 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessing the Impact of Conspiracy Theories Using Large Language Models
Dec 09, 2024Measuring the relative impact of CTs is important for prioritizing responses and allocating resources effectively, especially during crises. However, assessing the actual impact of CTs on the public poses unique challenges. It requires not only the collection of CT-specific knowledge but also diverse information from social, psychological, and cultural dimensions. Recent advancements in large language models (LLMs) suggest their potential utility in this context, not only due to their extensive knowledge from large training corpora but also because they can be harnessed for complex reasoning. In this work, we develop datasets of popular CTs with human-annotated impacts. Borrowing insights from human impact assessment processes, we then design tailored strategies to leverage LLMs for performing human-like CT impact assessments. Through rigorous experiments, we textit{discover that an impact assessment mode using multi-step reasoning to analyze more CT-related evidence critically produces accurate results; and most LLMs demonstrate strong bias, such as assigning higher impacts to CTs presented earlier in the prompt, while generating less accurate impact assessments for emotionally charged and verbose CTs.
BlueTempNet: A Temporal Multi-network Dataset of Social Interactions in Bluesky Social
Jul 24, 2024Decentralized social media platforms like Bluesky Social (Bluesky) have made it possible to publicly disclose some user behaviors with millisecond-level precision. Embracing Bluesky's principles of open-source and open-data, we present the first collection of the temporal dynamics of user-driven social interactions. BlueTempNet integrates multiple types of networks into a single multi-network, including user-to-user interactions (following and blocking users) and user-to-community interactions (creating and joining communities). Communities are user-formed groups in custom Feeds, where users subscribe to posts aligned with their interests. Following Bluesky's public data policy, we collect existing Bluesky Feeds, including the users who liked and generated these Feeds, and provide tools to gather users' social interactions within a date range. This data-collection strategy captures past user behaviors and supports the future data collection of user behavior.
Characterizing Multi-Domain False News and Underlying User Effects on Chinese Weibo
May 06, 2022
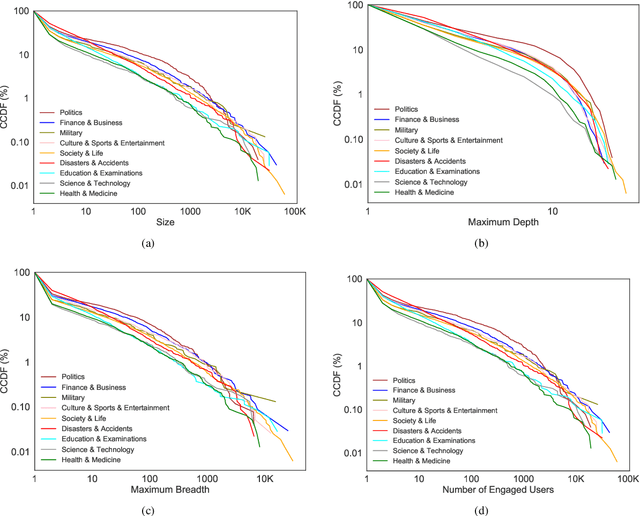
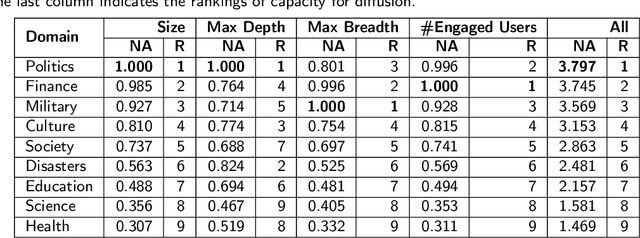
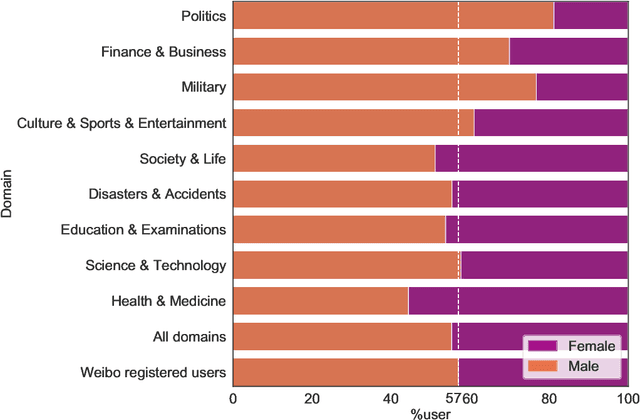
False news that spreads on social media has proliferated over the past years and has led to multi-aspect threats in the real world. While there are studies of false news on specific domains (like politics or health care), little work is found comparing false news across domains. In this article, we investigate false news across nine domains on Weibo, the largest Twitter-like social media platform in China, from 2009 to 2019. The newly collected data comprise 44,728 posts in the nine domains, published by 40,215 users, and reposted over 3.4 million times. Based on the distributions and spreads of the multi-domain dataset, we observe that false news in domains that are close to daily life like health and medicine generated more posts but diffused less effectively than those in other domains like politics, and that political false news had the most effective capacity for diffusion. The widely diffused false news posts on Weibo were associated strongly with certain types of users -- by gender, age, etc. Further, these posts provoked strong emotions in the reposts and diffused further with the active engagement of false-news starters. Our findings have the potential to help design false news detection systems in suspicious news discovery, veracity prediction, and display and explanation. The comparison of the findings on Weibo with those of existing work demonstrates nuanced patterns, suggesting the need for more research on data from diverse platforms, countries, or languages to tackle the global issue of false news. The code and new anonymized dataset are available at https://github.com/ICTMCG/Characterizing-Weibo-Multi-Domain-False-News.