 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaking Avatars Interact: Towards Text-Driven Human-Object Interaction for Controllable Talking Avatars
Feb 02, 2026Generating talking avatars is a fundamental task in video generation. Although existing methods can generate full-body talking avatars with simple human motion, extending this task to grounded human-object interaction (GHOI) remains an open challenge, requiring the avatar to perform text-aligned interactions with surrounding objects. This challenge stems from the need for environmental perception and the control-quality dilemma in GHOI generation. To address this, we propose a novel dual-stream framework, InteractAvatar, which decouples perception and planning from video synthesis for grounded human-object interaction. Leveraging detection to enhance environmental perception, we introduce a Perception and Interaction Module (PIM) to generate text-aligned interaction motions. Additionally, an Audio-Interaction Aware Generation Module (AIM) is proposed to synthesize vivid talking avatars performing object interactions. With a specially designed motion-to-video aligner, PIM and AIM share a similar network structure and enable parallel co-generation of motions and plausible videos, effectively mitigating the control-quality dilemma. Finally, we establish a benchmark, GroundedInter, for evaluating GHOI video generation. Extensive experiments and comparisons demonstrate the effectiveness of our method in generating grounded human-object interactions for talking avatars. Project page: https://interactavatar.github.io
HunyuanVideo-HOMA: Generic Human-Object Interaction in Multimodal Driven Human Animation
Jun 10, 2025To address key limitations in human-object interaction (HOI) video generation -- specifically the reliance on curated motion data, limited generalization to novel objects/scenarios, and restricted accessibility -- we introduce HunyuanVideo-HOMA, a weakly conditioned multimodal-driven framework. HunyuanVideo-HOMA enhances controllability and reduces dependency on precise inputs through sparse, decoupled motion guidance. It encodes appearance and motion signals into the dual input space of a multimodal diffusion transformer (MMDiT), fusing them within a shared context space to synthesize temporally consistent and physically plausible interactions. To optimize training, we integrate a parameter-space HOI adapter initialized from pretrained MMDiT weights, preserving prior knowledge while enabling efficient adaptation, and a facial cross-attention adapter for anatomically accurate audio-driven lip synchronization. Extensive experiments confirm state-of-the-art performance in interaction naturalness and generalization under weak supervision. Finally, HunyuanVideo-HOMA demonstrates versatility in text-conditioned generation and interactive object manipulation, supported by a user-friendly demo interface. The project page is at https://anonymous.4open.science/w/homa-page-0FBE/.
HunyuanVideo-Avatar: High-Fidelity Audio-Driven Human Animation for Multiple Characters
May 26, 2025Recent years have witnessed significant progress in audio-driven human animation. However, critical challenges remain in (i) generating highly dynamic videos while preserving character consistency, (ii) achieving precise emotion alignment between characters and audio, and (iii) enabling multi-character audio-driven animation. To address these challenges, we propose HunyuanVideo-Avatar, a multimodal diffusion transformer (MM-DiT)-based model capable of simultaneously generating dynamic, emotion-controllable, and multi-character dialogue videos. Concretely, HunyuanVideo-Avatar introduces three key innovations: (i) A character image injection module is designed to replace the conventional addition-based character conditioning scheme, eliminating the inherent condition mismatch between training and inference. This ensures the dynamic motion and strong character consistency; (ii) An Audio Emotion Module (AEM) is introduced to extract and transfer the emotional cues from an emotion reference image to the target generated video, enabling fine-grained and accurate emotion style control; (iii) A Face-Aware Audio Adapter (FAA) is proposed to isolate the audio-driven character with latent-level face mask, enabling independent audio injection via cross-attention for multi-character scenarios. These innovations empower HunyuanVideo-Avatar to surpass state-of-the-art methods on benchmark datasets and a newly proposed wild dataset, generating realistic avatars in dynamic, immersive scenarios.
CALM: Co-evolution of Algorithms and Language Model for Automatic Heuristic Design
May 18, 2025Tackling complex optimization problems often relies on expert-designed heuristics, typically crafted through extensive trial and error. Recent advances demonstrate that large language models (LLMs), when integrated into well-designed evolutionary search frameworks, can autonomously discover high-performing heuristics at a fraction of the traditional cost. However, existing approaches predominantly rely on verbal guidance, i.e., manipulating the prompt generation process, to steer the evolution of heuristics, without adapting the underlying LLM. We propose a hybrid framework that combines verbal and numerical guidance, the latter achieved by fine-tuning the LLM via reinforcement learning based on the quality of generated heuristics. This joint optimization allows the LLM to co-evolve with the search process. Our method outperforms state-of-the-art (SOTA) baselines across various optimization tasks, running locally on a single 24GB GPU using a 7B model with INT4 quantization. It surpasses methods that rely solely on verbal guidance, even when those use significantly more powerful API-based models.
