 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvancing Vision Transformer with Enhanced Spatial Priors
Apr 20, 2026In recent years, the Vision Transformer (ViT) has garnered significant attention within the computer vision community. However, the core component of ViT, Self-Attention, lacks explicit spatial priors and suffers from quadratic computational complexity, limiting its applicability. To address these issues, we have proposed RMT, a robust vision backbone with explicit spatial priors for general purposes. RMT utilizes Manhattan distance decay to introduce spatial information and employs a horizontal and vertical decomposition attention method to model global information. Building on the strengths of RMT, Euclidean enhanced Vision Transformer (EVT) is an expanded version that incorporates several key improvements. Firstly, EVT uses a more reasonable Euclidean distance decay to enhance the modeling of spatial information, allowing for a more accurate representation of spatial relationships compared to the Manhattan distance used in RMT. Secondly, EVT abandons the decomposed attention mechanism featured in RMT and instead adopts a simpler spatially-independent grouping approach, providing the model with greater flexibility in controlling the number of tokens within each group. By addressing these modifications, EVT offers a more sophisticated and adaptable approach to incorporating spatial priors into the Self-Attention mechanism, thus overcoming some of the limitations associated with RMT and further enhancing its applicability in various computer vision tasks. Extensive experiments on Image Classification, Object Detection, Instance Segmentation, and Semantic Segmentation demonstrate that EVT exhibits exceptional performance. Without additional training data, EVT achieves 86.6% top1-acc on ImageNet-1k.
Vision Generalist Model: A Survey
Jun 11, 2025Recently, we have witnessed the great success of the generalist model in natural language processing. The generalist model is a general framework trained with massive data and is able to process various downstream tasks simultaneously. Encouraged by their impressive performance, an increasing number of researchers are venturing into the realm of applying these models to computer vision tasks. However, the inputs and outputs of vision tasks are more diverse, and it is difficult to summarize them as a unified representation. In this paper, we provide a comprehensive overview of the vision generalist models, delving into their characteristics and capabilities within the field. First, we review the background, including the datasets, tasks, and benchmarks. Then, we dig into the design of frameworks that have been proposed in existing research, while also introducing the techniques employed to enhance their performance. To better help the researchers comprehend the area, we take a brief excursion into related domains, shedding light on their interconnections and potential synergies. To conclude, we provide some real-world application scenarios, undertake a thorough examination of the persistent challenges, and offer insights into possible directions for future research endeavors.
Prototypical Distillation and Debiased Tuning for Black-box Unsupervised Domain Adaptation
Dec 30, 2024



Unsupervised domain adaptation aims to transfer knowledge from a related, label-rich source domain to an unlabeled target domain, thereby circumventing the high costs associated with manual annotation. Recently, there has been growing interest in source-free domain adaptation, a paradigm in which only a pre-trained model, rather than the labeled source data, is provided to the target domain. Given the potential risk of source data leakage via model inversion attacks, this paper introduces a novel setting called black-box domain adaptation, where the source model is accessible only through an API that provides the predicted label along with the corresponding confidence value for each query. We develop a two-step framework named $\textbf{Pro}$totypical $\textbf{D}$istillation and $\textbf{D}$ebiased tun$\textbf{ing}$ ($\textbf{ProDDing}$). In the first step, ProDDing leverages both the raw predictions from the source model and prototypes derived from the target domain as teachers to distill a customized target model. In the second step, ProDDing keeps fine-tuning the distilled model by penalizing logits that are biased toward certain classes. Empirical results across multiple benchmarks demonstrate that ProDDing outperforms existing black-box domain adaptation methods. Moreover, in the case of hard-label black-box domain adaptation, where only predicted labels are available, ProDDing achieves significant improvements over these methods. Code will be available at \url{https://github.com/tim-learn/ProDDing/}.
