 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScore-Repellent Monte Carlo: Toward Efficient Non-Markovian Sampler with Constant Memory in General State Spaces
Apr 24, 2026History-dependent sampling can reduce long-run Monte Carlo variance by discouraging redundant revisits, but existing schemes typically encode history through empirical measure on finite state spaces, which is infeasible in high-dimensional discrete configuration spaces or ill-posed in continuous domains. We propose Score-Repellent Monte Carlo (SRMC) framework that summarizes trajectory history by a running average of score evaluations in $R^d$, where $d$ is the dimension of the score and state representation. This history is converted into a surrogate target through an exponential score tilt, indexed with $α$ that represents the strength of repellence in controlling the magnitude of the history-based repulsion. The surrogate family is normalization-free in the standard MCMC sense, yielding a generic wrapper: at each iteration, any base kernel targeting $π$ can instead be run on the current surrogate $π_{θ_n}$ while the history is updated online. We analyze the coupled evolution of the history recursion and Monte Carlo estimators using stochastic approximation with controlled Markovian noise, establishing almost sure convergence and a joint central limit theorem. We further identify regimes in which the asymptotic covariance decreases as $α$ increases, with scaling $O(1/α)$, extending the near-zero-variance effect of finite-state history-dependent samplers to general state spaces with constant memory. Experiments on continuous targets and discrete energy-based models demonstrate improved estimator variance and mode coverage, while retaining $O(d)$ memory usage and modest per-iteration overhead.
Positioning Modular Co-Design in Future HRI Design Research
Feb 23, 2026Design-oriented HRI is increasingly interested in robots as long-term companions, yet many designs still assume a fixed form and a stable set of functions. We present an ongoing design research program that treats modularity as a designerly medium - a way to make long-term human-robot relationships discussable and material through co-design. Across a series of lifespan-oriented co-design activities, participants repeatedly reconfigured the same robot for different life stages, using modular parts to express changing needs, values, and roles. From these outcomes, we articulate PAS (Personalization-Adaptability-Sustainability) as a human-centered lens on how people enact modularity in practice: configuring for self-expression, adapting across transitions, and sustaining robots through repair, reuse, and continuity. We then sketch next steps toward a fabrication-aware, community-extensible modular platform and propose evaluation criteria for designerly HRI work that prioritize expressive adequacy, lifespan plausibility, repairability-in-use, and responsible stewardship - not only usability or performance.
FlowHOI: Flow-based Semantics-Grounded Generation of Hand-Object Interactions for Dexterous Robot Manipulation
Feb 13, 2026Recent vision-language-action (VLA) models can generate plausible end-effector motions, yet they often fail in long-horizon, contact-rich tasks because the underlying hand-object interaction (HOI) structure is not explicitly represented. An embodiment-agnostic interaction representation that captures this structure would make manipulation behaviors easier to validate and transfer across robots. We propose FlowHOI, a two-stage flow-matching framework that generates semantically grounded, temporally coherent HOI sequences, comprising hand poses, object poses, and hand-object contact states, conditioned on an egocentric observation, a language instruction, and a 3D Gaussian splatting (3DGS) scene reconstruction. We decouple geometry-centric grasping from semantics-centric manipulation, conditioning the latter on compact 3D scene tokens and employing a motion-text alignment loss to semantically ground the generated interactions in both the physical scene layout and the language instruction. To address the scarcity of high-fidelity HOI supervision, we introduce a reconstruction pipeline that recovers aligned hand-object trajectories and meshes from large-scale egocentric videos, yielding an HOI prior for robust generation. Across the GRAB and HOT3D benchmarks, FlowHOI achieves the highest action recognition accuracy and a 1.7$\times$ higher physics simulation success rate than the strongest diffusion-based baseline, while delivering a 40$\times$ inference speedup. We further demonstrate real-robot execution on four dexterous manipulation tasks, illustrating the feasibility of retargeting generated HOI representations to real-robot execution pipelines.
