 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbing the Critical Point (CritPt) of AI Reasoning: a Frontier Physics Research Benchmark
Oct 01, 2025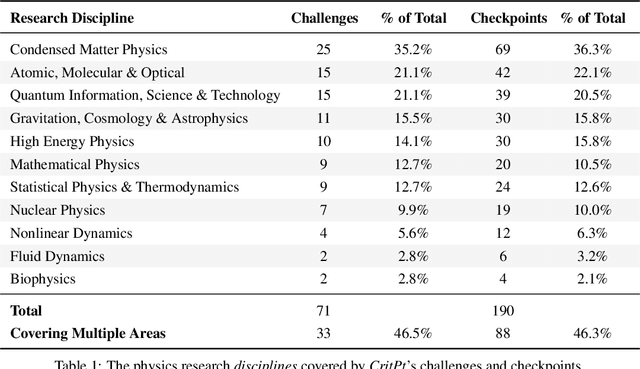
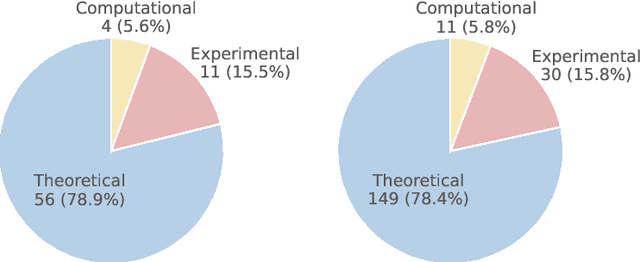
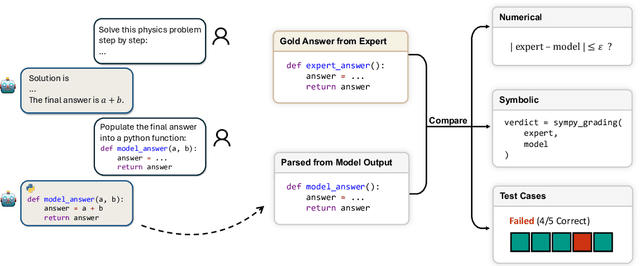

While large language models (LLMs) with reasoning capabilities are progressing rapidly on high-school math competitions and coding, can they reason effectively through complex, open-ended challenges found in frontier physics research? And crucially, what kinds of reasoning tasks do physicists want LLMs to assist with? To address these questions, we present the CritPt (Complex Research using Integrated Thinking - Physics Test, pronounced "critical point"), the first benchmark designed to test LLMs on unpublished, research-level reasoning tasks that broadly covers modern physics research areas, including condensed matter, quantum physics, atomic, molecular & optical physics, astrophysics, high energy physics, mathematical physics, statistical physics, nuclear physics, nonlinear dynamics, fluid dynamics and biophysics. CritPt consists of 71 composite research challenges designed to simulate full-scale research projects at the entry level, which are also decomposed to 190 simpler checkpoint tasks for more fine-grained insights. All problems are newly created by 50+ active physics researchers based on their own research. Every problem is hand-curated to admit a guess-resistant and machine-verifiable answer and is evaluated by an automated grading pipeline heavily customized for advanced physics-specific output formats. We find that while current state-of-the-art LLMs show early promise on isolated checkpoints, they remain far from being able to reliably solve full research-scale challenges: the best average accuracy among base models is only 4.0% , achieved by GPT-5 (high), moderately rising to around 10% when equipped with coding tools. Through the realistic yet standardized evaluation offered by CritPt, we highlight a large disconnect between current model capabilities and realistic physics research demands, offering a foundation to guide the development of scientifically grounded AI tools.
