 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDreaming the Unseen: World Model-regularized Diffusion Policy for Out-of-Distribution Robustness
Mar 22, 2026Diffusion policies excel at visuomotor control but often fail catastrophically under severe out-of-distribution (OOD) disturbances, such as unexpected object displacements or visual corruptions. To address this vulnerability, we introduce the Dream Diffusion Policy (DDP), a framework that deeply integrates a diffusion world model into the policy's training objective via a shared 3D visual encoder. This co-optimization endows the policy with robust state-prediction capabilities. When encountering sudden OOD anomalies during inference, DDP detects the real-imagination discrepancy and actively abandons the corrupted visual stream. Instead, it relies on its internal "imagination" (autoregressively forecasted latent dynamics) to safely bypass the disruption, generating imagined trajectories before smoothly realigning with physical reality. Extensive evaluations demonstrate DDP's exceptional resilience. Notably, DDP achieves a 73.8% OOD success rate on MetaWorld (vs. 23.9% without predictive imagination) and an 83.3% success rate under severe real-world spatial shifts (vs. 3.3% without predictive imagination). Furthermore, as a stress test, DDP maintains a 76.7% real-world success rate even when relying entirely on open-loop imagination post-initialization.
ReMem-VLA: Empowering Vision-Language-Action Model with Memory via Dual-Level Recurrent Queries
Mar 13, 2026Vision-language-action (VLA) models for closed-loop robot control are typically cast under the Markov assumption, making them prone to errors on tasks requiring historical context. To incorporate memory, existing VLAs either retrieve from a memory bank, which can be misled by distractors, or extend the frame window, whose fixed horizon still limits long-term retention. In this paper, we introduce ReMem-VLA, a Recurrent Memory VLA model equipped with two sets of learnable queries: frame-level recurrent memory queries for propagating information across consecutive frames to support short-term memory, and chunk-level recurrent memory queries for carrying context across temporal chunks for long-term memory. These queries are trained end-to-end to aggregate and maintain relevant context over time, implicitly guiding the model's decisions without additional training or inference cost. Furthermore, to enhance visual memory, we introduce Past Observation Prediction as an auxiliary training objective. Through extensive memory-centric simulation and real-world robot experiments, we demonstrate that ReMem-VLA exhibits strong memory capabilities across multiple dimensions, including spatial, sequential, episodic, temporal, and visual memory. ReMem-VLA significantly outperforms memory-free VLA baselines $π$0.5 and OpenVLA-OFT and surpasses MemoryVLA on memory-dependent tasks by a large margin.
From Flow to One Step: Real-Time Multi-Modal Trajectory Policies via Implicit Maximum Likelihood Estimation-based Distribution Distillation
Mar 10, 2026Generative policies based on diffusion and flow matching achieve strong performance in robotic manipulation by modeling multi-modal human demonstrations. However, their reliance on iterative Ordinary Differential Equation (ODE) integration introduces substantial latency, limiting high-frequency closed-loop control. Recent single-step acceleration methods alleviate this overhead but often exhibit distributional collapse, producing averaged trajectories that fail to execute coherent manipulation strategies. We propose a framework that distills a Conditional Flow Matching (CFM) expert into a fast single-step student via Implicit Maximum Likelihood Estimation (IMLE). A bi-directional Chamfer distance provides a set-level objective that promotes both mode coverage and fidelity, enabling preservation of the teacher multi-modal action distribution in a single forward pass. A unified perception encoder further integrates multi-view RGB, depth, point clouds, and proprioception into a geometry-aware representation. The resulting high-frequency control supports real-time receding-horizon re-planning and improved robustness under dynamic disturbances.
MOSAIC: Bridging the Sim-to-Real Gap in Generalist Humanoid Motion Tracking and Teleoperation with Rapid Residual Adaptation
Feb 09, 2026Generalist humanoid motion trackers have recently achieved strong simulation metrics by scaling data and training, yet often remain brittle on hardware during sustained teleoperation due to interface- and dynamics-induced errors. We present MOSAIC, an open-source, full-stack system for humanoid motion tracking and whole-body teleoperation across multiple interfaces. MOSAIC first learns a teleoperation-oriented general motion tracker via RL on a multi-source motion bank with adaptive resampling and rewards that emphasize world-frame motion consistency, which is critical for mobile teleoperation. To bridge the sim-to-real interface gap without sacrificing generality, MOSAIC then performs rapid residual adaptation: an interface-specific policy is trained using minimal interface-specific data, and then distilled into the general tracker through an additive residual module, outperforming naive fine-tuning or continual learning. We validate MOSAIC with systematic ablations, out-of-distribution benchmarking, and real-robot experiments demonstrating robust offline motion replay and online long-horizon teleoperation under realistic latency and noise.
