 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForewarned is Forearmed: Pre-Synthesizing Jailbreak-like Instructions to Enhance LLM Safety Guardrail to Potential Attacks
Aug 28, 2025Despite advances in improving large language model (LLM) to refuse to answer malicious instructions, widely used LLMs remain vulnerable to jailbreak attacks where attackers generate instructions with distributions differing from safety alignment corpora. New attacks expose LLMs' inability to recognize unseen malicious instructions, highlighting a critical distributional mismatch between training data and real-world attacks that forces developers into reactive patching cycles. To tackle this challenge, we propose IMAGINE, a synthesis framework that leverages embedding space distribution analysis to generate jailbreak-like instructions. This approach effectively fills the distributional gap between authentic jailbreak patterns and safety alignment corpora. IMAGINE follows an iterative optimization process that dynamically evolves text generation distributions across iterations, thereby augmenting the coverage of safety alignment data distributions through synthesized data examples. Based on the safety-aligned corpus enhanced through IMAGINE, our framework demonstrates significant decreases in attack success rate on Qwen2.5, Llama3.1, and Llama3.2 without compromising their utility.
PhantomHunter: Detecting Unseen Privately-Tuned LLM-Generated Text via Family-Aware Learning
Jun 18, 2025With the popularity of large language models (LLMs), undesirable societal problems like misinformation production and academic misconduct have been more severe, making LLM-generated text detection now of unprecedented importance. Although existing methods have made remarkable progress, a new challenge posed by text from privately tuned LLMs remains underexplored. Users could easily possess private LLMs by fine-tuning an open-source one with private corpora, resulting in a significant performance drop of existing detectors in practice. To address this issue, we propose PhantomHunter, an LLM-generated text detector specialized for detecting text from unseen, privately-tuned LLMs. Its family-aware learning framework captures family-level traits shared across the base models and their derivatives, instead of memorizing individual characteristics. Experiments on data from LLaMA, Gemma, and Mistral families show its superiority over 7 baselines and 3 industrial services, with F1 scores of over 96%.
From Judgment to Interference: Early Stopping LLM Harmful Outputs via Streaming Content Monitoring
Jun 11, 2025Though safety alignment has been applied to most large language models (LLMs), LLM service providers generally deploy a subsequent moderation as the external safety guardrail in real-world products. Existing moderators mainly practice a conventional full detection, which determines the harmfulness based on the complete LLM output, causing high service latency. Recent works pay more attention to partial detection where moderators oversee the generation midway and early stop the output if harmfulness is detected, but they directly apply moderators trained with the full detection paradigm to incomplete outputs, introducing a training-inference gap that lowers the performance. In this paper, we explore how to form a data-and-model solution that natively supports partial detection. For the data, we construct FineHarm, a dataset consisting of 29K prompt-response pairs with fine-grained annotations to provide reasonable supervision for token-level training. Then, we propose the streaming content monitor, which is trained with dual supervision of response- and token-level labels and can follow the output stream of LLM to make a timely judgment of harmfulness. Experiments show that SCM gains 0.95+ in macro F1 score that is comparable to full detection, by only seeing the first 18% of tokens in responses on average. Moreover, the SCM can serve as a pseudo-harmfulness annotator for improving safety alignment and lead to a higher harmlessness score than DPO.
Enhancing the Comprehensibility of Text Explanations via Unsupervised Concept Discovery
May 26, 2025Concept-based explainable approaches have emerged as a promising method in explainable AI because they can interpret models in a way that aligns with human reasoning. However, their adaption in the text domain remains limited. Most existing methods rely on predefined concept annotations and cannot discover unseen concepts, while other methods that extract concepts without supervision often produce explanations that are not intuitively comprehensible to humans, potentially diminishing user trust. These methods fall short of discovering comprehensible concepts automatically. To address this issue, we propose \textbf{ECO-Concept}, an intrinsically interpretable framework to discover comprehensible concepts with no concept annotations. ECO-Concept first utilizes an object-centric architecture to extract semantic concepts automatically. Then the comprehensibility of the extracted concepts is evaluated by large language models. Finally, the evaluation result guides the subsequent model fine-tuning to obtain more understandable explanations. Experiments show that our method achieves superior performance across diverse tasks. Further concept evaluations validate that the concepts learned by ECO-Concept surpassed current counterparts in comprehensibility.