SpeHeatal: A Cluster-Enhanced Segmentation Method for Sperm Morphology Analysis
Feb 18, 2025The accurate assessment of sperm morphology is crucial in andrological diagnostics, where the segmentation of sperm images presents significant challenges. Existing approaches frequently rely on large annotated datasets and often struggle with the segmentation of overlapping sperm and the presence of dye impurities. To address these challenges, this paper first analyzes the issue of overlapping sperm tails from a geometric perspective and introduces a novel clustering algorithm, Con2Dis, which effectively segments overlapping tails by considering three essential factors: CONnectivity, CONformity, and DIStance. Building on this foundation, we propose an unsupervised method, SpeHeatal, designed for the comprehensive segmentation of the SPErm HEAd and TAiL. SpeHeatal employs the Segment Anything Model(SAM) to generate masks for sperm heads while filtering out dye impurities, utilizes Con2Dis to segment tails, and then applies a tailored mask splicing technique to produce complete sperm masks. Experimental results underscore the superior performance of SpeHeatal, particularly in handling images with overlapping sperm.
Zero-shot Transfer Learning of Driving Policy via Socially Adversarial Traffic Flow
Apr 25, 2023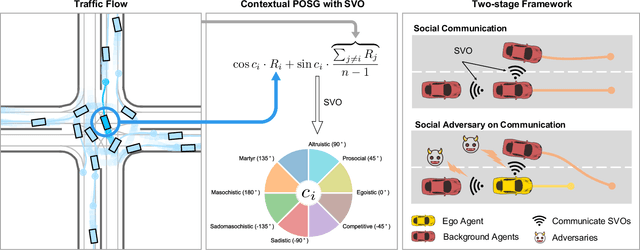
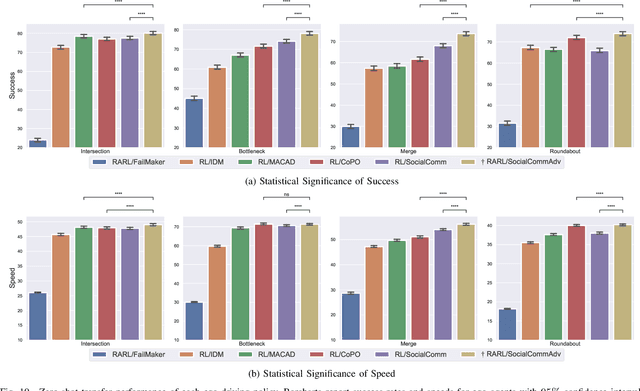
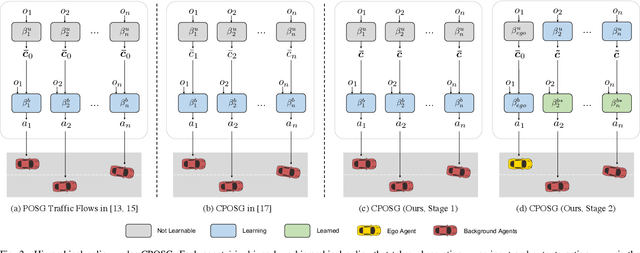
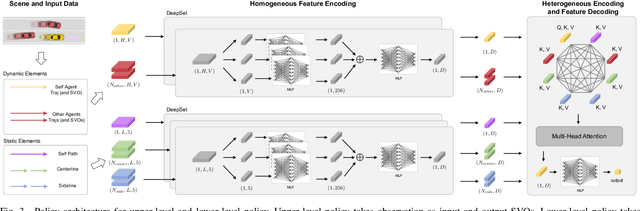
Acquiring driving policies that can transfer to unseen environments is challenging when driving in dense traffic flows. The design of traffic flow is essential and previous studies are unable to balance interaction and safety-criticism. To tackle this problem, we propose a socially adversarial traffic flow. We propose a Contextual Partially-Observable Stochastic Game to model traffic flow and assign Social Value Orientation (SVO) as context. We then adopt a two-stage framework. In Stage 1, each agent in our socially-aware traffic flow is driven by a hierarchical policy where upper-level policy communicates genuine SVOs of all agents, which the lower-level policy takes as input. In Stage 2, each agent in the socially adversarial traffic flow is driven by the hierarchical policy where upper-level communicates mistaken SVOs, taken by the lower-level policy trained in Stage 1. Driving policy is adversarially trained through a zero-sum game formulation with upper-level policies, resulting in a policy with enhanced zero-shot transfer capability to unseen traffic flows. Comprehensive experiments on cross-validation verify the superior zero-shot transfer performance of our method.
