 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTAG-MoE: Task-Aware Gating for Unified Generative Mixture-of-Experts
Jan 12, 2026Unified image generation and editing models suffer from severe task interference in dense diffusion transformers architectures, where a shared parameter space must compromise between conflicting objectives (e.g., local editing v.s. subject-driven generation). While the sparse Mixture-of-Experts (MoE) paradigm is a promising solution, its gating networks remain task-agnostic, operating based on local features, unaware of global task intent. This task-agnostic nature prevents meaningful specialization and fails to resolve the underlying task interference. In this paper, we propose a novel framework to inject semantic intent into MoE routing. We introduce a Hierarchical Task Semantic Annotation scheme to create structured task descriptors (e.g., scope, type, preservation). We then design Predictive Alignment Regularization to align internal routing decisions with the task's high-level semantics. This regularization evolves the gating network from a task-agnostic executor to a dispatch center. Our model effectively mitigates task interference, outperforming dense baselines in fidelity and quality, and our analysis shows that experts naturally develop clear and semantically correlated specializations.
Hybrid Quantum-Classical Neural Networks for Few-Shot Credit Risk Assessment
Sep 17, 2025Quantum Machine Learning (QML) offers a new paradigm for addressing complex financial problems intractable for classical methods. This work specifically tackles the challenge of few-shot credit risk assessment, a critical issue in inclusive finance where data scarcity and imbalance limit the effectiveness of conventional models. To address this, we design and implement a novel hybrid quantum-classical workflow. The methodology first employs an ensemble of classical machine learning models (Logistic Regression, Random Forest, XGBoost) for intelligent feature engineering and dimensionality reduction. Subsequently, a Quantum Neural Network (QNN), trained via the parameter-shift rule, serves as the core classifier. This framework was evaluated through numerical simulations and deployed on the Quafu Quantum Cloud Platform's ScQ-P21 superconducting processor. On a real-world credit dataset of 279 samples, our QNN achieved a robust average AUC of 0.852 +/- 0.027 in simulations and yielded an impressive AUC of 0.88 in the hardware experiment. This performance surpasses a suite of classical benchmarks, with a particularly strong result on the recall metric. This study provides a pragmatic blueprint for applying quantum computing to data-constrained financial scenarios in the NISQ era and offers valuable empirical evidence supporting its potential in high-stakes applications like inclusive finance.
Enhancing the Comprehensibility of Text Explanations via Unsupervised Concept Discovery
May 26, 2025Concept-based explainable approaches have emerged as a promising method in explainable AI because they can interpret models in a way that aligns with human reasoning. However, their adaption in the text domain remains limited. Most existing methods rely on predefined concept annotations and cannot discover unseen concepts, while other methods that extract concepts without supervision often produce explanations that are not intuitively comprehensible to humans, potentially diminishing user trust. These methods fall short of discovering comprehensible concepts automatically. To address this issue, we propose \textbf{ECO-Concept}, an intrinsically interpretable framework to discover comprehensible concepts with no concept annotations. ECO-Concept first utilizes an object-centric architecture to extract semantic concepts automatically. Then the comprehensibility of the extracted concepts is evaluated by large language models. Finally, the evaluation result guides the subsequent model fine-tuning to obtain more understandable explanations. Experiments show that our method achieves superior performance across diverse tasks. Further concept evaluations validate that the concepts learned by ECO-Concept surpassed current counterparts in comprehensibility.