ProIn: Learning to Predict Trajectory Based on Progressive Interactions for Autonomous Driving
Mar 25, 2024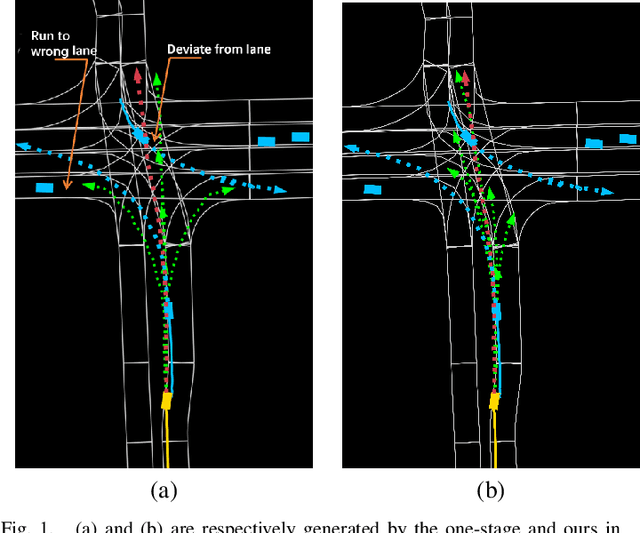
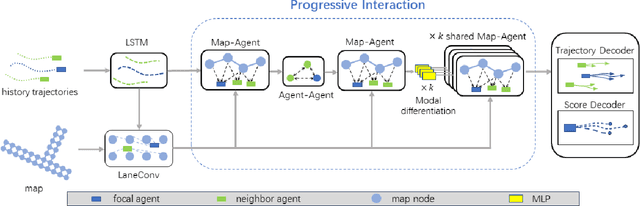
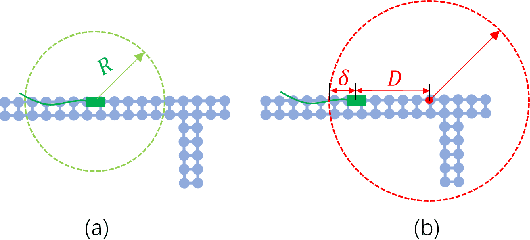
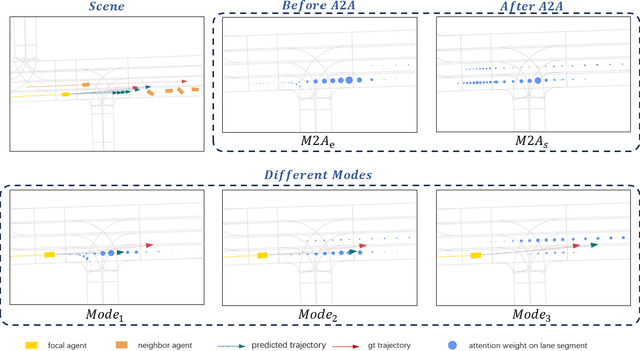
Accurate motion prediction of pedestrians, cyclists, and other surrounding vehicles (all called agents) is very important for autonomous driving. Most existing works capture map information through an one-stage interaction with map by vector-based attention, to provide map constraints for social interaction and multi-modal differentiation. However, these methods have to encode all required map rules into the focal agent's feature, so as to retain all possible intentions' paths while at the meantime to adapt to potential social interaction. In this work, a progressive interaction network is proposed to enable the agent's feature to progressively focus on relevant maps, in order to better learn agents' feature representation capturing the relevant map constraints. The network progressively encode the complex influence of map constraints into the agent's feature through graph convolutions at the following three stages: after historical trajectory encoder, after social interaction, and after multi-modal differentiation. In addition, a weight allocation mechanism is proposed for multi-modal training, so that each mode can obtain learning opportunities from a single-mode ground truth. Experiments have validated the superiority of progressive interactions to the existing one-stage interaction, and demonstrate the effectiveness of each component. Encouraging results were obtained in the challenging benchmarks.