Least Square Estimation Network for Depth Completion
Mar 07, 2022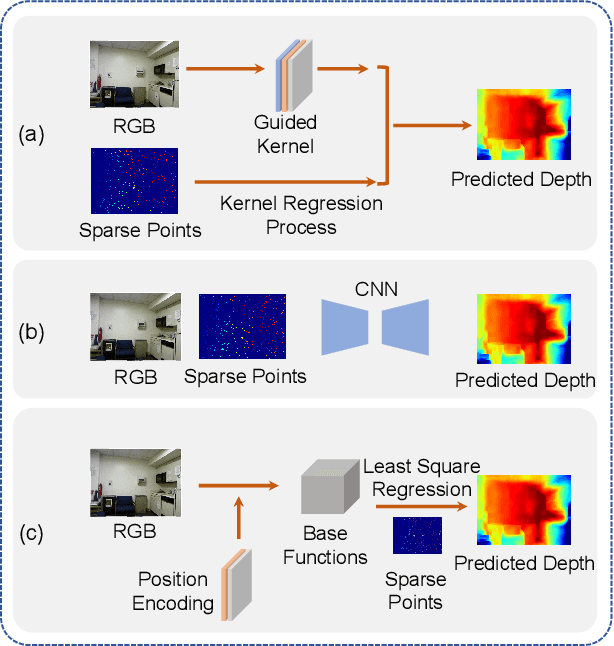
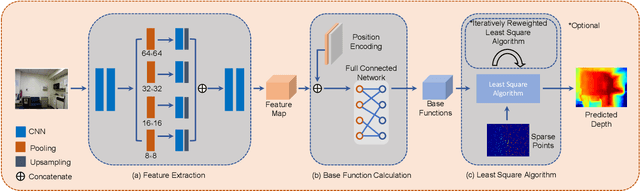
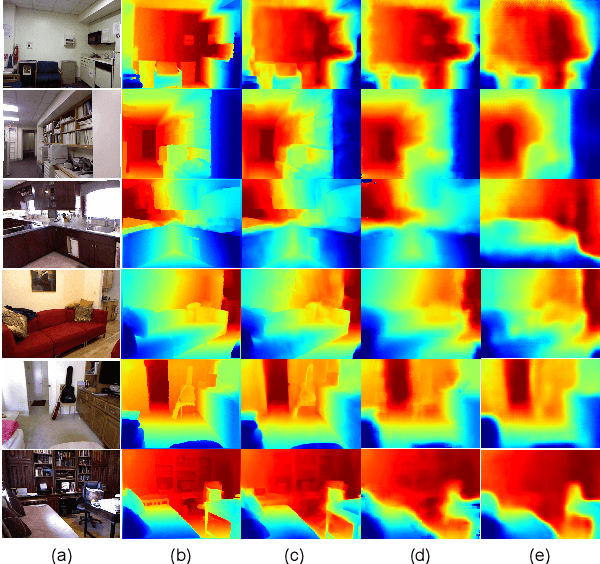
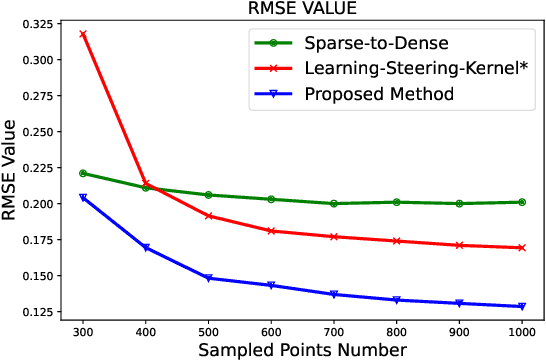
Depth completion is a fundamental task in computer vision and robotics research. Many previous works complete the dense depth map with neural networks directly but most of them are non-interpretable and can not generalize to different situations well. In this paper, we propose an effective image representation method for depth completion tasks. The input of our system is a monocular camera frame and the synchronous sparse depth map. The output of our system is a dense per-pixel depth map of the frame. First we use a neural network to transform each pixel into a feature vector, which we call base functions. Then we pick out the known pixels' base functions and their depth values. We use a linear least square algorithm to fit the base functions and the depth values. Then we get the weights estimated from the least square algorithm. Finally, we apply the weights to the whole image and predict the final depth map. Our method is interpretable so it can generalize well. Experiments show that our results beat the state-of-the-art on NYU-Depth-V2 dataset both in accuracy and runtime. Moreover, experiments show that our method can generalize well on different numbers of sparse points and different datasets.
