 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolySim: Bridging the Sim-to-Real Gap for Humanoid Control via Multi-Simulator Dynamics Randomization
Oct 02, 2025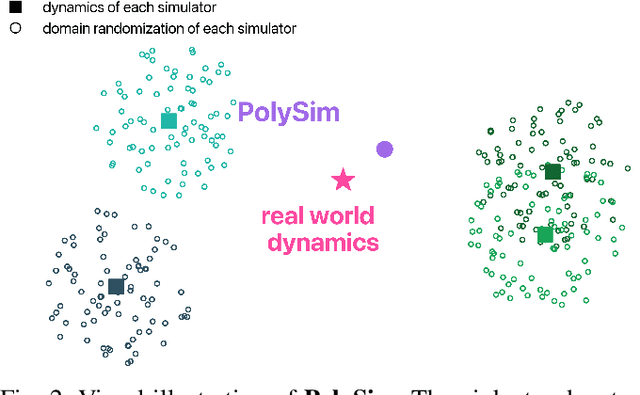
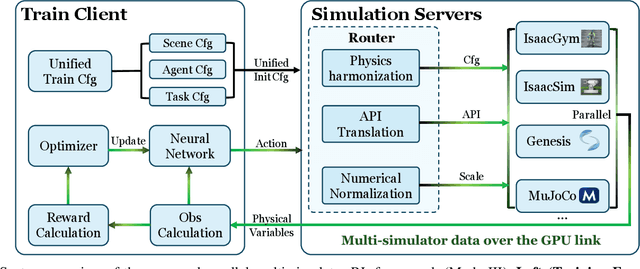
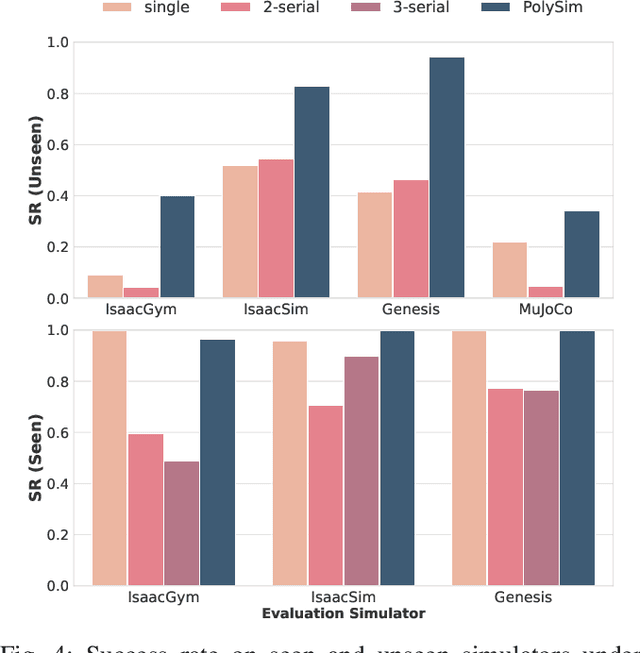

Humanoid whole-body control (WBC) policies trained in simulation often suffer from the sim-to-real gap, which fundamentally arises from simulator inductive bias, the inherent assumptions and limitations of any single simulator. These biases lead to nontrivial discrepancies both across simulators and between simulation and the real world. To mitigate the effect of simulator inductive bias, the key idea is to train policies jointly across multiple simulators, encouraging the learned controller to capture dynamics that generalize beyond any single simulator's assumptions. We thus introduce PolySim, a WBC training platform that integrates multiple heterogeneous simulators. PolySim can launch parallel environments from different engines simultaneously within a single training run, thereby realizing dynamics-level domain randomization. Theoretically, we show that PolySim yields a tighter upper bound on simulator inductive bias than single-simulator training. In experiments, PolySim substantially reduces motion-tracking error in sim-to-sim evaluations; for example, on MuJoCo, it improves execution success by 52.8 over an IsaacSim baseline. PolySim further enables zero-shot deployment on a real Unitree G1 without additional fine-tuning, showing effective transfer from simulation to the real world. We will release the PolySim code upon acceptance of this work.