RMT: Retentive Networks Meet Vision Transformers
Sep 20, 2023Transformer first appears in the field of natural language processing and is later migrated to the computer vision domain, where it demonstrates excellent performance in vision tasks. However, recently, Retentive Network (RetNet) has emerged as an architecture with the potential to replace Transformer, attracting widespread attention in the NLP community. Therefore, we raise the question of whether transferring RetNet's idea to vision can also bring outstanding performance to vision tasks. To address this, we combine RetNet and Transformer to propose RMT. Inspired by RetNet, RMT introduces explicit decay into the vision backbone, bringing prior knowledge related to spatial distances to the vision model. This distance-related spatial prior allows for explicit control of the range of tokens that each token can attend to. Additionally, to reduce the computational cost of global modeling, we decompose this modeling process along the two coordinate axes of the image. Abundant experiments have demonstrated that our RMT exhibits exceptional performance across various computer vision tasks. For example, RMT achieves 84.1% Top1-acc on ImageNet-1k using merely 4.5G FLOPs. To the best of our knowledge, among all models, RMT achieves the highest Top1-acc when models are of similar size and trained with the same strategy. Moreover, RMT significantly outperforms existing vision backbones in downstream tasks such as object detection, instance segmentation, and semantic segmentation. Our work is still in progress.
DSPDet3D: Dynamic Spatial Pruning for 3D Small Object Detection
May 05, 2023In this paper, we propose a new detection framework for 3D small object detection. Although deep learning-based 3D object detection methods have achieved great success in recent years, current methods still struggle on small objects due to weak geometric information. With in-depth study, we find increasing the spatial resolution of the feature maps significantly boosts the performance of 3D small object detection. And more interestingly, though the computational overhead increases dramatically with resolution, the growth mainly comes from the upsampling operation of the decoder. Inspired by this, we present a high-resolution multi-level detector with dynamic spatial pruning named DSPDet3D, which detects objects from large to small by iterative upsampling and meanwhile prunes the spatial representation of the scene at regions where there is no smaller object to be detected in higher resolution. As the 3D detector only needs to predict sparse bounding boxes, pruning a large amount of uninformative features does not degrade the detection performance but significantly reduces the computational cost of upsampling. In this way, our DSPDet3D achieves high accuracy on small object detection while requiring even less memory footprint and inference time. On ScanNet and TO-SCENE dataset, our method improves the detection performance of small objects to a new level while achieving leading inference speed among all mainstream indoor 3D object detection methods.
Progressive Multi-Stage Learning for Discriminative Tracking
Apr 01, 2020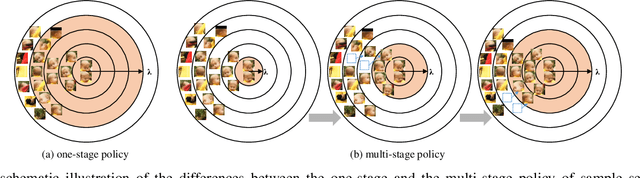

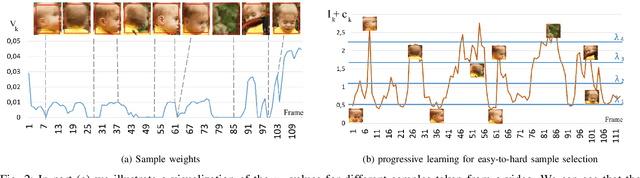
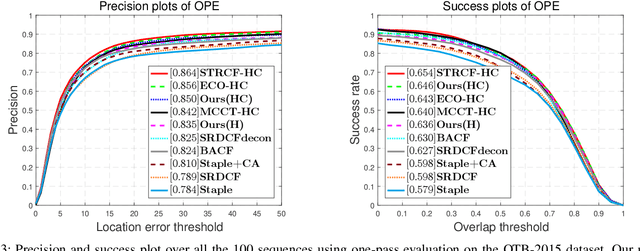
Visual tracking is typically solved as a discriminative learning problem that usually requires high-quality samples for online model adaptation. It is a critical and challenging problem to evaluate the training samples collected from previous predictions and employ sample selection by their quality to train the model. To tackle the above problem, we propose a joint discriminative learning scheme with the progressive multi-stage optimization policy of sample selection for robust visual tracking. The proposed scheme presents a novel time-weighted and detection-guided self-paced learning strategy for easy-to-hard sample selection, which is capable of tolerating relatively large intra-class variations while maintaining inter-class separability. Such a self-paced learning strategy is jointly optimized in conjunction with the discriminative tracking process, resulting in robust tracking results. Experiments on the benchmark datasets demonstrate the effectiveness of the proposed learning framework.