 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGassidy: Gaussian Splatting SLAM in Dynamic Environments
Nov 23, 20243D Gaussian Splatting (3DGS) allows flexible adjustments to scene representation, enabling continuous optimization of scene quality during dense visual simultaneous localization and mapping (SLAM) in static environments. However, 3DGS faces challenges in handling environmental disturbances from dynamic objects with irregular movement, leading to degradation in both camera tracking accuracy and map reconstruction quality. To address this challenge, we develop an RGB-D dense SLAM which is called Gaussian Splatting SLAM in Dynamic Environments (Gassidy). This approach calculates Gaussians to generate rendering loss flows for each environmental component based on a designed photometric-geometric loss function. To distinguish and filter environmental disturbances, we iteratively analyze rendering loss flows to detect features characterized by changes in loss values between dynamic objects and static components. This process ensures a clean environment for accurate scene reconstruction. Compared to state-of-the-art SLAM methods, experimental results on open datasets show that Gassidy improves camera tracking precision by up to 97.9% and enhances map quality by up to 6%.
Legal Evalutions and Challenges of Large Language Models
Nov 15, 2024



In this paper, we review legal testing methods based on Large Language Models (LLMs), using the OPENAI o1 model as a case study to evaluate the performance of large models in applying legal provisions. We compare current state-of-the-art LLMs, including open-source, closed-source, and legal-specific models trained specifically for the legal domain. Systematic tests are conducted on English and Chinese legal cases, and the results are analyzed in depth. Through systematic testing of legal cases from common law systems and China, this paper explores the strengths and weaknesses of LLMs in understanding and applying legal texts, reasoning through legal issues, and predicting judgments. The experimental results highlight both the potential and limitations of LLMs in legal applications, particularly in terms of challenges related to the interpretation of legal language and the accuracy of legal reasoning. Finally, the paper provides a comprehensive analysis of the advantages and disadvantages of various types of models, offering valuable insights and references for the future application of AI in the legal field.
Robust Matrix Regression
Nov 15, 2016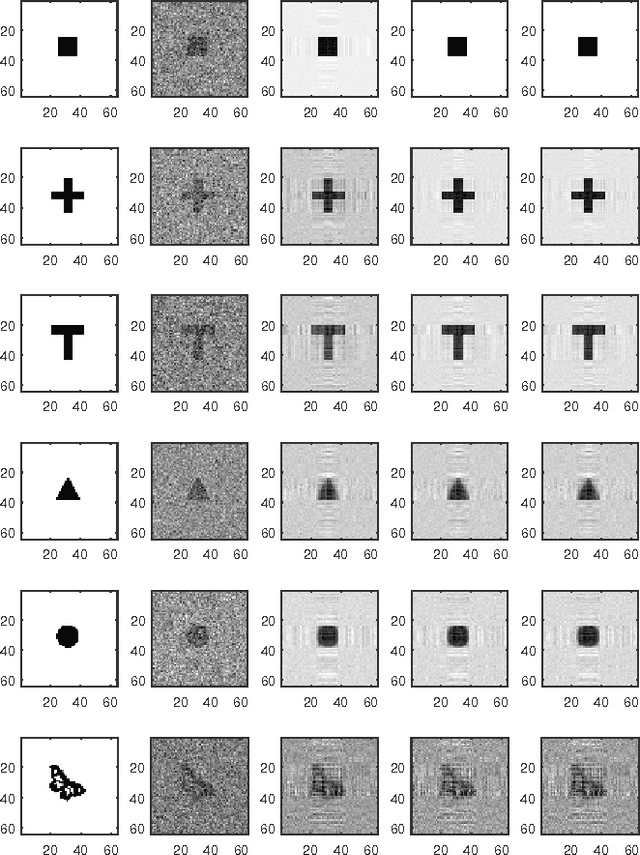
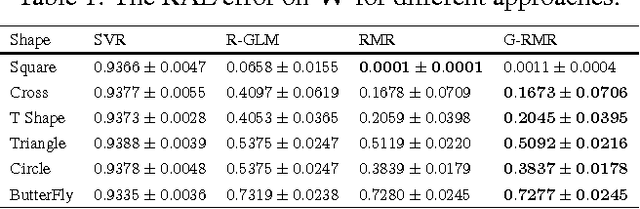
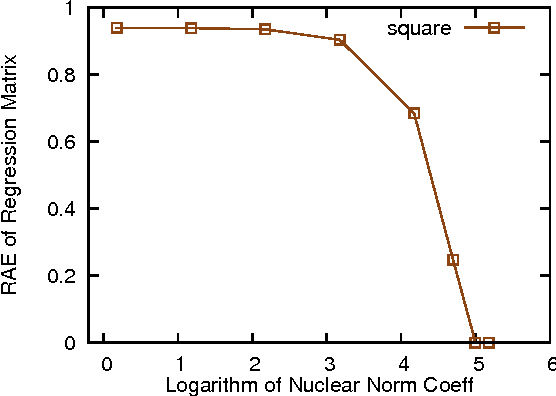
Modern technologies are producing datasets with complex intrinsic structures, and they can be naturally represented as matrices instead of vectors. To preserve the latent data structures during processing, modern regression approaches incorporate the low-rank property to the model and achieve satisfactory performance for certain applications. These approaches all assume that both predictors and labels for each pair of data within the training set are accurate. However, in real-world applications, it is common to see the training data contaminated by noises, which can affect the robustness of these matrix regression methods. In this paper, we address this issue by introducing a novel robust matrix regression method. We also derive efficient proximal algorithms for model training. To evaluate the performance of our methods, we apply it to real world applications with comparative studies. Our method achieves the state-of-the-art performance, which shows the effectiveness and the practical value of our method.