Domain Generalization for Vision-based Driving Trajectory Generation
Sep 22, 2021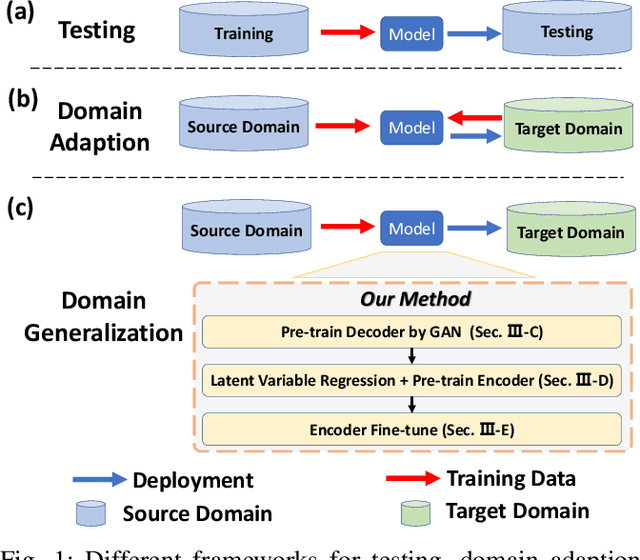
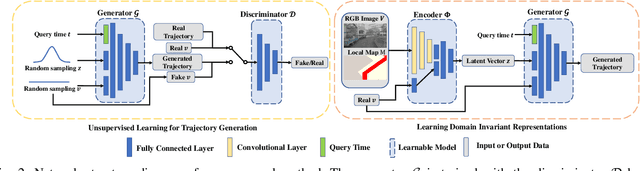
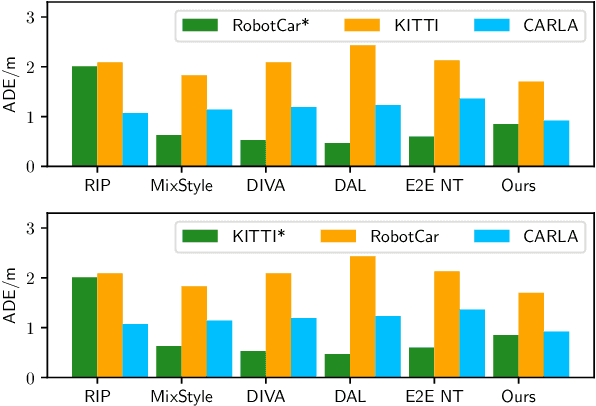

One of the challenges in vision-based driving trajectory generation is dealing with out-of-distribution scenarios. In this paper, we propose a domain generalization method for vision-based driving trajectory generation for autonomous vehicles in urban environments, which can be seen as a solution to extend the Invariant Risk Minimization (IRM) method in complex problems. We leverage an adversarial learning approach to train a trajectory generator as the decoder. Based on the pre-trained decoder, we infer the latent variables corresponding to the trajectories, and pre-train the encoder by regressing the inferred latent variable. Finally, we fix the decoder but fine-tune the encoder with the final trajectory loss. We compare our proposed method with the state-of-the-art trajectory generation method and some recent domain generalization methods on both datasets and simulation, demonstrating that our method has better generalization ability.