DECO: Decoupled Multimodal Diffusion Transformer for Bimanual Dexterous Manipulation with a Plugin Tactile Adapter
Feb 05, 2026Overview of the Proposed DECO Framework.} DECO is a DiT-based policy that decouples multimodal conditioning. Image and action tokens interact via joint self attention, while proprioceptive states and optional conditions are injected through adaptive layer normalization. Tactile signals are injected via cross attention, while a lightweight LoRA-based adapter is used to efficiently fine-tune the pretrained policy. DECO is also accompanied by DECO-50, a bimanual dexterous manipulation dataset with tactile sensing, consisting of 4 scenarios and 28 sub-tasks, covering more than 50 hours of data, approximately 5 million frames, and 8,000 successful trajectories.
TacUMI: A Multi-Modal Universal Manipulation Interface for Contact-Rich Tasks
Jan 21, 2026Task decomposition is critical for understanding and learning complex long-horizon manipulation tasks. Especially for tasks involving rich physical interactions, relying solely on visual observations and robot proprioceptive information often fails to reveal the underlying event transitions. This raises the requirement for efficient collection of high-quality multi-modal data as well as robust segmentation method to decompose demonstrations into meaningful modules. Building on the idea of the handheld demonstration device Universal Manipulation Interface (UMI), we introduce TacUMI, a multi-modal data collection system that integrates additionally ViTac sensors, force-torque sensor, and pose tracker into a compact, robot-compatible gripper design, which enables synchronized acquisition of all these modalities during human demonstrations. We then propose a multi-modal segmentation framework that leverages temporal models to detect semantically meaningful event boundaries in sequential manipulations. Evaluation on a challenging cable mounting task shows more than 90 percent segmentation accuracy and highlights a remarkable improvement with more modalities, which validates that TacUMI establishes a practical foundation for both scalable collection and segmentation of multi-modal demonstrations in contact-rich tasks.
M4Diffuser: Multi-View Diffusion Policy with Manipulability-Aware Control for Robust Mobile Manipulation
Sep 18, 2025Mobile manipulation requires the coordinated control of a mobile base and a robotic arm while simultaneously perceiving both global scene context and fine-grained object details. Existing single-view approaches often fail in unstructured environments due to limited fields of view, exploration, and generalization abilities. Moreover, classical controllers, although stable, struggle with efficiency and manipulability near singularities. To address these challenges, we propose M4Diffuser, a hybrid framework that integrates a Multi-View Diffusion Policy with a novel Reduced and Manipulability-aware QP (ReM-QP) controller for mobile manipulation. The diffusion policy leverages proprioceptive states and complementary camera perspectives with both close-range object details and global scene context to generate task-relevant end-effector goals in the world frame. These high-level goals are then executed by the ReM-QP controller, which eliminates slack variables for computational efficiency and incorporates manipulability-aware preferences for robustness near singularities. Comprehensive experiments in simulation and real-world environments show that M4Diffuser achieves 7 to 56 percent higher success rates and reduces collisions by 3 to 31 percent over baselines. Our approach demonstrates robust performance for smooth whole-body coordination, and strong generalization to unseen tasks, paving the way for reliable mobile manipulation in unstructured environments. Details of the demo and supplemental material are available on our project website https://sites.google.com/view/m4diffuser.
