 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeETP-R1: Evolving Topological Planning with Reinforcement Fine-tuning for Vision-Language Navigation in Continuous Environments
Dec 24, 2025Vision-Language Navigation in Continuous Environments (VLN-CE) requires an embodied agent to navigate towards target in continuous environments, following natural language instructions. While current graph-based methods offer an efficient, structured approach by abstracting the environment into a topological map and simplifying the action space to waypoint selection, they lag behind methods based on Large Vision-Language Models (LVLMs) in leveraging large-scale data and advanced training paradigms. In this paper, we try to bridge this gap by introducing ETP-R1, a framework that applies the paradigm of scaling up data and Reinforcement Fine-Tuning (RFT) to a graph-based VLN-CE model. To build a strong foundation, we first construct a high-quality, large-scale pretraining dataset using the Gemini API. This dataset consists of diverse, low-hallucination instructions for topological trajectories, providing rich supervision for our graph-based policy to map language to topological paths. This foundation is further strengthened by unifying data from both R2R and RxR tasks for joint pretraining. Building on this, we introduce a three-stage training paradigm, which culminates in the first application of closed-loop, online RFT to a graph-based VLN-CE model, powered by the Group Relative Policy Optimization (GRPO) algorithm. Extensive experiments demonstrate that our approach is highly effective, establishing new state-of-the-art performance across all major metrics on both the R2R-CE and RxR-CE benchmarks. Our code is available at https://github.com/Cepillar/ETP-R1.
Zero-shot Transfer Learning of Driving Policy via Socially Adversarial Traffic Flow
Apr 25, 2023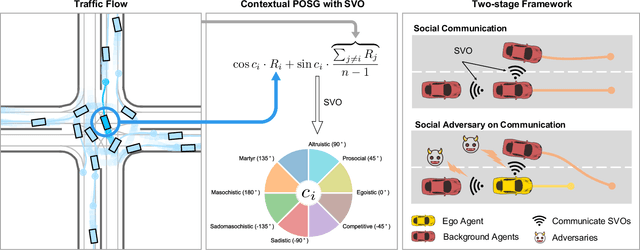
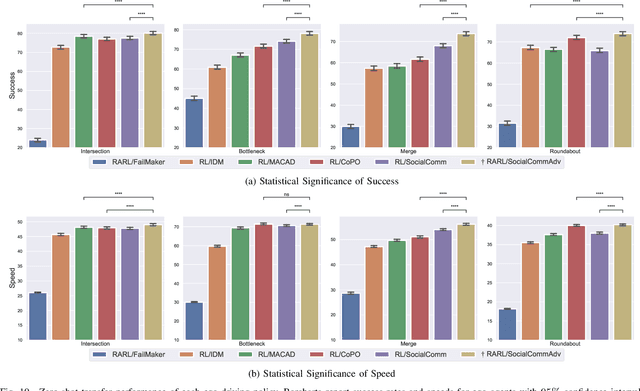
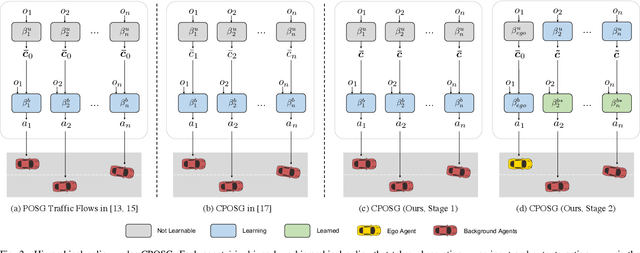
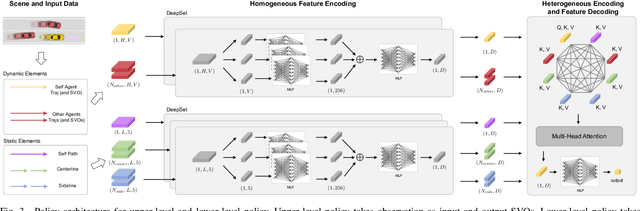
Acquiring driving policies that can transfer to unseen environments is challenging when driving in dense traffic flows. The design of traffic flow is essential and previous studies are unable to balance interaction and safety-criticism. To tackle this problem, we propose a socially adversarial traffic flow. We propose a Contextual Partially-Observable Stochastic Game to model traffic flow and assign Social Value Orientation (SVO) as context. We then adopt a two-stage framework. In Stage 1, each agent in our socially-aware traffic flow is driven by a hierarchical policy where upper-level policy communicates genuine SVOs of all agents, which the lower-level policy takes as input. In Stage 2, each agent in the socially adversarial traffic flow is driven by the hierarchical policy where upper-level communicates mistaken SVOs, taken by the lower-level policy trained in Stage 1. Driving policy is adversarially trained through a zero-sum game formulation with upper-level policies, resulting in a policy with enhanced zero-shot transfer capability to unseen traffic flows. Comprehensive experiments on cross-validation verify the superior zero-shot transfer performance of our method.