Learn to Differ: Sim2Real Small Defection Segmentation Network
Mar 07, 2021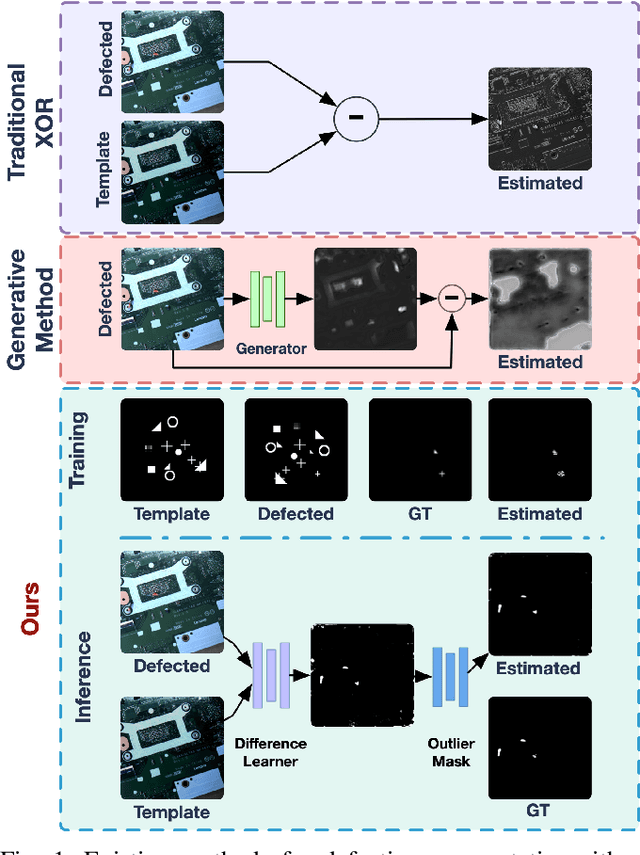
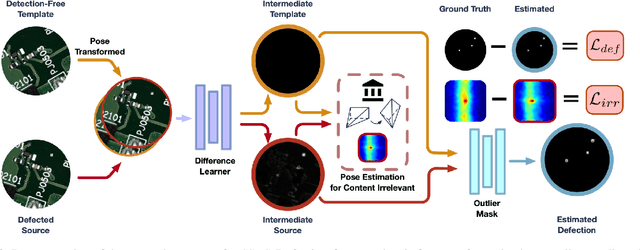

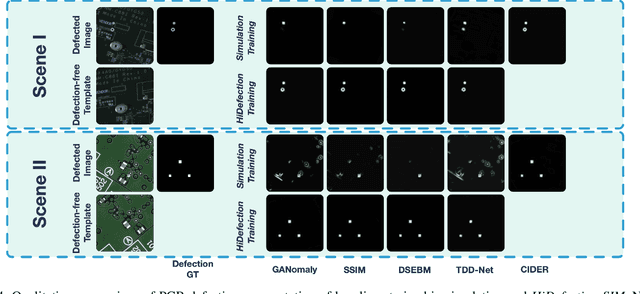
Recent studies on deep-learning-based small defection segmentation approaches are trained in specific settings and tend to be limited by fixed context. Throughout the training, the network inevitably learns the representation of the background of the training data before figuring out the defection. They underperform in the inference stage once the context changed and can only be solved by training in every new setting. This eventually leads to the limitation in practical robotic applications where contexts keep varying. To cope with this, instead of training a network context by context and hoping it to generalize, why not stop misleading it with any limited context and start training it with pure simulation? In this paper, we propose the network SSDS that learns a way of distinguishing small defections between two images regardless of the context, so that the network can be trained once for all. A small defection detection layer utilizing the pose sensitivity of phase correlation between images is introduced and is followed by an outlier masking layer. The network is trained on randomly generated simulated data with simple shapes and is generalized across the real world. Finally, SSDS is validated on real-world collected data and demonstrates the ability that even when trained in cheap simulation, SSDS can still find small defections in the real world showing the effectiveness and its potential for practical applications.