In-Context Brush: Zero-shot Customized Subject Insertion with Context-Aware Latent Space Manipulation
May 26, 2025Recent advances in diffusion models have enhanced multimodal-guided visual generation, enabling customized subject insertion that seamlessly "brushes" user-specified objects into a given image guided by textual prompts. However, existing methods often struggle to insert customized subjects with high fidelity and align results with the user's intent through textual prompts. In this work, we propose "In-Context Brush", a zero-shot framework for customized subject insertion by reformulating the task within the paradigm of in-context learning. Without loss of generality, we formulate the object image and the textual prompts as cross-modal demonstrations, and the target image with the masked region as the query. The goal is to inpaint the target image with the subject aligning textual prompts without model tuning. Building upon a pretrained MMDiT-based inpainting network, we perform test-time enhancement via dual-level latent space manipulation: intra-head "latent feature shifting" within each attention head that dynamically shifts attention outputs to reflect the desired subject semantics and inter-head "attention reweighting" across different heads that amplifies prompt controllability through differential attention prioritization. Extensive experiments and applications demonstrate that our approach achieves superior identity preservation, text alignment, and image quality compared to existing state-of-the-art methods, without requiring dedicated training or additional data collection.
On the workflow, opportunities and challenges of developing foundation model in geophysics
Apr 24, 2025Foundation models, as a mainstream technology in artificial intelligence, have demonstrated immense potential across various domains in recent years, particularly in handling complex tasks and multimodal data. In the field of geophysics, although the application of foundation models is gradually expanding, there is currently a lack of comprehensive reviews discussing the full workflow of integrating foundation models with geophysical data. To address this gap, this paper presents a complete framework that systematically explores the entire process of developing foundation models in conjunction with geophysical data. From data collection and preprocessing to model architecture selection, pre-training strategies, and model deployment, we provide a detailed analysis of the key techniques and methodologies at each stage. In particular, considering the diversity, complexity, and physical consistency constraints of geophysical data, we discuss targeted solutions to address these challenges. Furthermore, we discuss how to leverage the transfer learning capabilities of foundation models to reduce reliance on labeled data, enhance computational efficiency, and incorporate physical constraints into model training, thereby improving physical consistency and interpretability. Through a comprehensive summary and analysis of the current technological landscape, this paper not only fills the gap in the geophysics domain regarding a full-process review of foundation models but also offers valuable practical guidance for their application in geophysical data analysis, driving innovation and advancement in the field.
CMEdataset Advancing China Map Detection and Standardization with Digital Image Resources
Apr 10, 2025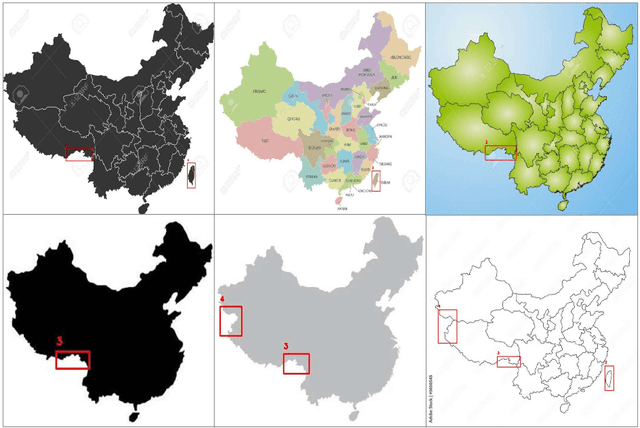


Digital images of Chinas maps play a crucial role in map detection, particularly in ensuring national sovereignty, territorial integrity, and map compliance. However, there is currently no publicly available dataset specifically dedicated to problematic maps the CME dataset. Existing datasets primarily focus on general map data and are insufficient for effectively identifying complex issues such as national boundary misrepresentations, missing elements, and blurred boundaries. Therefore, this study creates a Problematic Map dataset that covers five key problem areas, aiming to provide diverse samples for problematic map detection technologies, support high-precision map compliance detection, and enhance map data quality and timeliness. This dataset not only provides essential resources for map compliance, national security monitoring, and map updates, but also fosters innovation and application of related technologies.
