 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLet Silence Speak: Enhancing Fake News Detection with Generated Comments from Large Language Models
May 26, 2024



Fake news detection plays a crucial role in protecting social media users and maintaining a healthy news ecosystem. Among existing works, comment-based fake news detection methods are empirically shown as promising because comments could reflect users' opinions, stances, and emotions and deepen models' understanding of fake news. Unfortunately, due to exposure bias and users' different willingness to comment, it is not easy to obtain diverse comments in reality, especially for early detection scenarios. Without obtaining the comments from the ``silent'' users, the perceived opinions may be incomplete, subsequently affecting news veracity judgment. In this paper, we explore the possibility of finding an alternative source of comments to guarantee the availability of diverse comments, especially those from silent users. Specifically, we propose to adopt large language models (LLMs) as a user simulator and comment generator, and design GenFEND, a generated feedback-enhanced detection framework, which generates comments by prompting LLMs with diverse user profiles and aggregating generated comments from multiple subpopulation groups. Experiments demonstrate the effectiveness of GenFEND and further analysis shows that the generated comments cover more diverse users and could even be more effective than actual comments.
Exploiting User Comments for Early Detection of Fake News Prior to Users' Commenting
Oct 16, 2023



Both accuracy and timeliness are key factors in detecting fake news on social media. However, most existing methods encounter an accuracy-timeliness dilemma: Content-only methods guarantee timeliness but perform moderately because of limited available information, while social context-based ones generally perform better but inevitably lead to latency because of social context accumulation needs. To break such a dilemma, a feasible but not well-studied solution is to leverage social contexts (e.g., comments) from historical news for training a detection model and apply it to newly emerging news without social contexts. This requires the model to (1) sufficiently learn helpful knowledge from social contexts, and (2) be well compatible with situations that social contexts are available or not. To achieve this goal, we propose to absorb and parameterize useful knowledge from comments in historical news and then inject it into a content-only detection model. Specifically, we design the Comments Assisted Fake News Detection method (CAS-FEND), which transfers useful knowledge from a comments-aware teacher model to a content-only student model during training. The student model is further used to detect newly emerging fake news. Experiments show that the CAS-FEND student model outperforms all content-only methods and even those with 1/4 comments as inputs, demonstrating its superiority for early detection.
Improving Fake News Detection of Influential Domain via Domain- and Instance-Level Transfer
Oct 09, 2022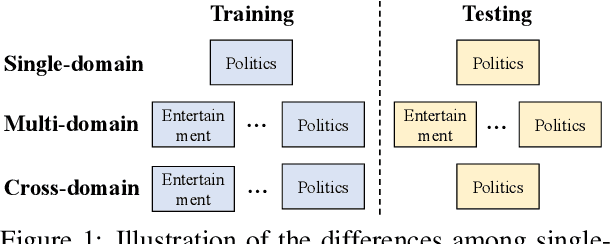
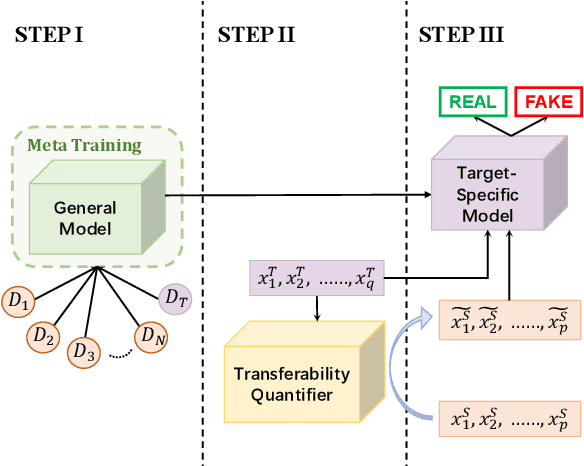
Both real and fake news in various domains, such as politics, health, and entertainment are spread via online social media every day, necessitating fake news detection for multiple domains. Among them, fake news in specific domains like politics and health has more serious potential negative impacts on the real world (e.g., the infodemic led by COVID-19 misinformation). Previous studies focus on multi-domain fake news detection, by equally mining and modeling the correlation between domains. However, these multi-domain methods suffer from a seesaw problem: the performance of some domains is often improved at the cost of hurting the performance of other domains, which could lead to an unsatisfying performance in specific domains. To address this issue, we propose a Domain- and Instance-level Transfer Framework for Fake News Detection (DITFEND), which could improve the performance of specific target domains. To transfer coarse-grained domain-level knowledge, we train a general model with data of all domains from the meta-learning perspective. To transfer fine-grained instance-level knowledge and adapt the general model to a target domain, we train a language model on the target domain to evaluate the transferability of each data instance in source domains and re-weigh each instance's contribution. Offline experiments on two datasets demonstrate the effectiveness of DITFEND. Online experiments show that DITFEND brings additional improvements over the base models in a real-world scenario.
Memory-Guided Multi-View Multi-Domain Fake News Detection
Jun 26, 2022