Pose Randomization for Weakly Paired Image Style Translation
Oct 31, 2020



Utilizing the trained model under different conditions without data annotation is attractive for robot applications. Towards this goal, one class of methods is to translate the image style from the training environment to the current one. Conventional studies on image style translation mainly focus on two settings: paired data on images from two domains with exactly aligned content, and unpaired data, with independent content. In this paper, we would like to propose a new setting, where the content in the two images is aligned with error in poses. We consider that this setting is more practical since robots with various sensors are able to align the data up to some error level, even with different styles. To solve this problem, we propose PRoGAN to learn a style translator by intentionally transforming the original domain images with a noisy pose, then matching the distribution of translated transformed images and the distribution of the target domain images. The adversarial training enforces the network to learn the style translation, avoiding being entangled with other variations. In addition, we propose two pose estimation based self-supervised tasks to further improve the performance. Finally, PRoGAN is validated on both simulated and real-world collected data to show the effectiveness. Results on down-stream tasks, classification, road segmentation, object detection, and feature matching show its potential for real applications. https://github.com/wrld/PRoGAN .
Imitation Learning of Hierarchical Driving Model: from Continuous Intention to Continuous Trajectory
Oct 20, 2020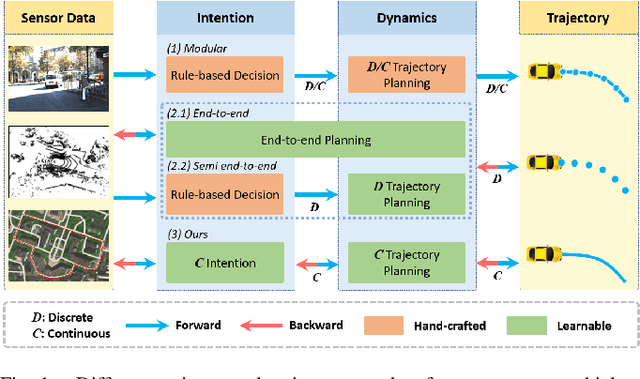
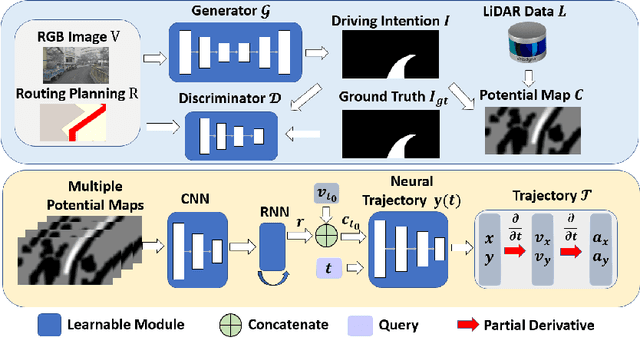
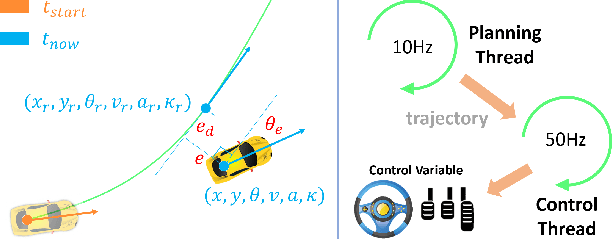

One of the challenges to reduce the gap between the machine and the human level driving is how to endow the system with the learning capacity to deal with the coupled complexity of environments, intentions, and dynamics. In this paper, we propose a hierarchical driving model with explicit model of continuous intention and continuous dynamics, which decouples the complexity in the observation-to-action reasoning in the human driving data. Specifically, the continuous intention module takes the route planning and perception to generate a potential map encoded with obstacles and goals being expressed as grid based potentials. Then, the potential map is regarded as a condition, together with the current dynamics, to generate the trajectory. The trajectory is modeled by a network based continuous function approximator, which naturally reserves the derivatives for high-order supervision without any additional parameters. Finally, we validate our method on both datasets and simulators, demonstrating superior performance. The method is also deployed on the real vehicle with loop latency, validating its effectiveness.
