 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafe reinforcement learning with online filtering for fatigue-predictive human-robot task planning and allocation in production
Apr 14, 2026Human-robot collaborative manufacturing, a core aspect of Industry 5.0, emphasizes ergonomics to enhance worker well-being. This paper addresses the dynamic human-robot task planning and allocation (HRTPA) problem, which involves determining when to perform tasks and who should execute them to maximize efficiency while ensuring workers' physical fatigue remains within safe limits. The inclusion of fatigue constraints, combined with production dynamics, significantly increases the complexity of the HRTPA problem. Traditional fatigue-recovery models in HRTPA often rely on static, predefined hyperparameters. However, in practice, human fatigue sensitivity varies daily due to factors such as changed work conditions and insufficient sleep. To better capture this uncertainty, we treat fatigue-related parameters as inaccurate and estimate them online based on observed fatigue progression during production. To address these challenges, we propose PF-CD3Q, a safe reinforcement learning (safe RL) approach that integrates the particle filter with constrained dueling double deep Q-learning for real-time fatigue-predictive HRTPA. Specifically, we first develop PF-based estimators to track human fatigue and update fatigue model parameters in real-time. These estimators are then integrated into CD3Q by making task-level fatigue predictions during decision-making and excluding tasks that exceed fatigue limits, thereby constraining the action space and formulating the problem as a constrained Markov decision process (CMDP).
* This is the accepted manuscript of an article accepted for publication in \textit{Journal of Manufacturing Systems (Elsevier)
A hierarchical spatial-aware algorithm with efficient reinforcement learning for human-robot task planning and allocation in production
Apr 14, 2026In advanced manufacturing systems, humans and robots collaborate to conduct the production process. Effective task planning and allocation (TPA) is crucial for achieving high production efficiency, yet it remains challenging in complex and dynamic manufacturing environments. The dynamic nature of humans and robots, particularly the need to consider spatial information (e.g., humans' real-time position and the distance they need to move to complete a task), substantially complicates TPA. To address the above challenges, we decompose production tasks into manageable subtasks. We then implement a real-time hierarchical human-robot TPA algorithm, including a high-level agent for task planning and a low-level agent for task allocation. For the high-level agent, we propose an efficient buffer-based deep Q-learning method (EBQ), which reduces training time and enhances performance in production problems with long-term and sparse reward challenges. For the low-level agent, a path planning-based spatially aware method (SAP) is designed to allocate tasks to the appropriate human-robot resources, thereby achieving the corresponding sequential subtasks. We conducted experiments on a complex real-time production process in a 3D simulator. The results demonstrate that our proposed EBQ&SAP method effectively addresses human-robot TPA problems in complex and dynamic production processes.