Estimated Informed Anytime Search for Sampling-Based Planning via Adaptive Sampler
Aug 29, 2025Path planning in robotics often involves solving continuously valued, high-dimensional problems. Popular informed approaches include graph-based searches, such as A*, and sampling-based methods, such as Informed RRT*, which utilize informed set and anytime strategies to expedite path optimization incrementally. Informed sampling-based planners define informed sets as subsets of the problem domain based on the current best solution cost. However, when no solution is found, these planners re-sample and explore the entire configuration space, which is time-consuming and computationally expensive. This article introduces Multi-Informed Trees (MIT*), a novel planner that constructs estimated informed sets based on prior admissible solution costs before finding the initial solution, thereby accelerating the initial convergence rate. Moreover, MIT* employs an adaptive sampler that dynamically adjusts the sampling strategy based on the exploration process. Furthermore, MIT* utilizes length-related adaptive sparse collision checks to guide lazy reverse search. These features enhance path cost efficiency and computation times while ensuring high success rates in confined scenarios. Through a series of simulations and real-world experiments, it is confirmed that MIT* outperforms existing single-query, sampling-based planners for problems in R^4 to R^16 and has been successfully applied to real-world robot manipulation tasks. A video showcasing our experimental results is available at: https://youtu.be/30RsBIdexTU
Language-Enhanced Mobile Manipulation for Efficient Object Search in Indoor Environments
Aug 28, 2025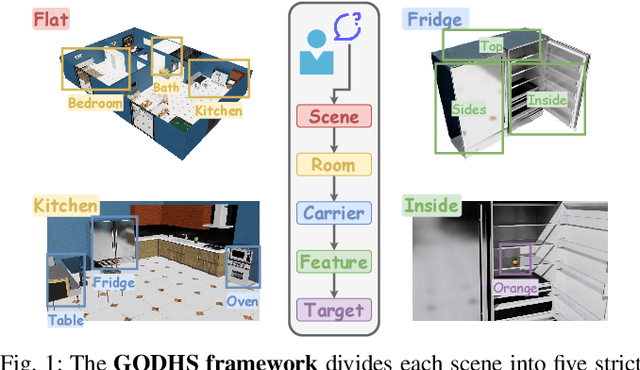
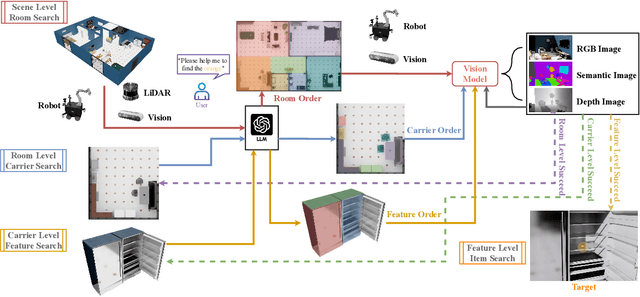
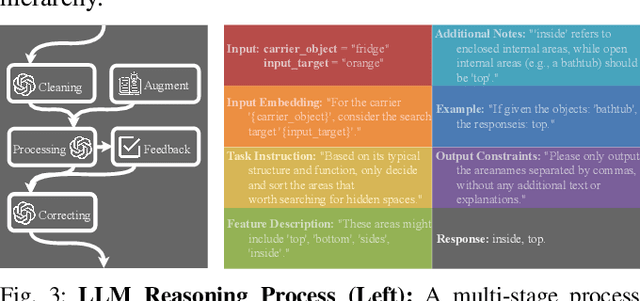

Enabling robots to efficiently search for and identify objects in complex, unstructured environments is critical for diverse applications ranging from household assistance to industrial automation. However, traditional scene representations typically capture only static semantics and lack interpretable contextual reasoning, limiting their ability to guide object search in completely unfamiliar settings. To address this challenge, we propose a language-enhanced hierarchical navigation framework that tightly integrates semantic perception and spatial reasoning. Our