The Staircase of Ethics: Probing LLM Value Priorities through Multi-Step Induction to Complex Moral Dilemmas
May 23, 2025Ethical decision-making is a critical aspect of human judgment, and the growing use of LLMs in decision-support systems necessitates a rigorous evaluation of their moral reasoning capabilities. However, existing assessments primarily rely on single-step evaluations, failing to capture how models adapt to evolving ethical challenges. Addressing this gap, we introduce the Multi-step Moral Dilemmas (MMDs), the first dataset specifically constructed to evaluate the evolving moral judgments of LLMs across 3,302 five-stage dilemmas. This framework enables a fine-grained, dynamic analysis of how LLMs adjust their moral reasoning across escalating dilemmas. Our evaluation of nine widely used LLMs reveals that their value preferences shift significantly as dilemmas progress, indicating that models recalibrate moral judgments based on scenario complexity. Furthermore, pairwise value comparisons demonstrate that while LLMs often prioritize the value of care, this value can sometimes be superseded by fairness in certain contexts, highlighting the dynamic and context-dependent nature of LLM ethical reasoning. Our findings call for a shift toward dynamic, context-aware evaluation paradigms, paving the way for more human-aligned and value-sensitive development of LLMs.
LLM-Generated Fake News Induces Truth Decay in News Ecosystem: A Case Study on Neural News Recommendation
Apr 29, 2025Online fake news moderation now faces a new challenge brought by the malicious use of large language models (LLMs) in fake news production. Though existing works have shown LLM-generated fake news is hard to detect from an individual aspect, it remains underexplored how its large-scale release will impact the news ecosystem. In this study, we develop a simulation pipeline and a dataset with ~56k generated news of diverse types to investigate the effects of LLM-generated fake news within neural news recommendation systems. Our findings expose a truth decay phenomenon, where real news is gradually losing its advantageous position in news ranking against fake news as LLM-generated news is involved in news recommendation. We further provide an explanation about why truth decay occurs from a familiarity perspective and show the positive correlation between perplexity and news ranking. Finally, we discuss the threats of LLM-generated fake news and provide possible countermeasures. We urge stakeholders to address this emerging challenge to preserve the integrity of news ecosystems.
Interactive Visual Assessment for Text-to-Image Generation Models
Nov 23, 2024Visual generation models have achieved remarkable progress in computer graphics applications but still face significant challenges in real-world deployment. Current assessment approaches for visual generation tasks typically follow an isolated three-phase framework: test input collection, model output generation, and user assessment. These fashions suffer from fixed coverage, evolving difficulty, and data leakage risks, limiting their effectiveness in comprehensively evaluating increasingly complex generation models. To address these limitations, we propose DyEval, an LLM-powered dynamic interactive visual assessment framework that facilitates collaborative evaluation between humans and generative models for text-to-image systems. DyEval features an intuitive visual interface that enables users to interactively explore and analyze model behaviors, while adaptively generating hierarchical, fine-grained, and diverse textual inputs to continuously probe the capability boundaries of the models based on their feedback. Additionally, to provide interpretable analysis for users to further improve tested models, we develop a contextual reflection module that mines failure triggers of test inputs and reflects model potential failure patterns supporting in-depth analysis using the logical reasoning ability of LLM. Qualitative and quantitative experiments demonstrate that DyEval can effectively help users identify max up to 2.56 times generation failures than conventional methods, and uncover complex and rare failure patterns, such as issues with pronoun generation and specific cultural context generation. Our framework provides valuable insights for improving generative models and has broad implications for advancing the reliability and capabilities of visual generation systems across various domains.