Domain Generalization for Vision-based Driving Trajectory Generation
Sep 22, 2021
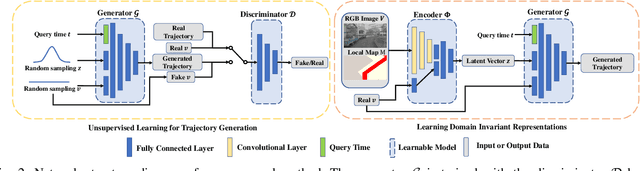
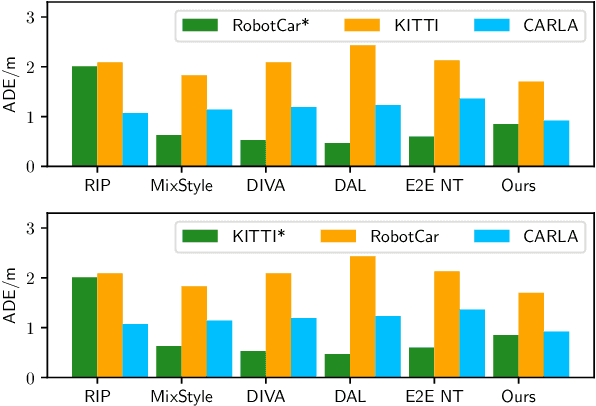

One of the challenges in vision-based driving trajectory generation is dealing with out-of-distribution scenarios. In this paper, we propose a domain generalization method for vision-based driving trajectory generation for autonomous vehicles in urban environments, which can be seen as a solution to extend the Invariant Risk Minimization (IRM) method in complex problems. We leverage an adversarial learning approach to train a trajectory generator as the decoder. Based on the pre-trained decoder, we infer the latent variables corresponding to the trajectories, and pre-train the encoder by regressing the inferred latent variable. Finally, we fix the decoder but fine-tune the encoder with the final trajectory loss. We compare our proposed method with the state-of-the-art trajectory generation method and some recent domain generalization methods on both datasets and simulation, demonstrating that our method has better generalization ability.
Learning Observation-Based Certifiable Safe Policy for Decentralized Multi-Robot Navigation
Sep 16, 2021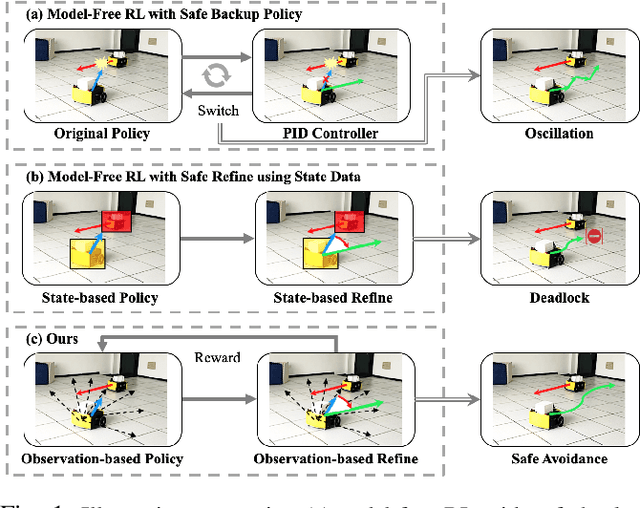
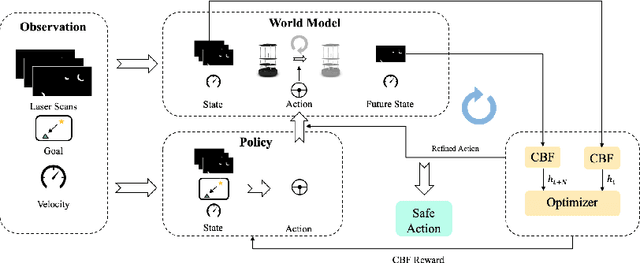


Safety is of great importance in multi-robot navigation problems. In this paper, we propose a control barrier function (CBF) based optimizer that ensures robot safety with both high probability and flexibility, using only sensor measurement. The optimizer takes action commands from the policy network as initial values and then provides refinement to drive the potentially dangerous ones back into safe regions. With the help of a deep transition model that predicts the evolution of surrounding dynamics and the consequences of different actions, the CBF module can guide the optimization in a reasonable time horizon. We also present a novel joint training framework that improves the cooperation between the Reinforcement Learning (RL) based policy and the CBF-based optimizer both in training and inference procedures by utilizing