AnchorCrafter: Animate CyberAnchors Saling Your Products via Human-Object Interacting Video Generation
Nov 26, 2024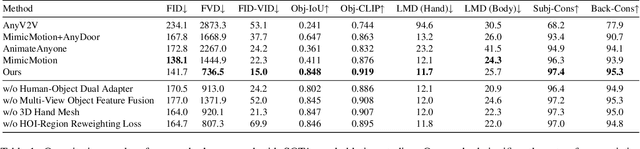

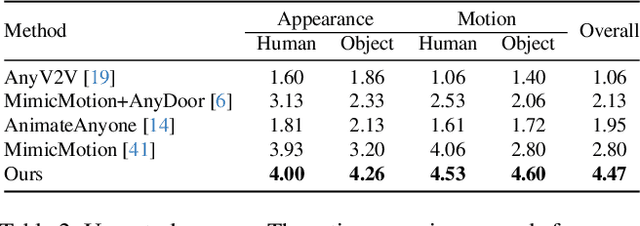
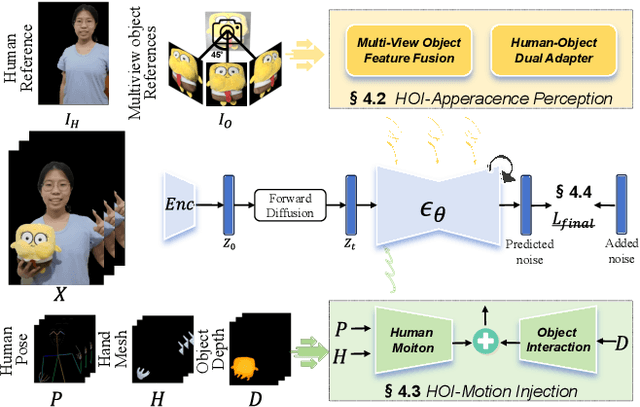
The automatic generation of anchor-style product promotion videos presents promising opportunities in online commerce, advertising, and consumer engagement. However, this remains a challenging task despite significant advancements in pose-guided human video generation. In addressing this challenge, we identify the integration of human-object interactions (HOI) into pose-guided human video generation as a core issue. To this end, we introduce AnchorCrafter, a novel diffusion-based system designed to generate 2D videos featuring a target human and a customized object, achieving high visual fidelity and controllable interactions. Specifically, we propose two key innovations: the HOI-appearance perception, which enhances object appearance recognition from arbitrary multi-view perspectives and disentangles object and human appearance, and the HOI-motion injection, which enables complex human-object interactions by overcoming challenges in object trajectory conditioning and inter-occlusion management. Additionally, we introduce the HOI-region reweighting loss, a training objective that enhances the learning of object details. Extensive experiments demonstrate that our proposed system outperforms existing methods in preserving object appearance and shape awareness, while simultaneously maintaining consistency in human appearance and motion. Project page: https://cangcz.github.io/Anchor-Crafter/
Interactive Visual Assessment for Text-to-Image Generation Models
Nov 23, 2024Visual generation models have achieved remarkable progress in computer graphics applications but still face significant challenges in real-world deployment. Current assessment approaches for visual generation tasks typically follow an isolated three-phase framework: test input collection, model output generation, and user assessment. These fashions suffer from fixed coverage, evolving difficulty, and data leakage risks, limiting their effectiveness in comprehensively evaluating increasingly complex generation models. To address these limitations, we propose DyEval, an LLM-powered dynamic interactive visual assessment framework that facilitates collaborative evaluation between humans and generative models for text-to-image systems. DyEval features an intuitive visual interface that enables users to interactively explore and analyze model behaviors, while adaptively generating hierarchical, fine-grained, and diverse textual inputs to continuously probe the capability boundaries of the models based on their feedback. Additionally, to provide interpretable analysis for users to further improve tested models, we develop a contextual reflection module that mines failure triggers of test inputs and reflects model potential failure patterns supporting in-depth analysis using the logical reasoning ability of LLM. Qualitative and quantitative experiments demonstrate that DyEval can effectively help users identify max up to 2.56 times generation failures than conventional methods, and uncover complex and rare failure patterns, such as issues with pronoun generation and specific cultural context generation. Our framework provides valuable insights for improving generative models and has broad implications for advancing the reliability and capabilities of visual generation systems across various domains.
