 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Pairs to Sequences: Track-Aware Policy Gradients for Keypoint Detection
Feb 25, 2026Keypoint-based matching is a fundamental component of modern 3D vision systems, such as Structure-from-Motion (SfM) and SLAM. Most existing learning-based methods are trained on image pairs, a paradigm that fails to explicitly optimize for the long-term trackability of keypoints across sequences under challenging viewpoint and illumination changes. In this paper, we reframe keypoint detection as a sequential decision-making problem. We introduce TraqPoint, a novel, end-to-end Reinforcement Learning (RL) framework designed to optimize the \textbf{Tra}ck-\textbf{q}uality (Traq) of keypoints directly on image sequences. Our core innovation is a track-aware reward mechanism that jointly encourages the consistency and distinctiveness of keypoints across multiple views, guided by a policy gradient method. Extensive evaluations on sparse matching benchmarks, including relative pose estimation and 3D reconstruction, demonstrate that TraqPoint significantly outperforms some state-of-the-art (SOTA) keypoint detection and description methods.
ProIn: Learning to Predict Trajectory Based on Progressive Interactions for Autonomous Driving
Mar 25, 2024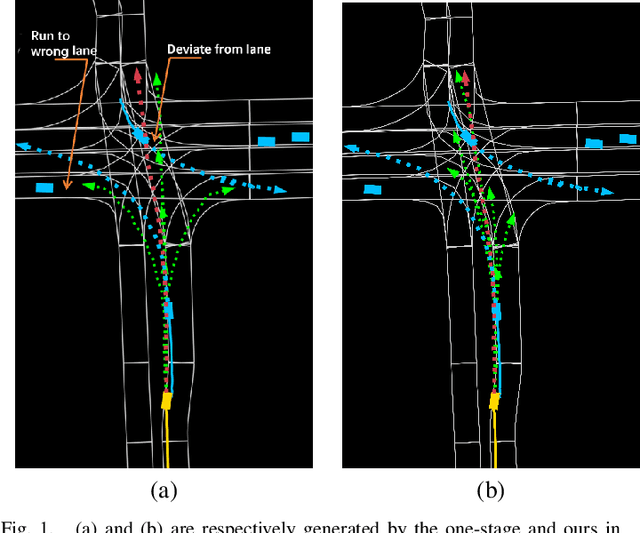
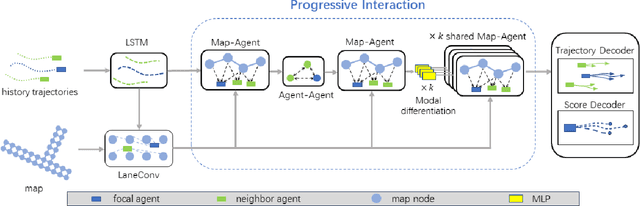
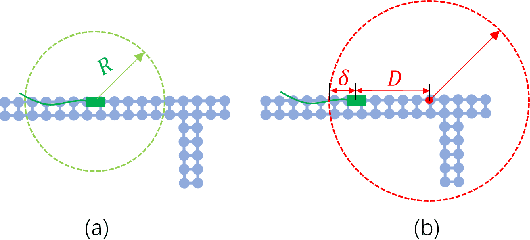
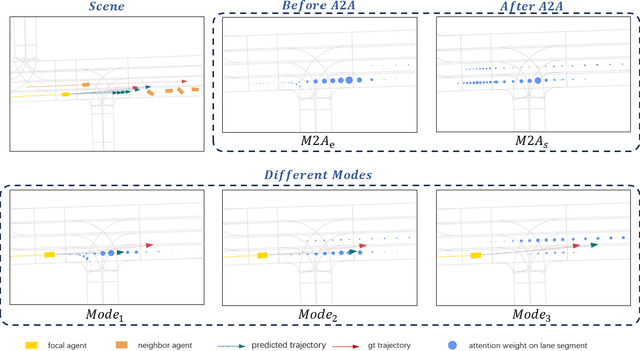
Accurate motion prediction of pedestrians, cyclists, and other surrounding vehicles (all called agents) is very important for autonomous driving. Most existing works capture map information through an one-stage interaction with map by vector-based attention, to provide map constraints for social interaction and multi-modal differentiation. However, these methods have to encode all required map rules into the focal agent's feature, so as to retain all possible intentions' paths while at the meantime to adapt to potential social interaction. In this work, a progressive interaction network is proposed to enable the agent's feature to progressively focus on relevant maps, in order to better learn agents' feature representation capturing the relevant map constraints. The network progressively encode the complex influence of map constraints into the agent's feature through graph convolutions at the following three stages: after historical trajectory encoder, after social interaction, and after multi-modal differentiation. In addition, a weight allocation mechanism is proposed for multi-modal training, so that each mode can obtain learning opportunities from a single-mode ground truth. Experiments have validated the superiority of progressive interactions to the existing one-stage interaction, and demonstrate the effectiveness of each component. Encouraging results were obtained in the challenging benchmarks.
FusionAD: Multi-modality Fusion for Prediction and Planning Tasks of Autonomous Driving
Aug 14, 2023



Building a multi-modality multi-task neural network toward accurate and robust performance is a de-facto standard in perception task of autonomous driving. However, leveraging such data from multiple sensors to jointly optimize the prediction and planning tasks remains largely unexplored. In this paper, we present FusionAD, to the best of our knowledge, the first unified framework that fuse the information from two most critical sensors, camera and LiDAR, goes beyond perception task. Concretely, we first build a transformer based multi-modality fusion network to effectively produce fusion based features. In constrast to camera-based end-to-end method UniAD, we then establish a fusion aided modality-aware prediction and status-aware planning modules, dubbed FMSPnP that take advantages of multi-modality features. We conduct extensive experiments on commonly used benchmark nuScenes dataset, our FusionAD achieves state-of-the-art performance and surpassing baselines on average 15% on perception tasks like detection and tracking, 10% on occupancy prediction accuracy, reducing prediction error from 0.708 to 0.389 in ADE score and reduces the collision rate from 0.31% to only 0.12%.