Vision-fused Attack: Advancing Aggressive and Stealthy Adversarial Text against Neural Machine Translation
Sep 08, 2024
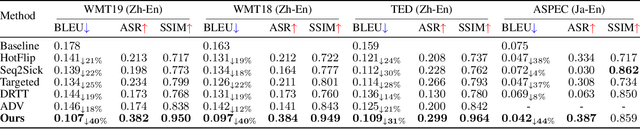
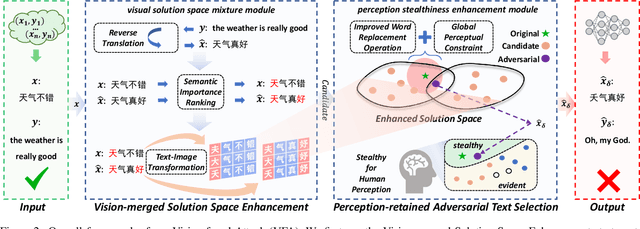
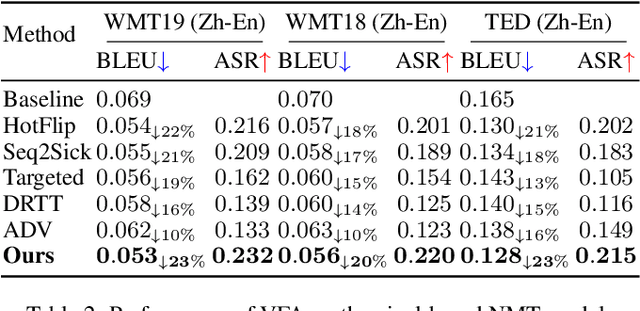
While neural machine translation (NMT) models achieve success in our daily lives, they show vulnerability to adversarial attacks. Despite being harmful, these attacks also offer benefits for interpreting and enhancing NMT models, thus drawing increased research attention. However, existing studies on adversarial attacks are insufficient in both attacking ability and human imperceptibility due to their sole focus on the scope of language. This paper proposes a novel vision-fused attack (VFA) framework to acquire powerful adversarial text, i.e., more aggressive and stealthy. Regarding the attacking ability, we design the vision-merged solution space enhancement strategy to enlarge the limited semantic solution space, which enables us to search for adversarial candidates with higher attacking ability. For human imperceptibility, we propose the perception-retained adversarial text selection strategy to align the human text-reading mechanism. Thus, the finally selected adversarial text could be more deceptive. Extensive experiments on various models, including large language models (LLMs) like LLaMA and GPT-3.5, strongly support that VFA outperforms the comparisons by large margins (up to 81%/14% improvements on ASR/SSIM).
FakingRecipe: Detecting Fake News on Short Video Platforms from the Perspective of Creative Process
Jul 23, 2024

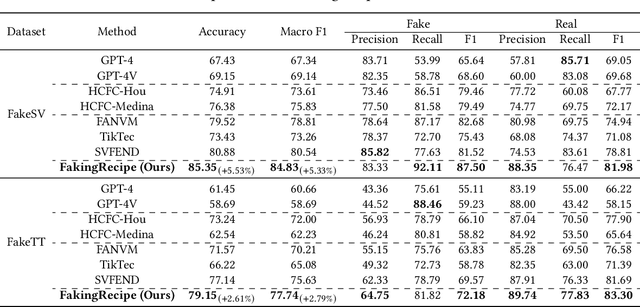
As short-form video-sharing platforms become a significant channel for news consumption, fake news in short videos has emerged as a serious threat in the online information ecosystem, making developing detection methods for this new scenario an urgent need. Compared with that in text and image formats, fake news on short video platforms contains rich but heterogeneous information in various modalities, posing a challenge to effective feature utilization. Unlike existing works mostly focusing on analyzing what is presented, we introduce a novel perspective that considers how it might be created. Through the lens of the creative process behind news video production, our empirical analysis uncovers the unique characteristics of fake news videos in material selection and editing. Based on the obtained insights, we design FakingRecipe, a creative process-aware model for detecting fake news short videos. It captures the fake news preferences in material selection from sentimental and semantic aspects and considers the traits of material editing from spatial and temporal aspects. To improve evaluation comprehensiveness, we first construct FakeTT, an English dataset for this task, and conduct experiments on both FakeTT and the existing Chinese FakeSV dataset. The results show FakingRecipe's superiority in detecting fake news on short video platforms.
Let Silence Speak: Enhancing Fake News Detection with Generated Comments from Large Language Models
May 26, 2024



Fake news detection plays a crucial role in protecting social media users and maintaining a healthy news ecosystem. Among existing works, comment-based fake news detection methods are empirically shown as promising because comments could reflect users' opinions, stances, and emotions and deepen models' understanding of fake news. Unfortunately, due to exposure bias and users' different willingness to comment, it is not easy to obtain diverse comments in reality, especially for early detection scenarios. Without obtaining the comments from the ``silent'' users, the perceived opinions may be incomplete, subsequently affecting news veracity judgment. In this paper, we explore the possibility of finding an alternative source of comments to guarantee the availability of diverse comments, especially those from silent users. Specifically, we propose to adopt large language models (LLMs) as a user simulator and comment generator, and design GenFEND, a generated feedback-enhanced detection framework, which generates comments by prompting LLMs with diverse user profiles and aggregating generated comments from multiple subpopulation groups. Experiments demonstrate the effectiveness of GenFEND and further analysis shows that the generated comments cover more diverse users and could even be more effective than actual comments.