EA-RAS: Towards Efficient and Accurate End-to-End Reconstruction of Anatomical Skeleton
Sep 03, 2024



Efficient, accurate and low-cost estimation of human skeletal information is crucial for a range of applications such as biology education and human-computer interaction. However, current simple skeleton models, which are typically based on 2D-3D joint points, fall short in terms of anatomical fidelity, restricting their utility in fields. On the other hand, more complex models while anatomically precise, are hindered by sophisticate multi-stage processing and the need for extra data like skin meshes, making them unsuitable for real-time applications. To this end, we propose the EA-RAS (Towards Efficient and Accurate End-to-End Reconstruction of Anatomical Skeleton), a single-stage, lightweight, and plug-and-play anatomical skeleton estimator that can provide real-time, accurate anatomically realistic skeletons with arbitrary pose using only a single RGB image input. Additionally, EA-RAS estimates the conventional human-mesh model explicitly, which not only enhances the functionality but also leverages the outside skin information by integrating features into the inside skeleton modeling process. In this work, we also develop a progressive training strategy and integrated it with an enhanced optimization process, enabling the network to obtain initial weights using only a small skin dataset and achieve self-supervision in skeleton reconstruction. Besides, we also provide an optional lightweight post-processing optimization strategy to further improve accuracy for scenarios that prioritize precision over real-time processing. The experiments demonstrated that our regression method is over 800 times faster than existing methods, meeting real-time requirements. Additionally, the post-processing optimization strategy provided can enhance reconstruction accuracy by over 50% and achieve a speed increase of more than 7 times.
Cross-Modal Spherical Aggregation for Weakly Supervised Remote Sensing Shadow Removal
Jun 25, 2024



Remote sensing shadow removal, which aims to recover contaminated surface information, is tricky since shadows typically display overwhelmingly low illumination intensities. In contrast, the infrared image is robust toward significant light changes, providing visual clues complementary to the visible image. Nevertheless, the existing methods ignore the collaboration between heterogeneous modalities, leading to undesired quality degradation. To fill this gap, we propose a weakly supervised shadow removal network with a spherical feature space, dubbed S2-ShadowNet, to explore the best of both worlds for visible and infrared modalities. Specifically, we employ a modal translation (visible-to-infrared) model to learn the cross-domain mapping, thus generating realistic infrared samples. Then, Swin Transformer is utilized to extract strong representational visible/infrared features. Simultaneously, the extracted features are mapped to the smooth spherical manifold, which alleviates the domain shift through regularization. Well-designed similarity loss and orthogonality loss are embedded into the spherical space, prompting the separation of private visible/infrared features and the alignment of shared visible/infrared features through constraints on both representation content and orientation. Such a manner encourages implicit reciprocity between modalities, thus providing a novel insight into shadow removal. Notably, ground truth is not available in practice, thus S2-ShadowNet is trained by cropping shadow and shadow-free patches from the shadow image itself, avoiding stereotypical and strict pair data acquisition. More importantly, we contribute a large-scale weakly supervised shadow removal benchmark, including 4000 shadow images with corresponding shadow masks.
4DHands: Reconstructing Interactive Hands in 4D with Transformers
May 31, 2024In this paper, we introduce 4DHands, a robust approach to recovering interactive hand meshes and their relative movement from monocular inputs. Our approach addresses two major limitations of previous methods: lacking a unified solution for handling various hand image inputs and neglecting the positional relationship of two hands within images. To overcome these challenges, we develop a transformer-based architecture with novel tokenization and feature fusion strategies. Specifically, we propose a Relation-aware Two-Hand Tokenization (RAT) method to embed positional relation information into the hand tokens. In this way, our network can handle both single-hand and two-hand inputs and explicitly leverage relative hand positions, facilitating the reconstruction of intricate hand interactions in real-world scenarios. As such tokenization indicates the relative relationship of two hands, it also supports more effective feature fusion. To this end, we further develop a Spatio-temporal Interaction Reasoning (SIR) module to fuse hand tokens in 4D with attention and decode them into 3D hand meshes and relative temporal movements. The efficacy of our approach is validated on several benchmark datasets. The results on in-the-wild videos and real-world scenarios demonstrate the superior performances of our approach for interactive hand reconstruction. More video results can be found on the project page: https://4dhands.github.io.
LASIL: Learner-Aware Supervised Imitation Learning For Long-term Microscopic Traffic Simulation
Apr 08, 2024



Microscopic traffic simulation plays a crucial role in transportation engineering by providing insights into individual vehicle behavior and overall traffic flow. However, creating a realistic simulator that accurately replicates human driving behaviors in various traffic conditions presents significant challenges. Traditional simulators relying on heuristic models often fail to deliver accurate simulations due to the complexity of real-world traffic environments. Due to the covariate shift issue, existing imitation learning-based simulators often fail to generate stable long-term simulations. In this paper, we propose a novel approach called learner-aware supervised imitation learning to address the covariate shift problem in multi-agent imitation learning. By leveraging a variational autoencoder simultaneously modeling the expert and learner state distribution, our approach augments expert states such that the augmented state is aware of learner state distribution. Our method, applied to urban traffic simulation, demonstrates significant improvements over existing state-of-the-art baselines in both short-term microscopic and long-term macroscopic realism when evaluated on the real-world dataset pNEUMA.