Make-Your-Anchor: A Diffusion-based 2D Avatar Generation Framework
Mar 25, 2024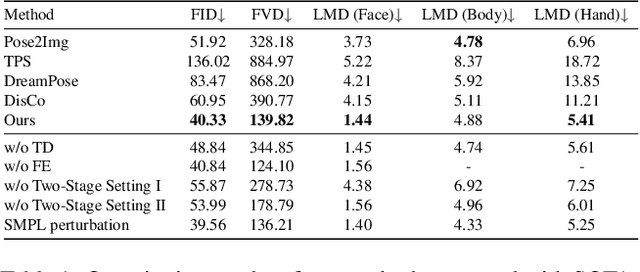
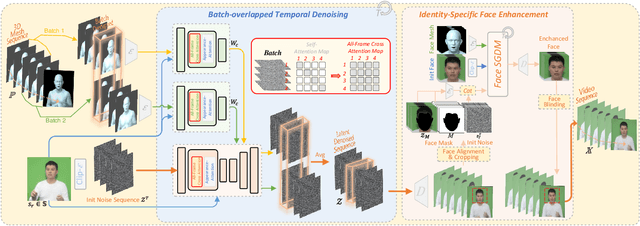


Despite the remarkable process of talking-head-based avatar-creating solutions, directly generating anchor-style videos with full-body motions remains challenging. In this study, we propose Make-Your-Anchor, a novel system necessitating only a one-minute video clip of an individual for training, subsequently enabling the automatic generation of anchor-style videos with precise torso and hand movements. Specifically, we finetune a proposed structure-guided diffusion model on input video to render 3D mesh conditions into human appearances. We adopt a two-stage training strategy for the diffusion model, effectively binding movements with specific appearances. To produce arbitrary long temporal video, we extend the 2D U-Net in the frame-wise diffusion model to a 3D style without additional training cost, and a simple yet effective batch-overlapped temporal denoising module is proposed to bypass the constraints on video length during inference. Finally, a novel identity-specific face enhancement module is introduced to improve the visual quality of facial regions in the output videos. Comparative experiments demonstrate the effectiveness and superiority of the system in terms of visual quality, temporal coherence, and identity preservation, outperforming SOTA diffusion/non-diffusion methods. Project page: \url{https://github.com/ICTMCG/Make-Your-Anchor}.
Dance Your Latents: Consistent Dance Generation through Spatial-temporal Subspace Attention Guided by Motion Flow
Oct 20, 2023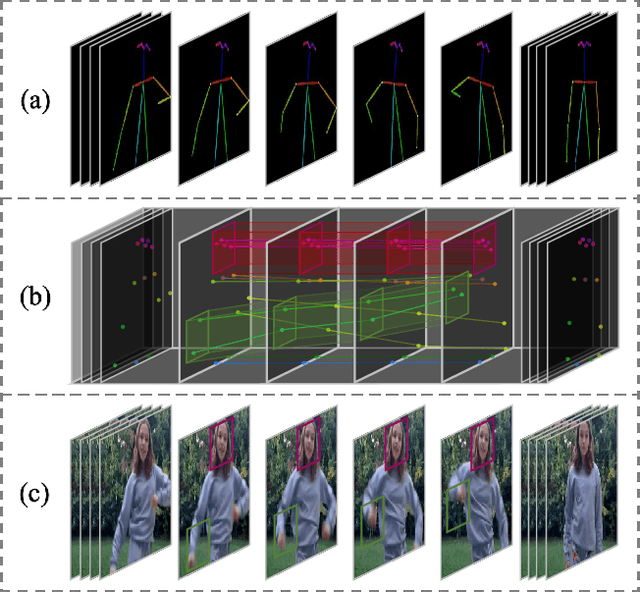
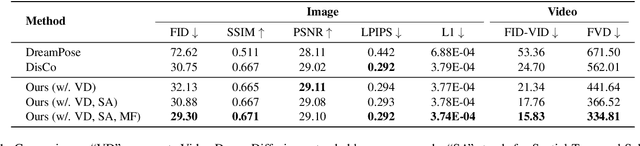
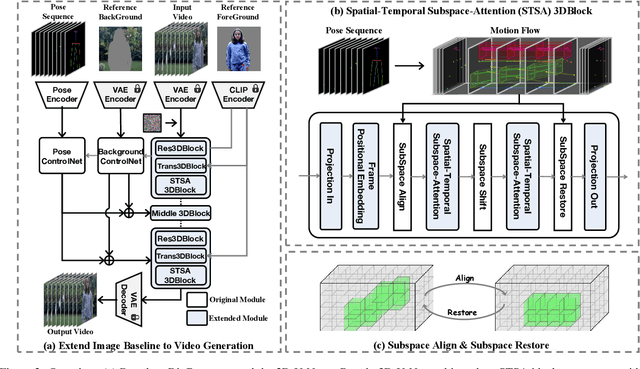
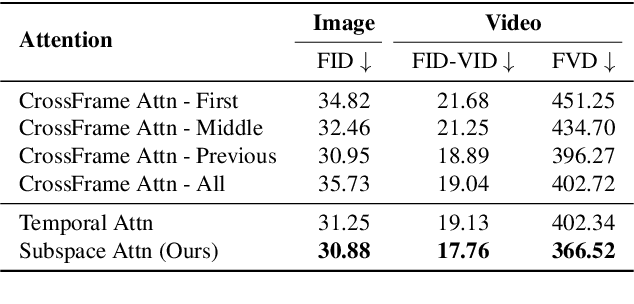
The advancement of generative AI has extended to the realm of Human Dance Generation, demonstrating superior generative capacities. However, current methods still exhibit deficiencies in achieving spatiotemporal consistency, resulting in artifacts like ghosting, flickering, and incoherent motions. In this paper, we present Dance-Your-Latents, a framework that makes latents dance coherently following