Collaborative Localization of Aerial and Ground Mobile Robots through Orthomosaic Map
Jul 22, 2020



With the deepening of research on the SLAM system, the possibility of cooperative SLAM with multi-robots has been proposed. This paper presents a map matching and localization approach considering the cooperative SLAM of an aerial-ground system. The proposed approach aims to help precisely matching the map constructed by two independent systems that have large scale variance of viewpoints of the same route and eventually enables the ground mobile robot to localize itself in the global map given by the drone. It contains dense mapping with Elevation Map and software "Metashape", map matching with a proposed template matching algorithm, weighted normalized cross-correlation (WNCC) and localization with particle filter. The approach enables map matching for cooperative SLAM with the feasibility of multiple scene sensors, varies from stereo cameras to lidars, and is insensitive to the synchronization of the two systems. We demonstrate the accuracy, robustness, and the speed of the approach under experiments of the Aero-Ground Dataset.
Multi-agent Collaboration for Feasible Collaborative Behavior Construction and Evaluation
Sep 30, 2019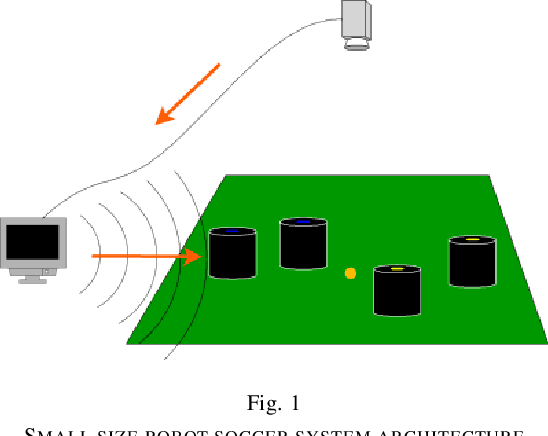
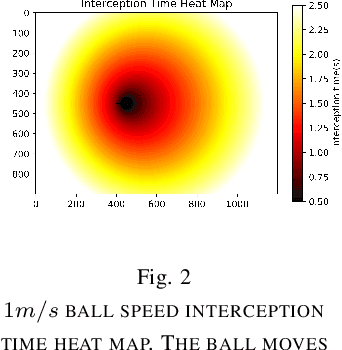
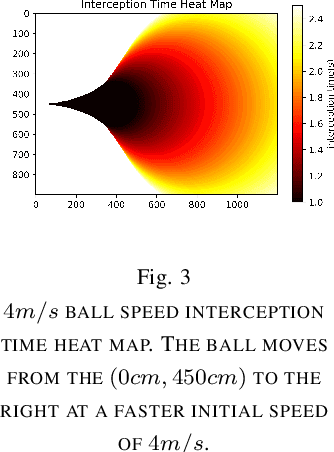
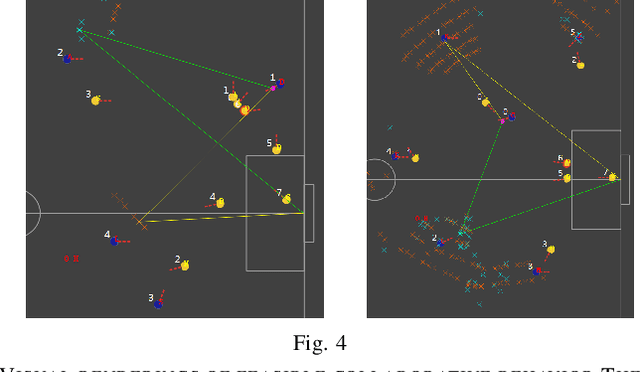
In the case of the two-person zero-sum stochastic game with a central controller, this paper proposes a best collaborative behavior search and selection algorithm based on reinforcement learning, in response to how to choose the best collaborative object and action for the central controller. In view of the existing multi-agent collaboration and confrontation reinforcement learning methods, the methods of traversing all actions in a certain state leads to the problem of long calculation time and unsafe policy exploration. This paper proposes to construct a feasible collaborative behavior set by using action space discretization, establishing models of both sides, model-based prediction and parallel search. Then, we use the deep q-learning method in reinforcement learning to train the scoring function to select the optimal collaboration behavior from the feasible collaborative behavior set. This method enables efficient and accurate calculation in an environment with strong confrontation, high dynamics and a large number of agents, which is verified by the RoboCup Small Size League robots passing collaboration.