ProIn: Learning to Predict Trajectory Based on Progressive Interactions for Autonomous Driving
Mar 25, 2024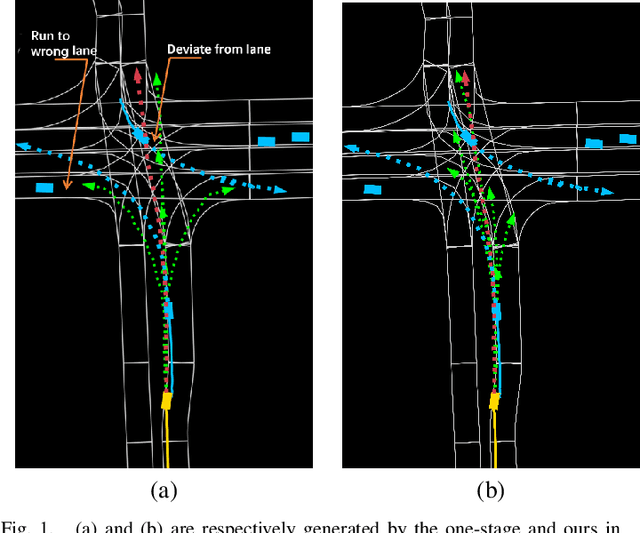
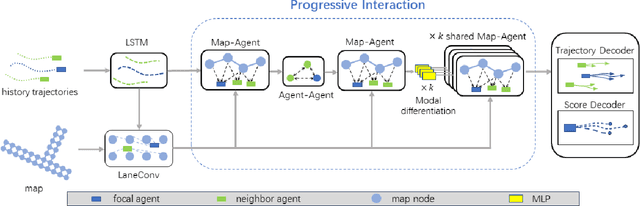
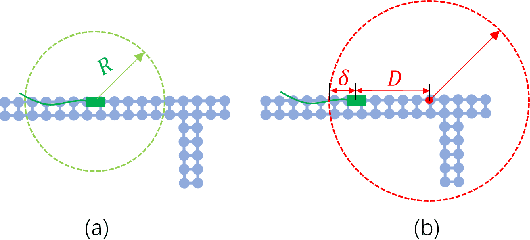
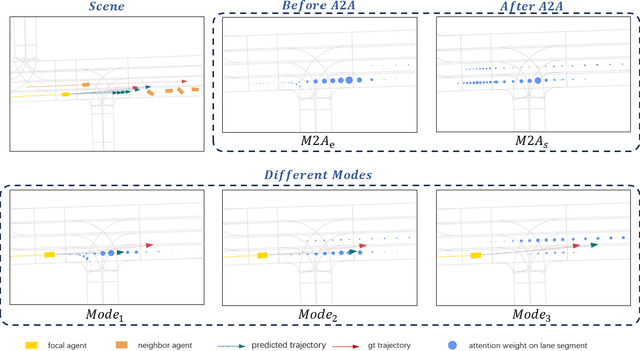
Accurate motion prediction of pedestrians, cyclists, and other surrounding vehicles (all called agents) is very important for autonomous driving. Most existing works capture map information through an one-stage interaction with map by vector-based attention, to provide map constraints for social interaction and multi-modal differentiation. However, these methods have to encode all required map rules into the focal agent's feature, so as to retain all possible intentions' paths while at the meantime to adapt to potential social interaction. In this work, a progressive interaction network is proposed to enable the agent's feature to progressively focus on relevant maps, in order to better learn agents' feature representation capturing the relevant map constraints. The network progressively encode the complex influence of map constraints into the agent's feature through graph convolutions at the following three stages: after historical trajectory encoder, after social interaction, and after multi-modal differentiation. In addition, a weight allocation mechanism is proposed for multi-modal training, so that each mode can obtain learning opportunities from a single-mode ground truth. Experiments have validated the superiority of progressive interactions to the existing one-stage interaction, and demonstrate the effectiveness of each component. Encouraging results were obtained in the challenging benchmarks.