reward feedback from the CBF module. We observe that the policy using our method can achieve a higher success rate while maintaining the safety of multiple robots in significantly fewer episodes compared with other methods. Experiments are conducted in multiple scenarios both in simulation and the real world, the results demonstrate the effectiveness of our method in maintaining the safety of multi-robot navigation. Code is available at \url{https://github.com/YuxiangCui/MARL-OCBF
Socially-Aware Multi-Agent Following with 2D Laser Scans via Deep Reinforcement Learning and Potential Field
Sep 04, 2021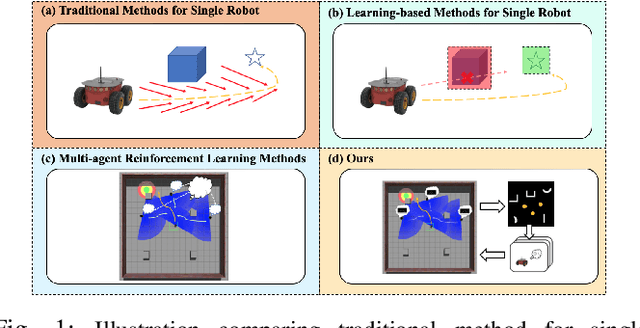
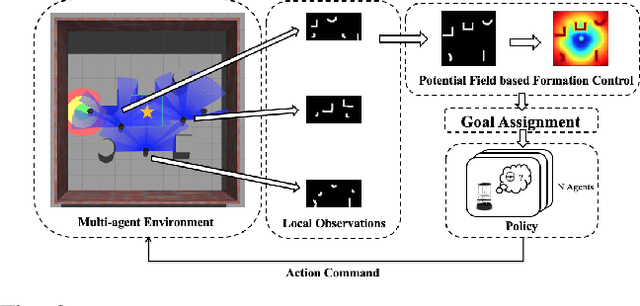
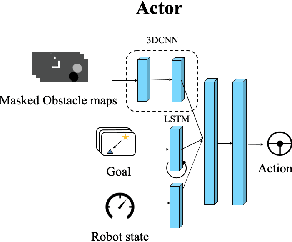
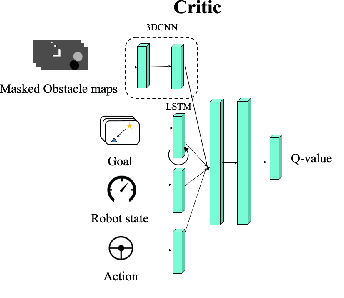
Target following in dynamic pedestrian environments is an important task for mobile robots. However, it is challenging to keep tracking the target while avoiding collisions in crowded environments, especially with only one robot. In this paper, we propose a multi-agent method for an arbitrary number of robots to follow the target in a socially-aware manner using only 2D laser scans. The multi-agent following problem is tackled by utilizing the complementary strengths of both reinforcement learning and potential field, in which the reinforcement learning part handles local interactions while navigating to the goals assigned by the potential field. Specifically, with the help of laser scans in obstacle map representation, the learning-based policy can help the robots avoid collisions with both static obstacles and dynamic obstacles like pedestrians in advance, namely socially aware. While the formation control and goal assignment for each robot is obtained from a target-centered potential field constructed using aggregated state information from all the following robots. Experiments are conducted in multiple settings, including random obstacle distributions and different numbers of robots. Results show that our method works successfully in unseen dynamic environments. The robots can follow the target in a socially compliant manner with only 2D laser scans.