TacUMI: A Multi-Modal Universal Manipulation Interface for Contact-Rich Tasks
Jan 21, 2026Task decomposition is critical for understanding and learning complex long-horizon manipulation tasks. Especially for tasks involving rich physical interactions, relying solely on visual observations and robot proprioceptive information often fails to reveal the underlying event transitions. This raises the requirement for efficient collection of high-quality multi-modal data as well as robust segmentation method to decompose demonstrations into meaningful modules. Building on the idea of the handheld demonstration device Universal Manipulation Interface (UMI), we introduce TacUMI, a multi-modal data collection system that integrates additionally ViTac sensors, force-torque sensor, and pose tracker into a compact, robot-compatible gripper design, which enables synchronized acquisition of all these modalities during human demonstrations. We then propose a multi-modal segmentation framework that leverages temporal models to detect semantically meaningful event boundaries in sequential manipulations. Evaluation on a challenging cable mounting task shows more than 90 percent segmentation accuracy and highlights a remarkable improvement with more modalities, which validates that TacUMI establishes a practical foundation for both scalable collection and segmentation of multi-modal demonstrations in contact-rich tasks.
Elliptical K-Nearest Neighbors -- Path Optimization via Coulomb's Law and Invalid Vertices in C-space Obstacles
Aug 27, 2025Path planning has long been an important and active research area in robotics. To address challenges in high-dimensional motion planning, this study introduces the Force Direction Informed Trees (FDIT*), a sampling-based planner designed to enhance speed and cost-effectiveness in pathfinding. FDIT* builds upon the state-of-the-art informed sampling planner, the Effort Informed Trees (EIT*), by capitalizing on often-overlooked information in invalid vertices. It incorporates principles of physical force, particularly Coulomb's law. This approach proposes the elliptical $k$-nearest neighbors search method, enabling fast convergence navigation and avoiding high solution cost or infeasible paths by exploring more problem-specific search-worthy areas. It demonstrates benefits in search efficiency and cost reduction, particularly in confined, high-dimensional environments. It can be viewed as an extension of nearest neighbors search techniques. Fusing invalid vertex data with physical dynamics facilitates force-direction-based search regions, resulting in an improved convergence rate to the optimum. FDIT* outperforms existing single-query, sampling-based planners on the tested problems in R^4 to R^16 and has been demonstrated on a real-world mobile manipulation task.
Learning Task Planning from Multi-Modal Demonstration for Multi-Stage Contact-Rich Manipulation
Sep 18, 2024



Large Language Models (LLMs) have gained popularity in task planning for long-horizon manipulation tasks. To enhance the validity of LLM-generated plans, visual demonstrations and online videos have been widely employed to guide the planning process. However, for manipulation tasks involving subtle movements but rich contact interactions, visual perception alone may be insufficient for the LLM to fully interpret the demonstration. Additionally, visual data provides limited information on force-related parameters and conditions, which are crucial for effective execution on real robots. In this paper, we introduce an in-context learning framework that incorporates tactile and force-torque information from human demonstrations to enhance LLMs' ability to generate plans for new task scenarios. We propose a bootstrapped reasoning pipeline that sequentially integrates each modality into a comprehensive task plan. This task plan is then used as a reference for planning in new task configurations. Real-world experiments on two different sequential manipulation tasks demonstrate the effectiveness of our framework in improving LLMs' understanding of multi-modal demonstrations and enhancing the overall planning performance.