motion flow to generate consistent dance videos. Firstly, considering that each constituent element moves within a confined space, we introduce spatial-temporal subspace-attention blocks that decompose the global space into a combination of regular subspaces and efficiently model the spatiotemporal consistency within these subspaces. This module enables each patch pay attention to adjacent areas, mitigating the excessive dispersion of long-range attention. Furthermore, observing that body part's movement is guided by pose control, we design motion flow guided subspace align & restore. This method enables the attention to be computed on the irregular subspace along the motion flow. Experimental results in TikTok dataset demonstrate that our approach significantly enhances spatiotemporal consistency of the generated videos.
Deepfake Network Architecture Attribution
Mar 14, 2022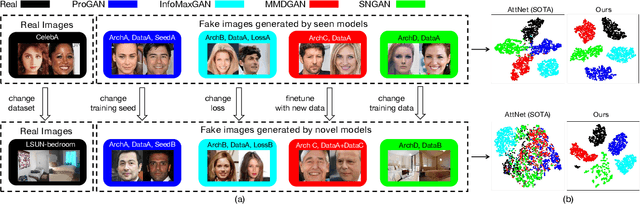
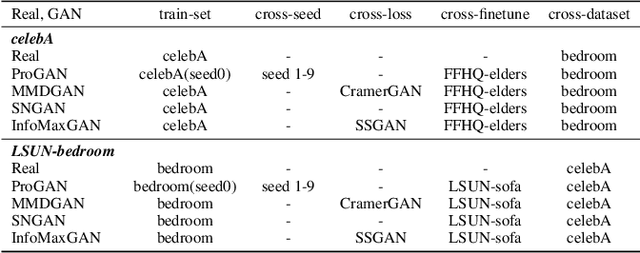

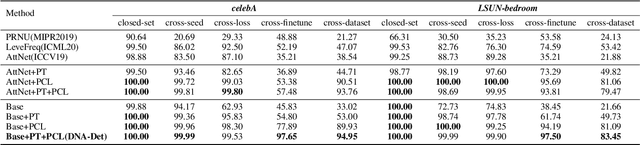
With the rapid progress of generation technology, it has become necessary to attribute the origin of fake images. Existing works on fake image attribution perform multi-class classification on several Generative Adversarial Network (GAN) models and obtain high accuracies. While encouraging, these works are restricted to model-level attribution, only capable of handling images generated by seen models with a specific seed, loss and dataset, which is limited in real-world scenarios when fake images may be generated by privately trained models. This motivates us to ask whether it is possible to attribute fake images to the source models' architectures even if they are finetuned or retrained under different configurations. In this work, we present the first study on Deepfake Network Architecture Attribution to attribute fake images on architecture-level. Based on an observation that GAN architecture is likely to leave globally consistent fingerprints while traces left by model weights vary in different regions, we provide a simple yet effective solution named DNA-Det for this problem. Extensive experiments on multiple cross-test setups and a large-scale dataset demonstrate the effectiveness of DNA-Det.