Human-Robot Motion Retargeting via Neural Latent Optimization
Mar 16, 2021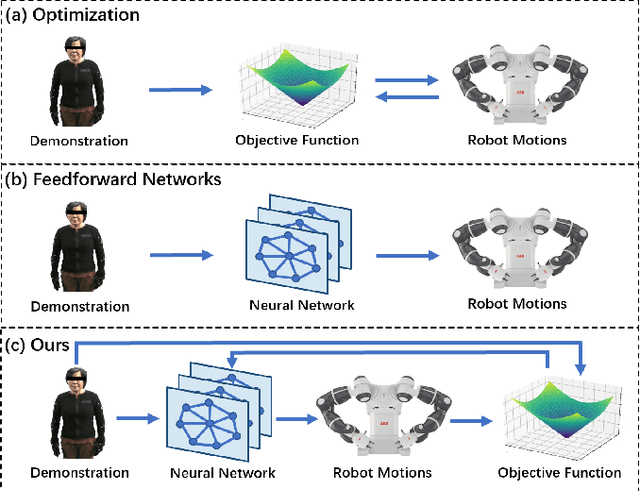
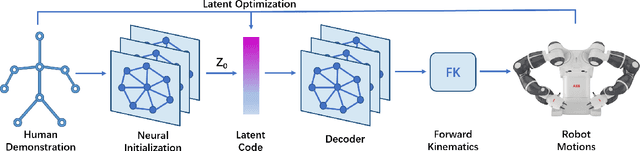

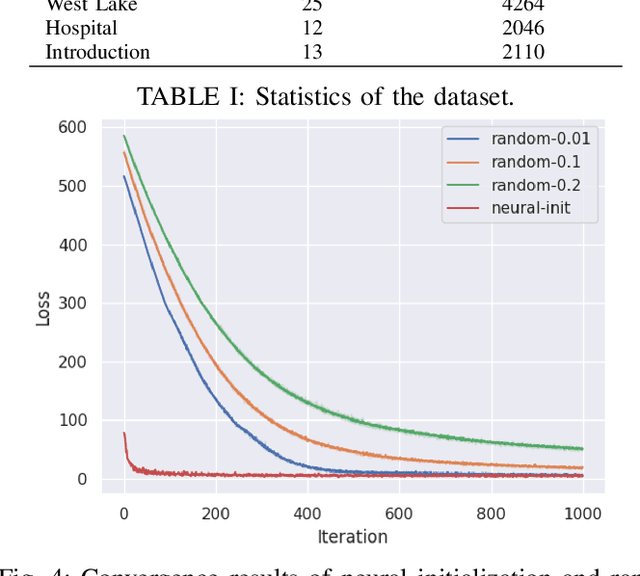
Motion retargeting from human to robot remains a very challenging task due to variations in the structure of humans and robots. Most traditional optimization-based algorithms solve this problem by minimizing an objective function, which is usually time-consuming and heavily dependent on good initialization. In contrast, methods with feedforward neural networks can learn prior knowledge from training data and quickly infer the results, but these methods also suffer from the generalization problem on unseen actions, leading to some infeasible results. In this paper, we propose a novel neural optimization approach taking advantages of both kinds of methods. A graph-based neural network is utilized to establish a mapping between the latent space and the robot motion space. Afterward, the retargeting results can be obtained by searching for the optimal vector in this latent space. In addition, a deep encoder also provides a promising initialization for better and faster convergence. We perform experiments on retargeting Chinese sign language to three different kinds of robots in the simulation environment, including ABB's YuMi dual-arm collaborative robot, NAO and Pepper. A real-world experiment is also conducted on the Yumi robot. Experimental results show that our method can retarget motion from human to robot with both efficiency and accuracy.
Learning World Transition Model for Socially Aware Robot Navigation
Nov 08, 2020


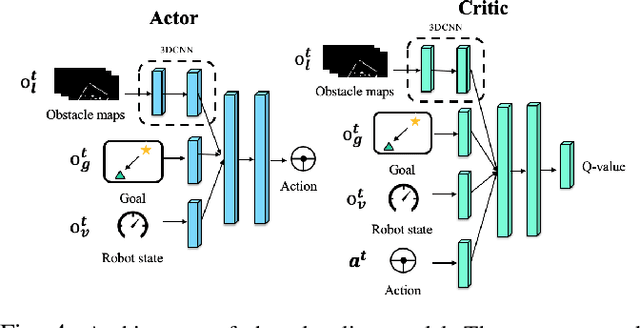
Moving in dynamic pedestrian environments is one of the important requirements for autonomous mobile robots. We present a model-based reinforcement learning approach for robots to navigate through crowded environments. The navigation policy is trained with both real interaction data from multi-agent simulation and virtual data from a deep transition model that predicts the evolution of surrounding dynamics of mobile robots. The model takes laser scan sequence and robot's own state as input and outputs steering control. The laser sequence is further transformed into stacked local obstacle maps disentangled from robot's ego motion to separate the static and dynamic obstacles, simplifying the model training. We observe that our method can be trained with significantly less real interaction data in simulator but achieve similar level of success rate in social navigation task compared with other methods. Experiments were conducted in multiple social scenarios both in simulation and on real robots, the learned policy can guide the robots to the final targets successfully while avoiding pedestrians in a socially compliant manner. Code is available at https://github.com/YuxiangCui/model-based-social-navigation