FusionAD: Multi-modality Fusion for Prediction and Planning Tasks of Autonomous Driving
Aug 14, 2023



Building a multi-modality multi-task neural network toward accurate and robust performance is a de-facto standard in perception task of autonomous driving. However, leveraging such data from multiple sensors to jointly optimize the prediction and planning tasks remains largely unexplored. In this paper, we present FusionAD, to the best of our knowledge, the first unified framework that fuse the information from two most critical sensors, camera and LiDAR, goes beyond perception task. Concretely, we first build a transformer based multi-modality fusion network to effectively produce fusion based features. In constrast to camera-based end-to-end method UniAD, we then establish a fusion aided modality-aware prediction and status-aware planning modules, dubbed FMSPnP that take advantages of multi-modality features. We conduct extensive experiments on commonly used benchmark nuScenes dataset, our FusionAD achieves state-of-the-art performance and surpassing baselines on average 15% on perception tasks like detection and tracking, 10% on occupancy prediction accuracy, reducing prediction error from 0.708 to 0.389 in ADE score and reduces the collision rate from 0.31% to only 0.12%.
Long-term Microscopic Traffic Simulation with History-Masked Multi-agent Imitation Learning
Jun 10, 2023



A realistic long-term microscopic traffic simulator is necessary for understanding how microscopic changes affect traffic patterns at a larger scale. Traditional simulators that model human driving behavior with heuristic rules often fail to achieve accurate simulations due to real-world traffic complexity. To overcome this challenge, researchers have turned to neural networks, which are trained through imitation learning from human driver demonstrations. However, existing learning-based microscopic simulators often fail to generate stable long-term simulations due to the \textit{covariate shift} issue. To address this, we propose a history-masked multi-agent imitation learning method that removes all vehicles' historical trajectory information and applies perturbation to their current positions during learning. We apply our approach specifically to the urban traffic simulation problem and evaluate it on the real-world large-scale pNEUMA dataset, achieving better short-term microscopic and long-term macroscopic similarity to real-world data than state-of-the-art baselines.
CCIL: Context-conditioned imitation learning for urban driving
May 04, 2023
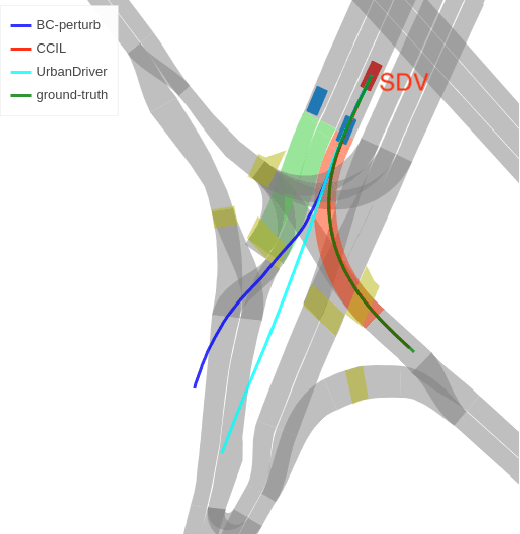
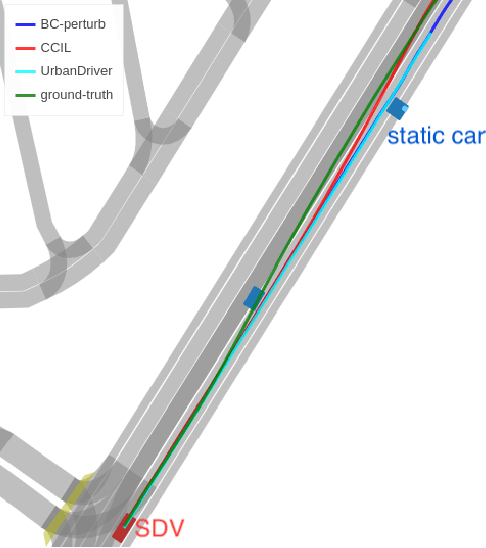
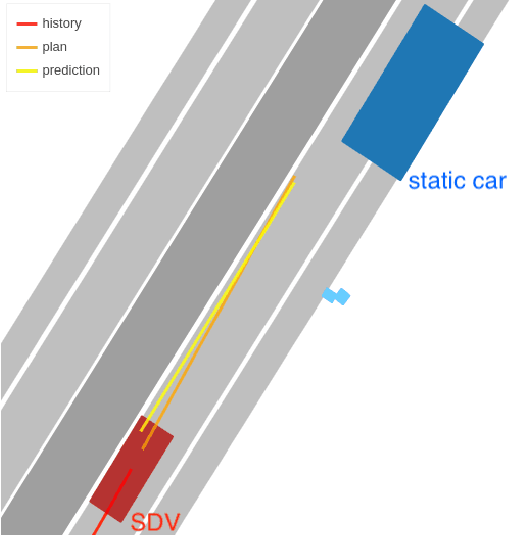
Imitation learning holds great promise for addressing the complex task of autonomous urban driving, as experienced human drivers can navigate highly challenging scenarios with ease. While behavior cloning is a widely used imitation learning approach in autonomous driving due to its exemption from risky online interactions, it suffers from the covariate shift issue. To address this limitation, we propose a context-conditioned imitation learning approach that employs a policy to map the context state into the ego vehicle's future trajectory, rather than relying on the traditional formulation of both ego and context states to predict the ego action. Additionally, to reduce the implicit ego information in the coordinate system, we design an ego-perturbed goal-oriented coordinate system. The origin of this coordinate system is the ego vehicle's position plus a zero mean Gaussian perturbation, and the x-axis direction points towards its goal position. Our experiments on the real-world large-scale Lyft and nuPlan datasets show that our method significantly outperforms state-of-the-art approaches.