The wide spread of fake news is increasingly threatening both individuals and society. Great efforts have been made for automatic fake news detection on a single domain (e.g., politics). However, correlations exist commonly across multiple news domains, and thus it is promising to simultaneously detect fake news of multiple domains. Based on our analysis, we pose two challenges in multi-domain fake news detection: 1) domain shift, caused by the discrepancy among domains in terms of words, emotions, styles, etc. 2) domain labeling incompleteness, stemming from the real-world categorization that only outputs one single domain label, regardless of topic diversity of a news piece. In this paper, we propose a Memory-guided Multi-view Multi-domain Fake News Detection Framework (M$^3$FEND) to address these two challenges. We model news pieces from a multi-view perspective, including semantics, emotion, and style. Specifically, we propose a Domain Memory Bank to enrich domain information which could discover potential domain labels based on seen news pieces and model domain characteristics. Then, with enriched domain information as input, a Domain Adapter could adaptively aggregate discriminative information from multiple views for news in various domains. Extensive offline experiments on English and Chinese datasets demonstrate the effectiveness of M$^3$FEND, and online tests verify its superiority in practice. Our code is available at https://github.com/ICTMCG/M3FEND.
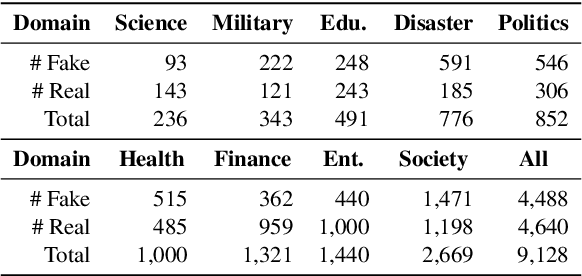
MDFEND: Multi-domain Fake News Detection
Jan 04, 2022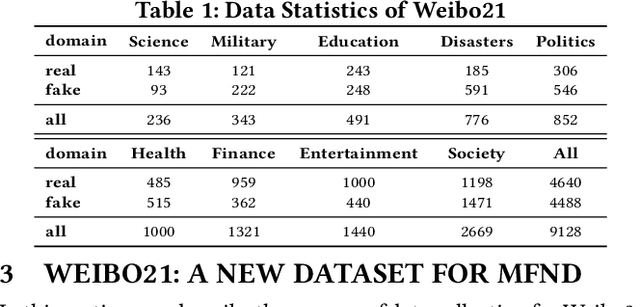

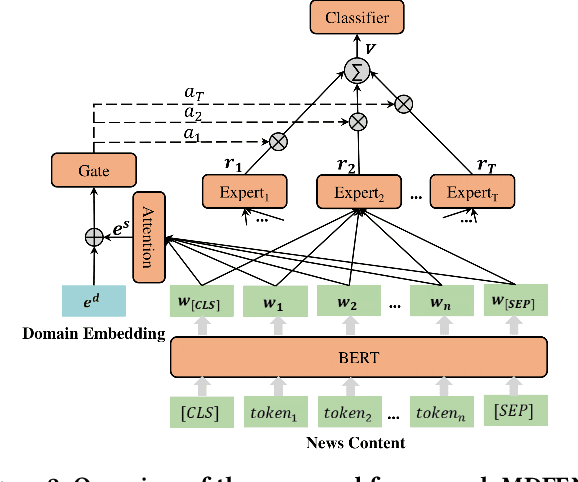
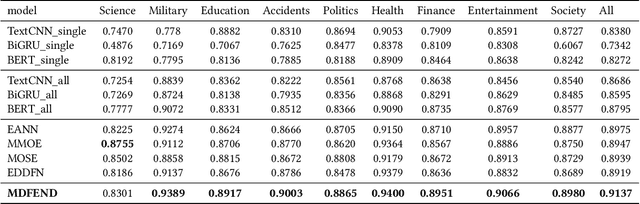
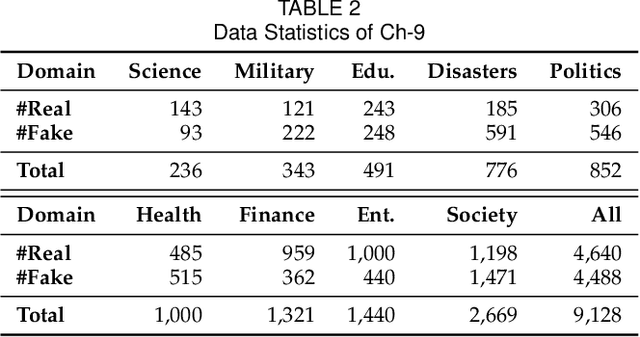
Fake news spread widely on social media in various domains, which lead to real-world threats in many aspects like politics, disasters, and finance. Most existing approaches focus on single-domain fake news detection (SFND), which leads to unsatisfying performance when these methods are applied to multi-domain fake news detection. As an emerging field, multi-domain fake news detection (MFND) is increasingly attracting attention. However, data distributions, such as word frequency and propagation patterns, vary from domain to domain, namely domain shift. Facing the challenge of serious domain shift, existing fake news detection techniques perform poorly for multi-domain scenarios. Therefore, it is demanding to design a specialized model for MFND. In this paper, we first design a benchmark of fake news dataset for MFND with domain label annotated, namely Weibo21, which consists of 4,488 fake news and 4,640 real news from 9 different domains. We further propose an effective Multi-domain Fake News Detection Model (MDFEND) by utilizing a domain gate to aggregate multiple representations extracted by a mixture of experts. The experiments show that MDFEND can significantly improve the performance of multi-domain fake news detection. Our dataset and code are available at https://github.com/kennqiang/MDFEND-Weibo21.