method, Goal-Oriented Dynamically Heuristic-Guided Hierarchical Search (GODHS), leverages large language models (LLMs) to infer scene semantics and guide the search process through a multi-level decision hierarchy. Reliability in reasoning is achieved through the use of structured prompts and logical constraints applied at each stage of the hierarchy. For the specific challenges of mobile manipulation, we introduce a heuristic-based motion planner that combines polar angle sorting with distance prioritization to efficiently generate exploration paths. Comprehensive evaluations in Isaac Sim demonstrate the feasibility of our framework, showing that GODHS can locate target objects with higher search efficiency compared to conventional, non-semantic search strategies. Website and Video are available at: https://drapandiger.github.io/GODHS
Genetic Informed Trees (GIT*): Path Planning via Reinforced Genetic Programming Heuristics
Aug 28, 2025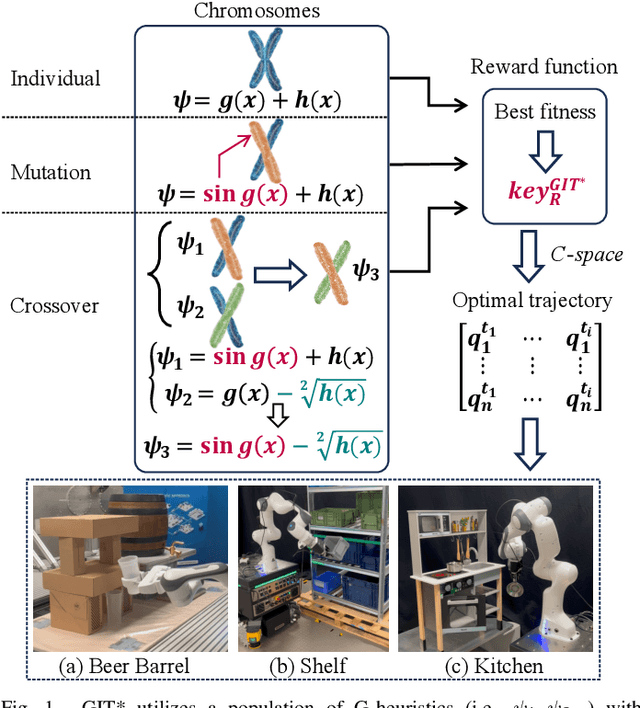
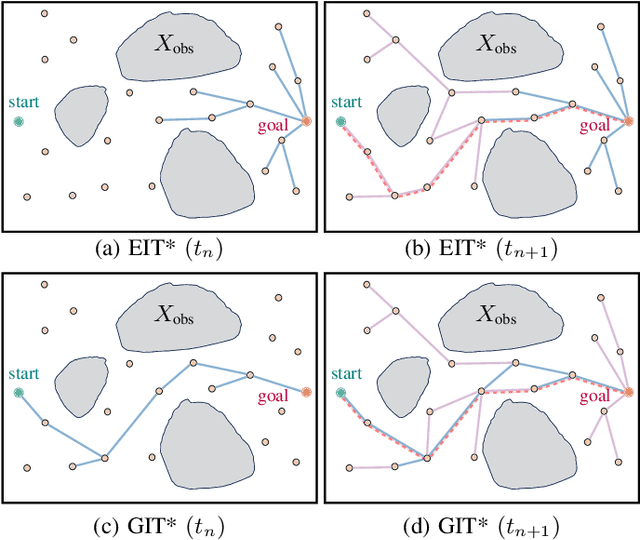
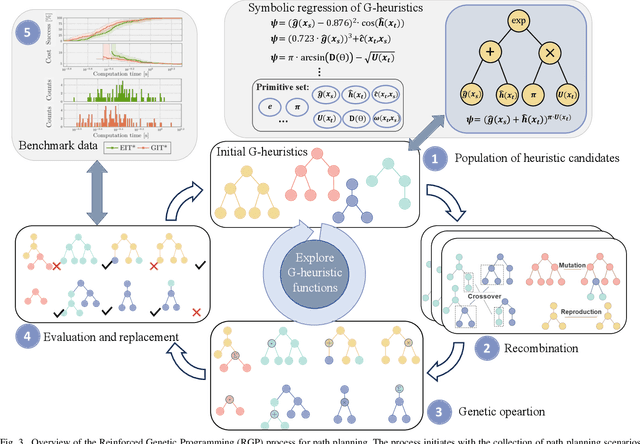
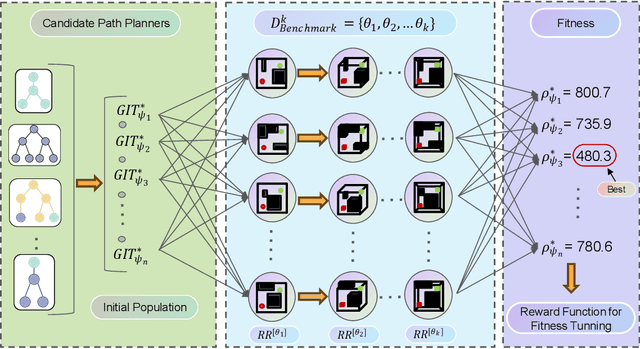
Optimal path planning involves finding a feasible state sequence between a start and a goal that optimizes an objective. This process relies on heuristic functions to guide the search direction. While a robust function can improve search efficiency and solution quality, current methods often overlook available environmental data and simplify the function structure due to the complexity of information relationships. This study introduces Genetic Informed Trees (GIT*), which improves upon Effort Informed Trees (EIT*) by integrating a wider array of environmental data, such as repulsive forces from obstacles and the dynamic importance of vertices, to refine heuristic functions for better guidance. Furthermore, we integrated reinforced genetic programming (RGP), which combines genetic programming with reward system feedback to mutate genotype-generative heuristic functions for GIT*. RGP leverages a multitude of data types, thereby improving computational efficiency and solution quality within a set timeframe. Comparative analyses demonstrate that GIT* surpasses existing single-query, sampling-based planners in problems ranging from R^4 to R^16 and was tested on a real-world mobile manipulation task. A video showcasing our experimental results is available at https://youtu.be/URjXbc_BiYg