Progressive Domain Expansion Network for Single Domain Generalization
Mar 30, 2021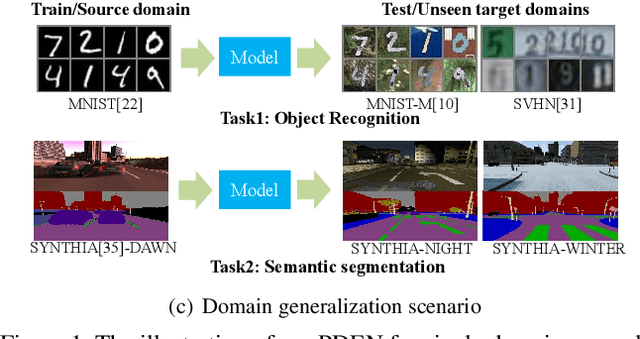
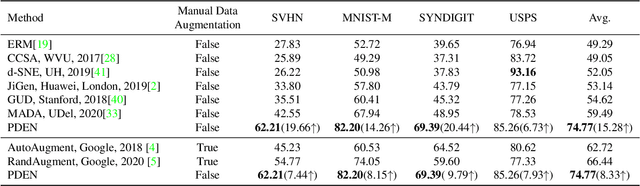
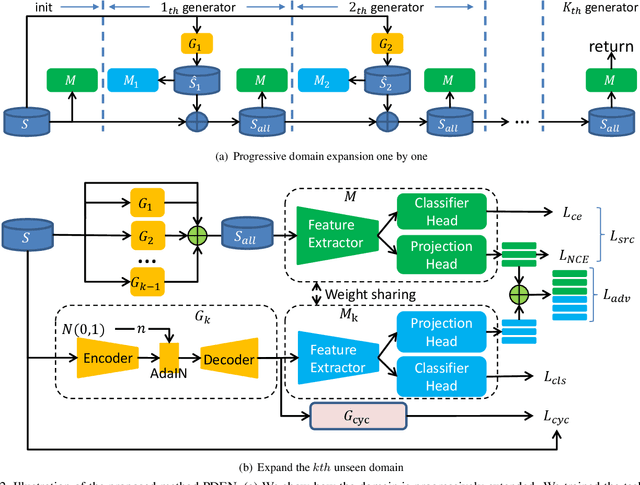
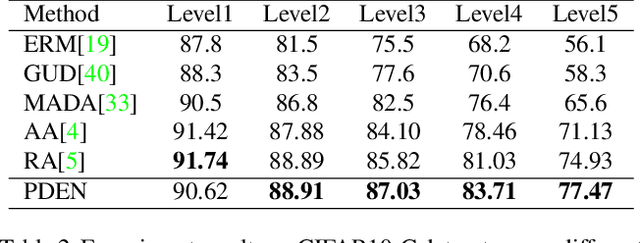
Single domain generalization is a challenging case of model generalization, where the models are trained on a single domain and tested on other unseen domains. A promising solution is to learn cross-domain invariant representations by expanding the coverage of the training domain. These methods have limited generalization performance gains in practical applications due to the lack of appropriate safety and effectiveness constraints. In this paper, we propose a novel learning framework called progressive domain expansion network (PDEN) for single domain generalization. The domain expansion subnetwork and representation learning subnetwork in PDEN mutually benefit from each other by joint learning. For the domain expansion subnetwork, multiple domains are progressively generated in order to simulate various photometric and geometric transforms in unseen domains. A series of strategies are introduced to guarantee the safety and effectiveness of the expanded domains. For the domain invariant representation learning subnetwork, contrastive learning is introduced to learn the domain invariant representation in which each class is well clustered so that a better decision boundary can be learned to improve it's generalization. Extensive experiments on classification and segmentation have shown that PDEN can achieve up to 15.28% improvement compared with the state-of-the-art single-domain generalization methods.