AnchorCrafter: Animate CyberAnchors Saling Your Products via Human-Object Interacting Video Generation
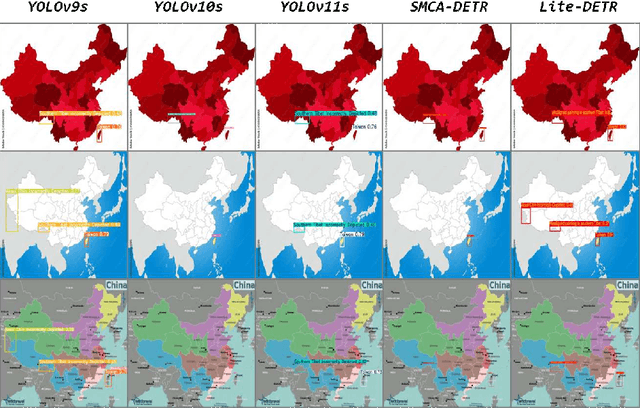
Nov 26, 2024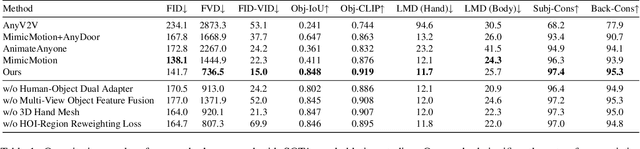

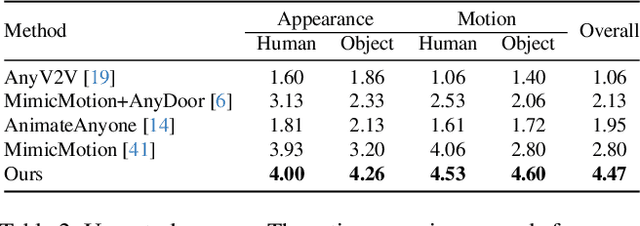
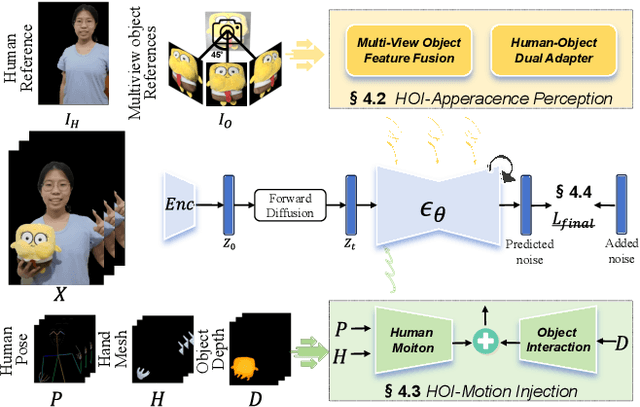
The automatic generation of anchor-style product promotion videos presents promising opportunities in online commerce, advertising, and consumer engagement. However, this remains a challenging task despite significant advancements in pose-guided human video generation. In addressing this challenge, we identify the integration of human-object interactions (HOI) into pose-guided human video generation as a core issue. To this end, we introduce AnchorCrafter, a novel diffusion-based system designed to generate 2D videos featuring a target human and a customized object, achieving high visual fidelity and controllable interactions. Specifically, we propose two key innovations: the HOI-appearance perception, which enhances object appearance recognition from arbitrary multi-view perspectives and disentangles object and human appearance, and the HOI-motion injection, which enables complex human-object interactions by overcoming challenges in object trajectory conditioning and inter-occlusion management. Additionally, we introduce the HOI-region reweighting loss, a training objective that enhances the learning of object details. Extensive experiments demonstrate that our proposed system outperforms existing methods in preserving object appearance and shape awareness, while simultaneously maintaining consistency in human appearance and motion. Project page: https://cangcz.github.io/Anchor-Crafter/
HeadRouter: A Training-free Image Editing Framework for MM-DiTs by Adaptively Routing Attention Heads
Nov 22, 2024



Diffusion Transformers (DiTs) have exhibited robust capabilities in image generation tasks. However, accurate text-guided image editing for multimodal DiTs (MM-DiTs) still poses a significant challenge. Unlike UNet-based structures that could utilize self/cross-attention maps for semantic editing, MM-DiTs inherently lack support for explicit and consistent incorporated text guidance, resulting in semantic misalignment between the edited results and texts. In this study, we disclose the sensitivity of different attention heads to different image semantics within MM-DiTs and introduce HeadRouter, a training-free image editing framework that edits the source image by adaptively routing the text guidance to different attention heads in MM-DiTs. Furthermore, we present a dual-token refinement module to refine text/image token representations for precise semantic guidance and accurate region expression. Experimental results on multiple benchmarks demonstrate HeadRouter's performance in terms of editing fidelity and image quality.