* This is the accepted manuscript of a journal article accepted for publication in Robotics and Computer-Integrated Manufacturing (Elsevier)
A Two-stage Based Social Preference Recognition in Multi-Agent Autonomous Driving System
Oct 05, 2023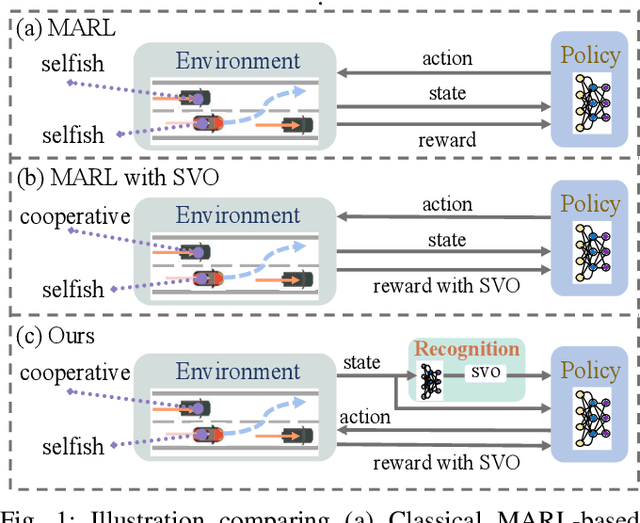
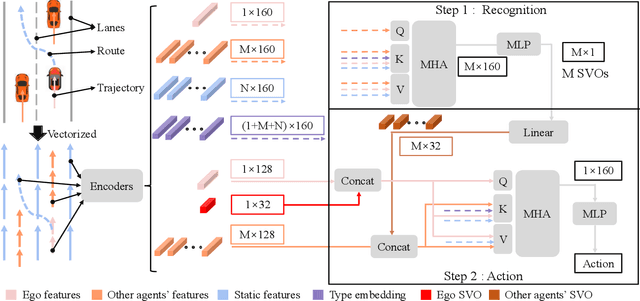
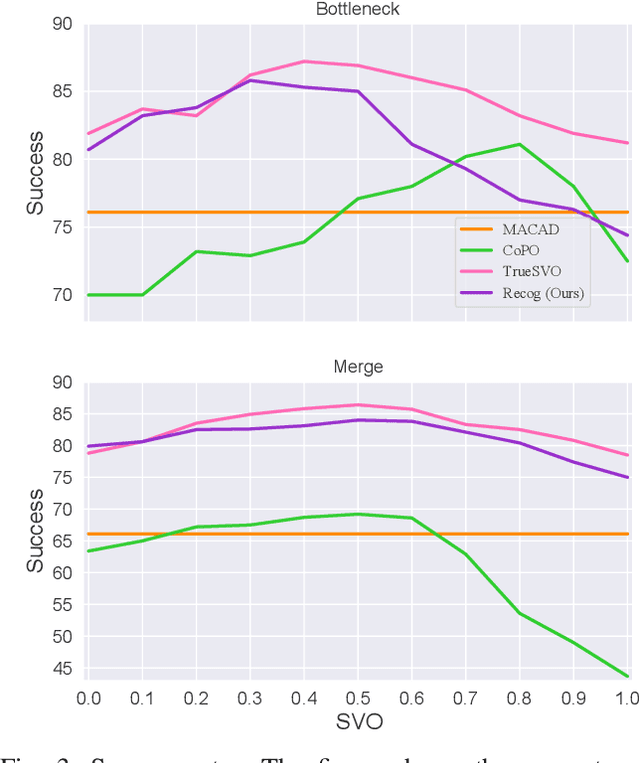
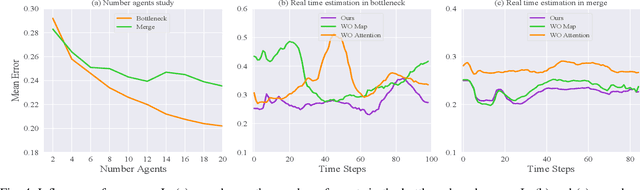
Multi-Agent Reinforcement Learning (MARL) has become a promising solution for constructing a multi-agent autonomous driving system (MADS) in complex and dense scenarios. But most methods consider agents acting selfishly, which leads to conflict behaviors. Some existing works incorporate the concept of social value orientation (SVO) to promote coordination, but they lack the knowledge of other agents' SVOs, resulting in conservative maneuvers. In this paper, we aim to tackle the mentioned problem by enabling the agents to understand other agents' SVOs. To accomplish this, we propose a two-stage system framework. Firstly, we train a policy by allowing the agents to share their ground truth SVOs to establish a coordinated traffic flow. Secondly, we develop a recognition network that estimates agents' SVOs and integrates it with the policy trained in the first stage. Experiments demonstrate that our developed method significantly improves the performance of the driving policy in MADS compared to two state-of-the-art MARL algorithms.
Zero-shot Transfer Learning of Driving Policy via Socially Adversarial Traffic Flow
Apr 25, 2023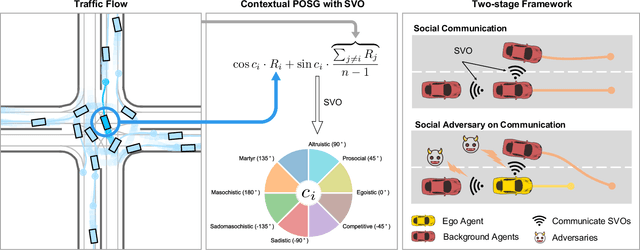
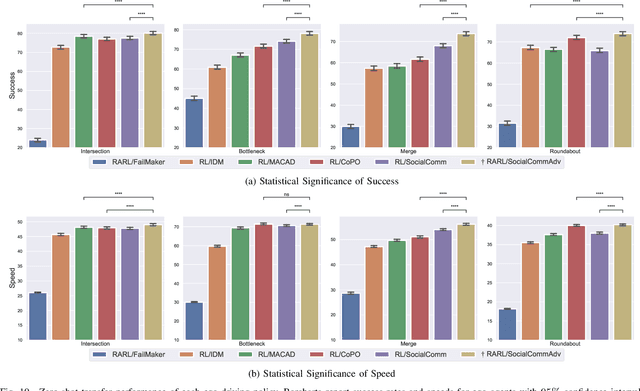
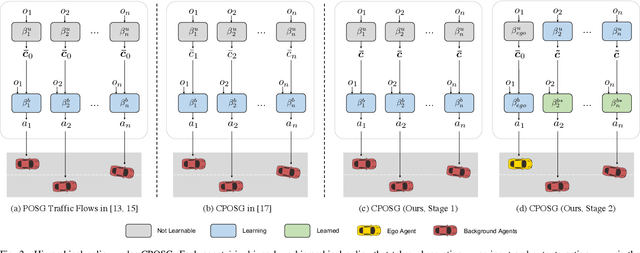
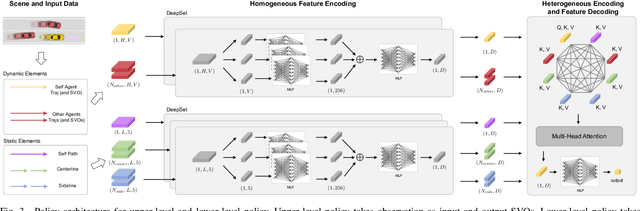
Acquiring driving policies that can transfer to unseen environments is challenging when driving in dense traffic flows. The design of traffic flow is essential and previous studies are unable to balance interaction and safety-criticism. To tackle this problem, we propose a socially adversarial traffic flow. We propose a Contextual Partially-Observable Stochastic Game to model traffic flow and assign Social Value Orientation (SVO) as context. We then adopt a two-stage framework. In Stage 1, each agent in our socially-aware traffic flow is driven by a hierarchical policy where upper-level policy communicates genuine SVOs of all agents, which the lower-level policy takes as input. In Stage 2, each agent in the socially adversarial traffic flow is driven by the hierarchical policy where upper-level communicates mistaken SVOs, taken by the lower-level policy trained in Stage 1. Driving policy is adversarially trained through a zero-sum game formulation with upper-level policies, resulting in a policy with enhanced zero-shot transfer capability to unseen traffic flows. Comprehensive experiments on cross-validation verify the superior zero-shot transfer performance of our method.