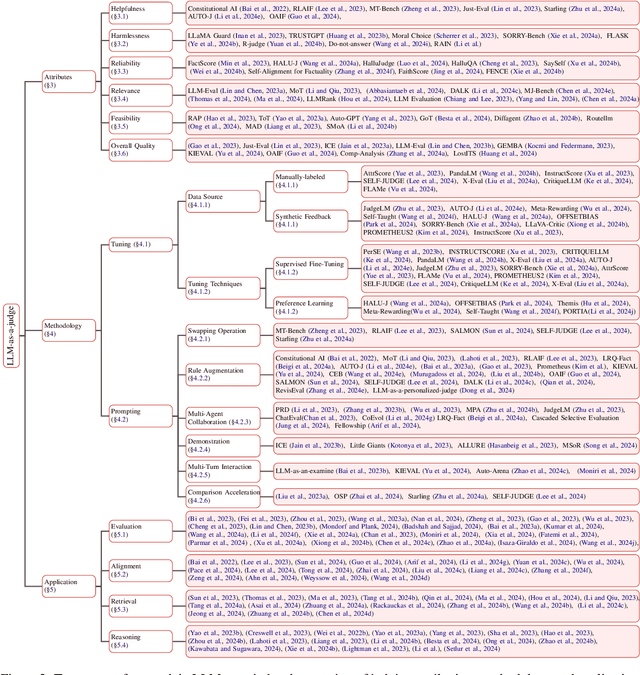
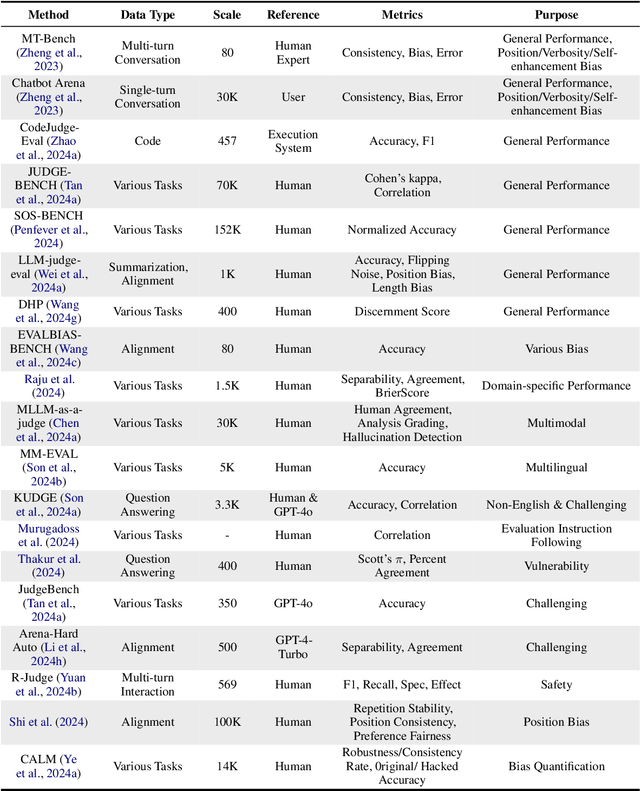
Assessment and evaluation have long been critical challenges in artificial intelligence (AI) and natural language processing (NLP). However, traditional methods, whether matching-based or embedding-based, often fall short of judging subtle attributes and delivering satisfactory results. Recent advancements in Large Language Models (LLMs) inspire the "LLM-as-a-judge" paradigm, where LLMs are leveraged to perform scoring, ranking, or selection across various tasks and applications. This paper provides a comprehensive survey of LLM-based judgment and assessment, offering an in-depth overview to advance this emerging field. We begin by giving detailed definitions from both input and output perspectives. Then we introduce a comprehensive taxonomy to explore LLM-as-a-judge from three dimensions: what to judge, how to judge and where to judge. Finally, we compile benchmarks for evaluating LLM-as-a-judge and highlight key challenges and promising directions, aiming to provide valuable insights and inspire future research in this promising research area. Paper list and more resources about LLM-as-a-judge can be found at \url{https://github.com/llm-as-a-judge/Awesome-LLM-as-a-judge} and \url{https://llm-as-a-judge.github.io}.
BPO: Towards Balanced Preference Optimization between Knowledge Breadth and Depth in Alignment
Nov 16, 2024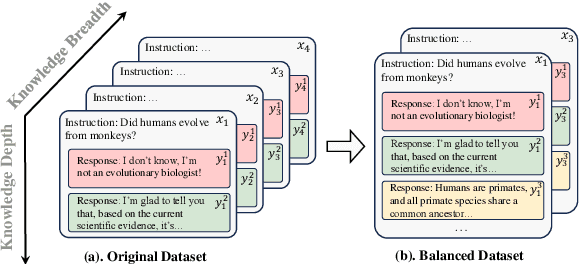
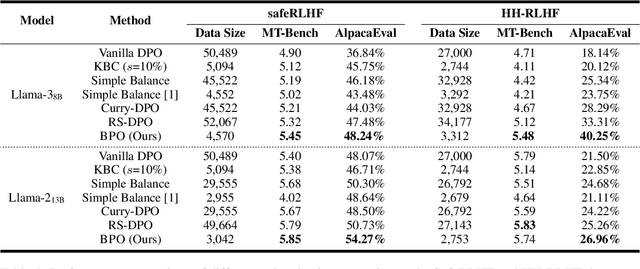
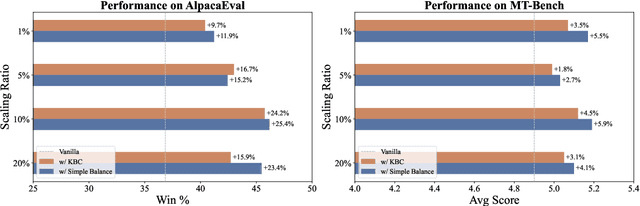
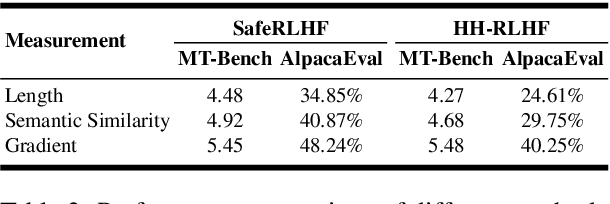
Reinforcement Learning with Human Feedback (RLHF) is the key to the success of large language models (LLMs) in recent years. In this work, we first introduce the concepts of knowledge breadth and knowledge depth, which measure the comprehensiveness and depth of an LLM or knowledge source respectively. We reveal that the imbalance in the number of prompts and responses can lead to a potential disparity in breadth and depth learning within alignment tuning datasets by showing that even a simple uniform method for balancing the number of instructions and responses can lead to significant improvements. Building on this, we further propose Balanced Preference Optimization (BPO), designed to dynamically augment the knowledge depth of each sample. BPO is motivated by the observation that the usefulness of knowledge varies across samples, necessitating tailored learning of knowledge depth. To achieve this, we introduce gradient-based clustering, estimating the knowledge informativeness and usefulness of each augmented sample based on the model's optimization direction. Our experimental results across various benchmarks demonstrate that BPO outperforms other baseline methods in alignment tuning while maintaining training efficiency. Furthermore, we conduct a detailed analysis of each component of BPO, providing guidelines for future research in preference data optimization.