 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGAM-RAG: Gain-Adaptive Memory for Evolving Retrieval in Retrieval-Augmented Generation
Mar 02, 2026Retrieval-Augmented Generation (RAG) grounds large language models with external evidence, but many implementations rely on pre-built indices that remain static after construction. Related queries therefore repeat similar multi-hop traversal, increasing latency and compute. Motivated by schema-based learning in cognitive neuroscience, we propose GAM-RAG, a training-free framework that accumulates retrieval experience from recurring or related queries and updates retrieval memory over time. GAM-RAG builds a lightweight, relation-free hierarchical index whose links capture potential co-occurrence rather than fixed semantic relations. During inference, successful retrieval episodes provide sentence-level feedback, updating sentence memories so evidence useful for similar reasoning types becomes easier to activate later. To balance stability and adaptability under noisy feedback, we introduce an uncertainty-aware, Kalman-inspired gain rule that jointly updates memory states and perplexity-based uncertainty estimates. It applies fast updates for reliable novel signals and conservative refinement for stable or noisy memories. We provide a theoretical analysis of the update dynamics, and empirically show that GAM-RAG improves average performance by 3.95% over the strongest baseline and by 8.19% with 5-turn memory, while reducing inference cost by 61%. Our code and datasets are available at: https://anonymous.4open.science/r/GAM_RAG-2EF6.
UniHand: A Unified Model for Diverse Controlled 4D Hand Motion Modeling
Feb 25, 2026Hand motion plays a central role in human interaction, yet modeling realistic 4D hand motion (i.e., 3D hand pose sequences over time) remains challenging. Research in this area is typically divided into two tasks: (1) Estimation approaches reconstruct precise motion from visual observations, but often fail under hand occlusion or absence; (2) Generation approaches focus on synthesizing hand poses by exploiting generative priors under multi-modal structured inputs and infilling motion from incomplete sequences. However, this separation not only limits the effective use of heterogeneous condition signals that frequently arise in practice, but also prevents knowledge transfer between the two tasks. We present UniHand, a unified diffusion-based framework that formulates both estimation and generation as conditional motion synthesis. UniHand integrates heterogeneous inputs by embedding structured signals into a shared latent space through a joint variational autoencoder, which aligns conditions such as MANO parameters and 2D skeletons. Visual observations are encoded with a frozen vision backbone, while a dedicated hand perceptron extracts hand-specific cues directly from image features, removing the need for complex detection and cropping pipelines. A latent diffusion model then synthesizes consistent motion sequences from these diverse conditions. Extensive experiments across multiple benchmarks demonstrate that UniHand delivers robust and accurate hand motion modeling, maintaining performance under severe occlusions and temporally incomplete inputs.
ForgerySleuth: Empowering Multimodal Large Language Models for Image Manipulation Detection
Nov 29, 2024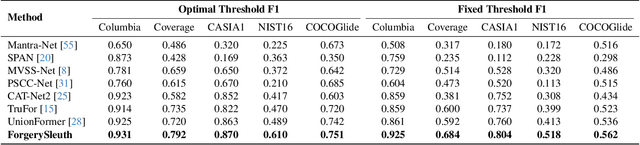
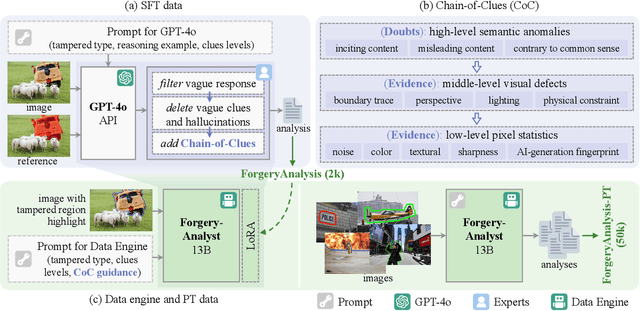
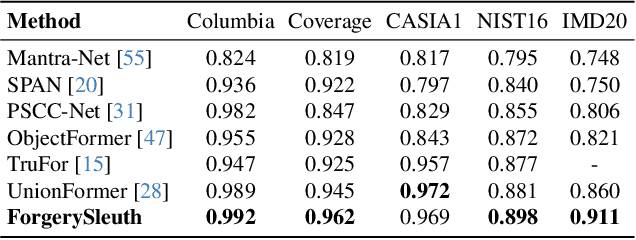
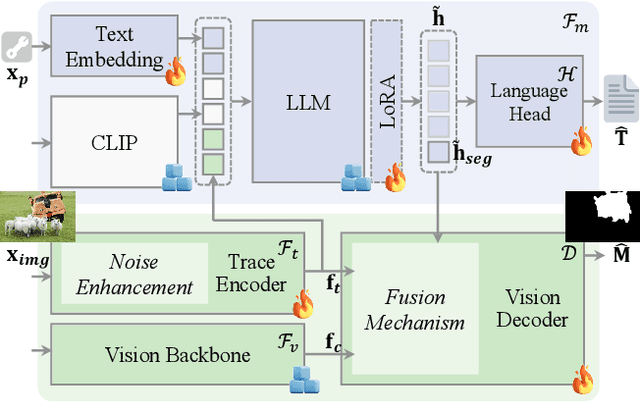
Multimodal large language models have unlocked new possibilities for various multimodal tasks. However, their potential in image manipulation detection remains unexplored. When directly applied to the IMD task, M-LLMs often produce reasoning texts that suffer from hallucinations and overthinking. To address this, in this work, we propose ForgerySleuth, which leverages M-LLMs to perform comprehensive clue fusion and generate segmentation outputs indicating specific regions that are tampered with. Moreover, we construct the ForgeryAnalysis dataset through the Chain-of-Clues prompt, which includes analysis and reasoning text to upgrade the image manipulation detection task. A data engine is also introduced to build a larger-scale dataset for the pre-training phase. Our extensive experiments demonstrate the effectiveness of ForgeryAnalysis and show that ForgerySleuth significantly outperforms existing methods in generalization, robustness, and explainability.