FakingRecipe: Detecting Fake News on Short Video Platforms from the Perspective of Creative Process
Jul 23, 2024

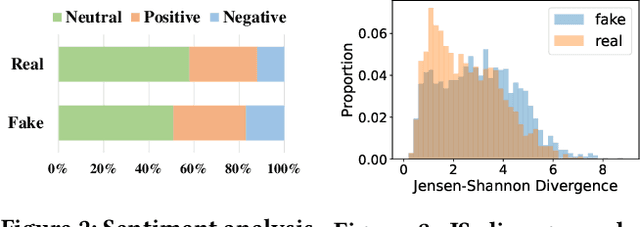
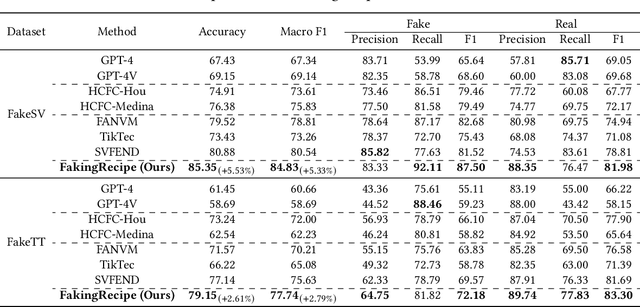
As short-form video-sharing platforms become a significant channel for news consumption, fake news in short videos has emerged as a serious threat in the online information ecosystem, making developing detection methods for this new scenario an urgent need. Compared with that in text and image formats, fake news on short video platforms contains rich but heterogeneous information in various modalities, posing a challenge to effective feature utilization. Unlike existing works mostly focusing on analyzing what is presented, we introduce a novel perspective that considers how it might be created. Through the lens of the creative process behind news video production, our empirical analysis uncovers the unique characteristics of fake news videos in material selection and editing. Based on the obtained insights, we design FakingRecipe, a creative process-aware model for detecting fake news short videos. It captures the fake news preferences in material selection from sentimental and semantic aspects and considers the traits of material editing from spatial and temporal aspects. To improve evaluation comprehensiveness, we first construct FakeTT, an English dataset for this task, and conduct experiments on both FakeTT and the existing Chinese FakeSV dataset. The results show FakingRecipe's superiority in detecting fake news on short video platforms.
Let Silence Speak: Enhancing Fake News Detection with Generated Comments from Large Language Models
May 26, 2024



Fake news detection plays a crucial role in protecting social media users and maintaining a healthy news ecosystem. Among existing works, comment-based fake news detection methods are empirically shown as promising because comments could reflect users' opinions, stances, and emotions and deepen models' understanding of fake news. Unfortunately, due to exposure bias and users' different willingness to comment, it is not easy to obtain diverse comments in reality, especially for early detection scenarios. Without obtaining the comments from the ``silent'' users, the perceived opinions may be incomplete, subsequently affecting news veracity judgment. In this paper, we explore the possibility of finding an alternative source of comments to guarantee the availability of diverse comments, especially those from silent users. Specifically, we propose to adopt large language models (LLMs) as a user simulator and comment generator, and design GenFEND, a generated feedback-enhanced detection framework, which generates comments by prompting LLMs with diverse user profiles and aggregating generated comments from multiple subpopulation groups. Experiments demonstrate the effectiveness of GenFEND and further analysis shows that the generated comments cover more diverse users and could even be more effective than actual comments.