TacDiffusion: Force-domain Diffusion Policy for Precise Tactile Manipulation
Sep 17, 2024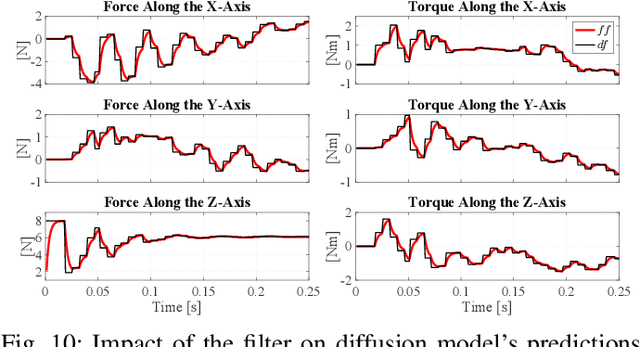
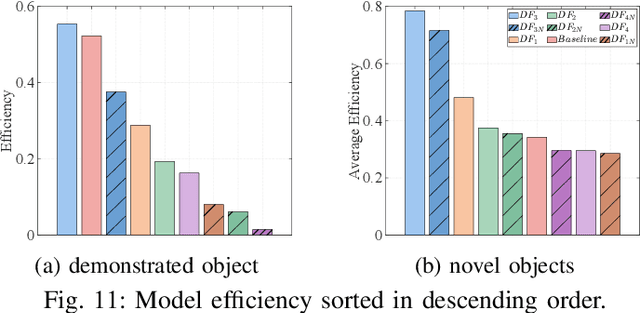
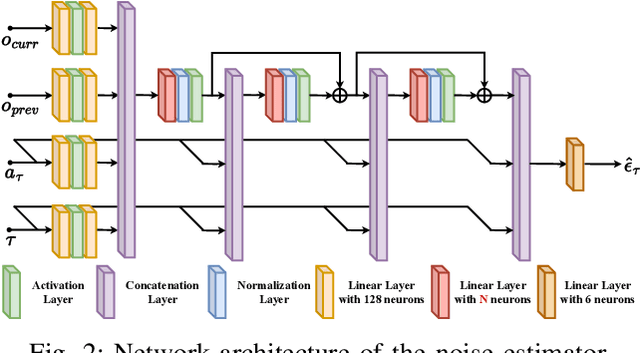

Assembly is a crucial skill for robots in both modern manufacturing and service robotics. However, mastering transferable insertion skills that can handle a variety of high-precision assembly tasks remains a significant challenge. This paper presents a novel framework that utilizes diffusion models to generate 6D wrench for high-precision tactile robotic insertion tasks. It learns from demonstrations performed on a single task and achieves a zero-shot transfer success rate of 95.7% across various novel high-precision tasks. Our method effectively inherits the self-adaptability demonstrated by our previous work. In this framework, we address the frequency misalignment between the diffusion policy and the real-time control loop with a dynamic system-based filter, significantly improving the task success rate by 9.15%. Furthermore, we provide a practical guideline regarding the trade-off between diffusion models' inference ability and speed.
Time-Optimized Trajectory Planning for Non-Prehensile Object Transportation in 3D
Aug 29, 2024Non-prehensile object transportation offers a way to enhance robotic performance in object manipulation tasks, especially with unstable objects. Effective trajectory planning requires simultaneous consideration of robot motion constraints and object stability. Here, we introduce a physical model for object stability and propose a novel trajectory planning approach for non-prehensile transportation along arbitrary straight lines in 3D space. Validation with a 7-DoF Franka Panda robot confirms improved transportation speed via tray rotation integration while ensuring object stability and robot motion constraints.
Identification and validation of the dynamic model of a tendon-driven anthropomorphic finger
Aug 23, 2024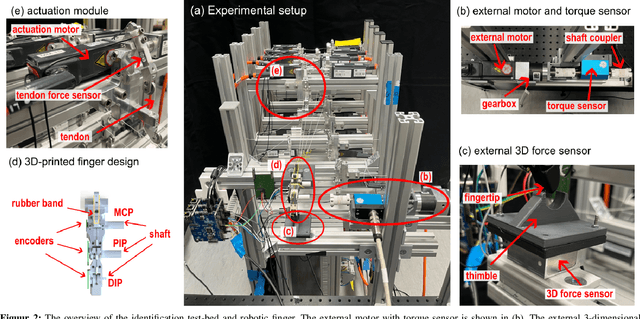
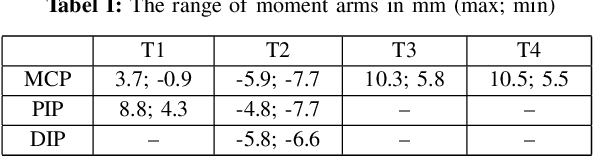
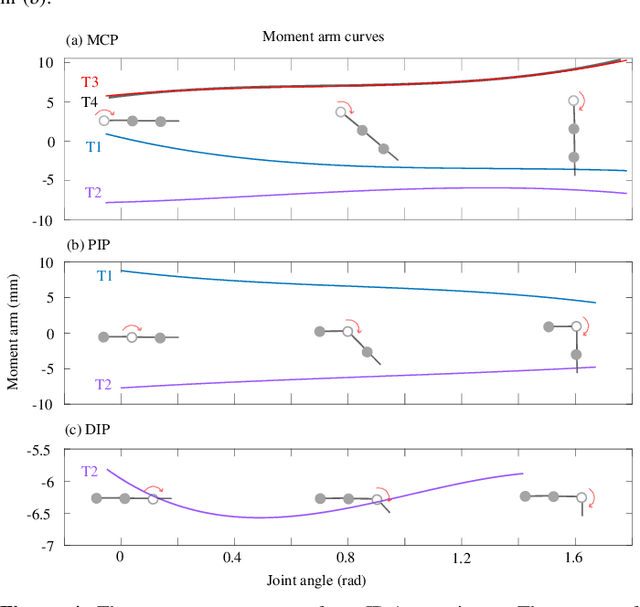