EnviroExam: Benchmarking Environmental Science Knowledge of Large Language Models
May 18, 2024In the field of environmental science, it is crucial to have robust evaluation metrics for large language models to ensure their efficacy and accuracy. We propose EnviroExam, a comprehensive evaluation method designed to assess the knowledge of large language models in the field of environmental science. EnviroExam is based on the curricula of top international universities, covering undergraduate, master's, and doctoral courses, and includes 936 questions across 42 core courses. By conducting 0-shot and 5-shot tests on 31 open-source large language models, EnviroExam reveals the performance differences among these models in the domain of environmental science and provides detailed evaluation standards. The results show that 61.3% of the models passed the 5-shot tests, while 48.39% passed the 0-shot tests. By introducing the coefficient of variation as an indicator, we evaluate the performance of mainstream open-source large language models in environmental science from multiple perspectives, providing effective criteria for selecting and fine-tuning language models in this field. Future research will involve constructing more domain-specific test sets using specialized environmental science textbooks to further enhance the accuracy and specificity of the evaluation.
Rethinking Image Editing Detection in the Era of Generative AI Revolution
Nov 29, 2023
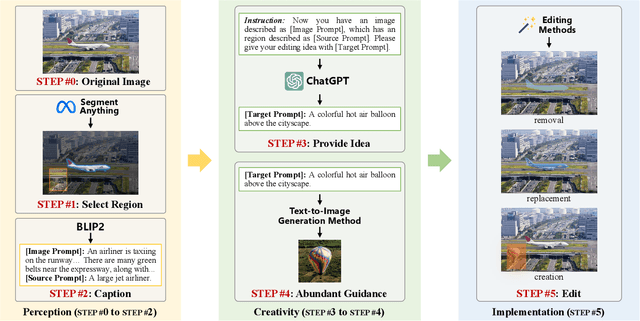


The accelerated advancement of generative AI significantly enhance the viability and effectiveness of generative regional editing methods. This evolution render the image manipulation more accessible, thereby intensifying the risk of altering the conveyed information within original images and even propagating misinformation. Consequently, there exists a critical demand for robust capable of detecting the edited images. However, the lack of comprehensive dataset containing images edited with abundant and advanced generative regional editing methods poses a substantial obstacle to the advancement of corresponding detection methods. We endeavor to fill the vacancy by constructing the GRE dataset, a large-scale generative regional editing dataset with the following advantages: 1) Collection of real-world original images, focusing on two frequently edited scenarios. 2) Integration of a logical and simulated editing pipeline, leveraging multiple large models in various modalities. 3) Inclusion of various editing approaches with distinct architectures. 4) Provision of comprehensive analysis tasks. We perform comprehensive experiments with proposed three tasks: edited image classification, edited method attribution and edited region localization, providing analysis of distinct editing methods and evaluation of detection methods in related fields. We expect that the GRE dataset can promote further research and exploration in the field of generative region editing detection.