Zero-shot Transfer Learning of Driving Policy via Socially Adversarial Traffic Flow
Apr 25, 2023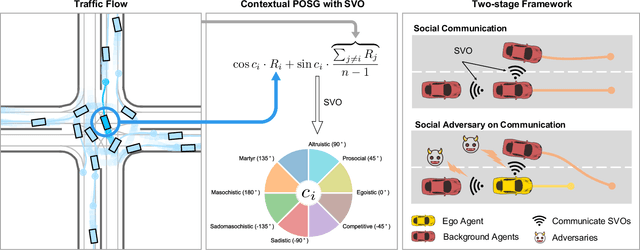
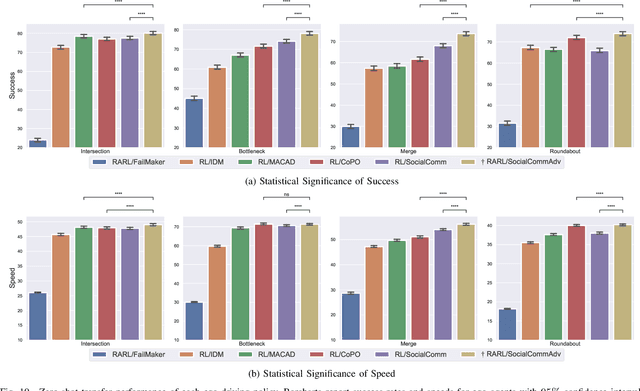
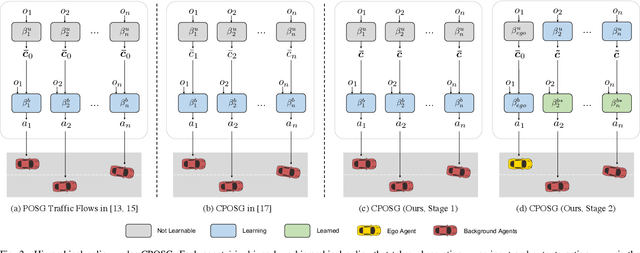
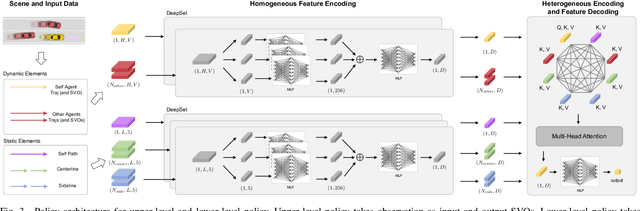
Acquiring driving policies that can transfer to unseen environments is challenging when driving in dense traffic flows. The design of traffic flow is essential and previous studies are unable to balance interaction and safety-criticism. To tackle this problem, we propose a socially adversarial traffic flow. We propose a Contextual Partially-Observable Stochastic Game to model traffic flow and assign Social Value Orientation (SVO) as context. We then adopt a two-stage framework. In Stage 1, each agent in our socially-aware traffic flow is driven by a hierarchical policy where upper-level policy communicates genuine SVOs of all agents, which the lower-level policy takes as input. In Stage 2, each agent in the socially adversarial traffic flow is driven by the hierarchical policy where upper-level communicates mistaken SVOs, taken by the lower-level policy trained in Stage 1. Driving policy is adversarially trained through a zero-sum game formulation with upper-level policies, resulting in a policy with enhanced zero-shot transfer capability to unseen traffic flows. Comprehensive experiments on cross-validation verify the superior zero-shot transfer performance of our method.