This study addresses the absence of an identification framework to quantify a comprehensive dynamic model of human and anthropomorphic tendon-driven fingers, which is necessary to investigate the physiological properties of human fingers and improve the control of robotic hands. First, a generalized dynamic model was formulated, which takes into account the inherent properties of such a mechanical system. This includes rigid-body dynamics, coupling matrix, joint viscoelasticity, and tendon friction. Then, we propose a methodology comprising a series of experiments, for step-wise identification and validation of this dynamic model. Moreover, an experimental setup was designed and constructed that features actuation modules and peripheral sensors to facilitate the identification process. To verify the proposed methodology, a 3D-printed robotic finger based on the index finger design of the Dexmart hand was developed, and the proposed experiments were executed to identify and validate its dynamic model. This study could be extended to explore the identification of cadaver hands, aiming for a consistent dataset from a single cadaver specimen to improve the development of musculoskeletal hand models.
OPENGRASP-LITE Version 1.0: A Tactile Artificial Hand with a Compliant Linkage Mechanism
Aug 05, 2024
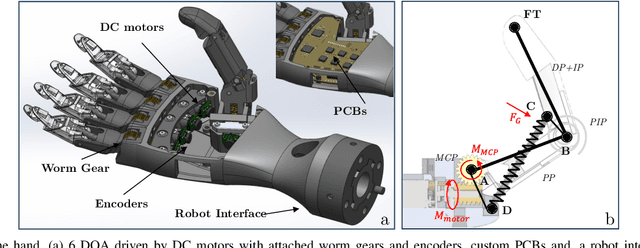
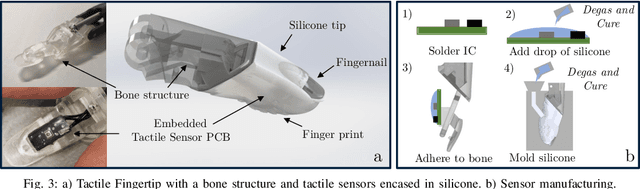
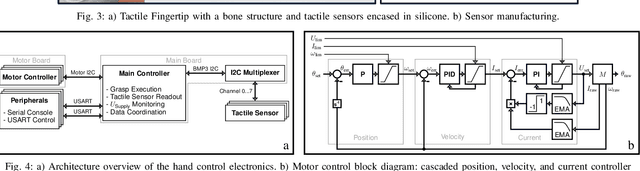
Recent research has seen notable progress in the development of linkage-based artificial hands. While previous designs have focused on adaptive grasping, dexterity and biomimetic artificial skin, only a few systems have proposed a lightweight, accessible solution integrating tactile sensing with a compliant linkage-based mechanism. This paper introduces OPENGRASP LITE, an open-source, highly integrated, tactile, and lightweight artificial hand. Leveraging compliant linkage systems and MEMS barometer-based tactile sensing, it offers versatile grasping capabilities with six degrees of actuation. By providing tactile sensors and enabling soft grasping, it serves as an accessible platform for further research in tactile artificial hands.