Dance Your Latents: Consistent Dance Generation through Spatial-temporal Subspace Attention Guided by Motion Flow
Oct 20, 2023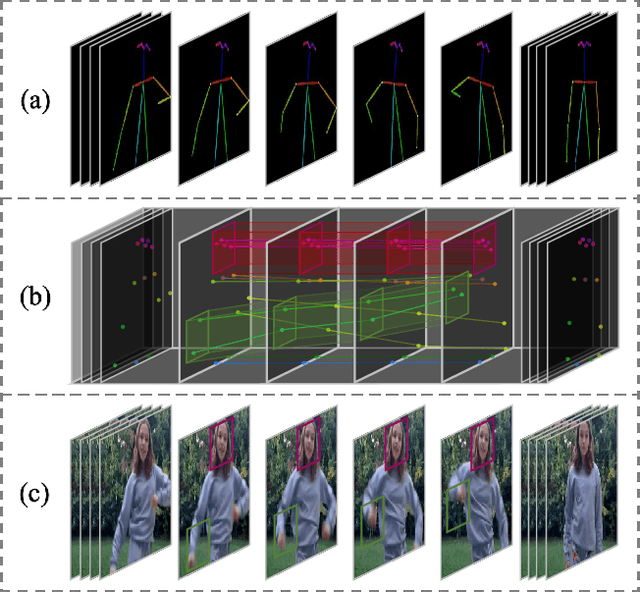
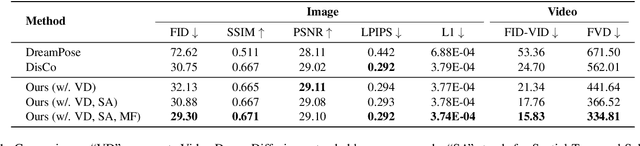
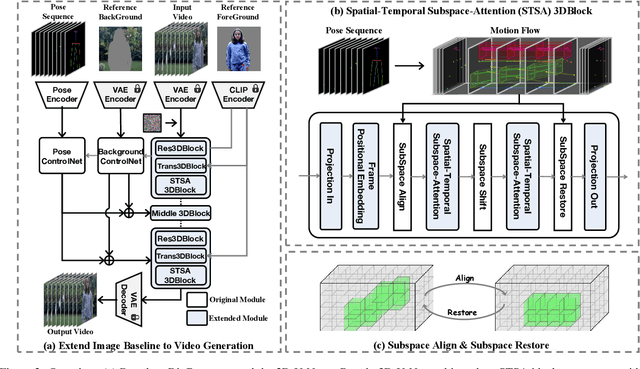
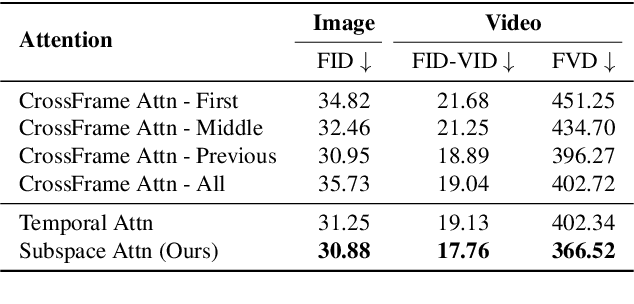
The advancement of generative AI has extended to the realm of Human Dance Generation, demonstrating superior generative capacities. However, current methods still exhibit deficiencies in achieving spatiotemporal consistency, resulting in artifacts like ghosting, flickering, and incoherent motions. In this paper, we present Dance-Your-Latents, a framework that makes latents dance coherently following motion flow to generate consistent dance videos. Firstly, considering that each constituent element moves within a confined space, we introduce spatial-temporal subspace-attention blocks that decompose the global space into a combination of regular subspaces and efficiently model the spatiotemporal consistency within these subspaces. This module enables each patch pay attention to adjacent areas, mitigating the excessive dispersion of long-range attention. Furthermore, observing that body part's movement is guided by pose control, we design motion flow guided subspace align & restore. This method enables the attention to be computed on the irregular subspace along the motion flow. Experimental results in TikTok dataset demonstrate that our approach significantly enhances spatiotemporal consistency of the generated videos.
DSPDet3D: Dynamic Spatial Pruning for 3D Small Object Detection
May 05, 2023In this paper, we propose a new detection framework for 3D small object detection. Although deep learning-based 3D object detection methods have achieved great success in recent years, current methods still struggle on small objects due to weak geometric information. With in-depth study, we find increasing the spatial resolution of the feature maps significantly boosts the performance of 3D small object detection. And more interestingly, though the computational overhead increases dramatically with resolution, the growth mainly comes from the upsampling operation of the decoder. Inspired by this, we present a high-resolution multi-level detector with dynamic spatial pruning named DSPDet3D, which detects objects from large to small by iterative upsampling and meanwhile prunes the spatial representation of the scene at regions where there is no smaller object to be detected in higher resolution. As the 3D detector only needs to predict sparse bounding boxes, pruning a large amount of uninformative features does not degrade the detection performance but significantly reduces the computational cost of upsampling. In this way, our DSPDet3D achieves high accuracy on small object detection while requiring even less memory footprint and inference time. On ScanNet and TO-SCENE dataset, our method improves the detection performance of small objects to a new level while achieving leading inference speed among all mainstream indoor 3D object detection methods.