 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInpaintDPO: Mitigating Spatial Relationship Hallucinations in Foreground-conditioned Inpainting via Diverse Preference Optimization
Dec 16, 2025



Foreground-conditioned inpainting, which aims at generating a harmonious background for a given foreground subject based on the text prompt, is an important subfield in controllable image generation. A common challenge in current methods, however, is the occurrence of Spatial Relationship Hallucinations between the foreground subject and the generated background, including inappropriate scale, positional relationships, and viewpoints. Critically, the subjective nature of spatial rationality makes it challenging to quantify, hindering the use of traditional reward-based RLHF methods. To address this issue, we propose InpaintDPO, the first Direct Preference Optimization (DPO) based framework dedicated to spatial rationality in foreground-conditioned inpainting, ensuring plausible spatial relationships between foreground and background elements. To resolve the gradient conflicts in standard DPO caused by identical foreground in win-lose pairs, we propose MaskDPO, which confines preference optimization exclusively to the background to enhance background spatial relationships, while retaining the inpainting loss in the foreground region for robust foreground preservation. To enhance coherence at the foreground-background boundary, we propose Conditional Asymmetric Preference Optimization, which samples pairs with differentiated cropping operations and applies global preference optimization to promote contextual awareness and enhance boundary coherence. Finally, based on the observation that winning samples share a commonality in plausible spatial relationships, we propose Shared Commonality Preference Optimization to enhance the model's understanding of spatial commonality across high-quality winning samples, further promoting shared spatial rationality.
Multi-Agent VLMs Guided Self-Training with PNU Loss for Low-Resource Offensive Content Detection
Nov 14, 2025



Accurate detection of offensive content on social media demands high-quality labeled data; however, such data is often scarce due to the low prevalence of offensive instances and the high cost of manual annotation. To address this low-resource challenge, we propose a self-training framework that leverages abundant unlabeled data through collaborative pseudo-labeling. Starting with a lightweight classifier trained on limited labeled data, our method iteratively assigns pseudo-labels to unlabeled instances with the support of Multi-Agent Vision-Language Models (MA-VLMs). Un-labeled data on which the classifier and MA-VLMs agree are designated as the Agreed-Unknown set, while conflicting samples form the Disagreed-Unknown set. To enhance label reliability, MA-VLMs simulate dual perspectives, moderator and user, capturing both regulatory and subjective viewpoints. The classifier is optimized using a novel Positive-Negative-Unlabeled (PNU) loss, which jointly exploits labeled, Agreed-Unknown, and Disagreed-Unknown data while mitigating pseudo-label noise. Experiments on benchmark datasets demonstrate that our framework substantially outperforms baselines under limited supervision and approaches the performance of large-scale models
ShoulderShot: Generating Over-the-Shoulder Dialogue Videos
Aug 11, 2025



Over-the-shoulder dialogue videos are essential in films, short dramas, and advertisements, providing visual variety and enhancing viewers' emotional connection. Despite their importance, such dialogue scenes remain largely underexplored in video generation research. The main challenges include maintaining character consistency across different shots, creating a sense of spatial continuity, and generating long, multi-turn dialogues within limited computational budgets. Here, we present ShoulderShot, a framework that combines dual-shot generation with looping video, enabling extended dialogues while preserving character consistency. Our results demonstrate capabilities that surpass existing methods in terms of shot-reverse-shot layout, spatial continuity, and flexibility in dialogue length, thereby opening up new possibilities for practical dialogue video generation. Videos and comparisons are available at https://shouldershot.github.io.
Survey of HPC in US Research Institutions
Jun 23, 2025

The rapid growth of AI, data-intensive science, and digital twin technologies has driven an unprecedented demand for high-performance computing (HPC) across the research ecosystem. While national laboratories and industrial hyperscalers have invested heavily in exascale and GPU-centric architectures, university-operated HPC systems remain comparatively under-resourced. This survey presents a comprehensive assessment of the HPC landscape across U.S. universities, benchmarking their capabilities against Department of Energy (DOE) leadership-class systems and industrial AI infrastructures. We examine over 50 premier research institutions, analyzing compute capacity, architectural design, governance models, and energy efficiency. Our findings reveal that university clusters, though vital for academic research, exhibit significantly lower growth trajectories (CAGR $\approx$ 18%) than their national ($\approx$ 43%) and industrial ($\approx$ 78%) counterparts. The increasing skew toward GPU-dense AI workloads has widened the capability gap, highlighting the need for federated computing, idle-GPU harvesting, and cost-sharing models. We also identify emerging paradigms, such as decentralized reinforcement learning, as promising opportunities for democratizing AI training within campus environments. Ultimately, this work provides actionable insights for academic leaders, funding agencies, and technology partners to ensure more equitable and sustainable HPC access in support of national research priorities.
Real-time Ad retrieval via LLM-generative Commercial Intention for Sponsored Search Advertising
Apr 02, 2025



The integration of Large Language Models (LLMs) with retrieval systems has shown promising potential in retrieving documents (docs) or advertisements (ads) for a given query. Existing LLM-based retrieval methods generate numeric or content-based DocIDs to retrieve docs/ads. However, the one-to-few mapping between numeric IDs and docs, along with the time-consuming content extraction, leads to semantic inefficiency and limits scalability in large-scale corpora. In this paper, we propose the Real-time Ad REtrieval (RARE) framework, which leverages LLM-generated text called Commercial Intentions (CIs) as an intermediate semantic representation to directly retrieve ads for queries in real-time. These CIs are generated by a customized LLM injected with commercial knowledge, enhancing its domain relevance. Each CI corresponds to multiple ads, yielding a lightweight and scalable set of CIs. RARE has been implemented in a real-world online system, handling daily search volumes in the hundreds of millions. The online implementation has yielded significant benefits: a 5.04% increase in consumption, a 6.37% rise in Gross Merchandise Volume (GMV), a 1.28% enhancement in click-through rate (CTR) and a 5.29% increase in shallow conversions. Extensive offline experiments show RARE's superiority over ten competitive baselines in four major categories.
Fine-Tuning Open-Source Large Language Models to Improve Their Performance on Radiation Oncology Tasks: A Feasibility Study to Investigate Their Potential Clinical Applications in Radiation Oncology
Jan 28, 2025



Background: The radiation oncology clinical practice involves many steps relying on the dynamic interplay of abundant text data. Large language models have displayed remarkable capabilities in processing complex text information. But their direct applications in specific fields like radiation oncology remain underexplored. Purpose: This study aims to investigate whether fine-tuning LLMs with domain knowledge can improve the performance on Task (1) treatment regimen generation, Task (2) treatment modality selection (photon, proton, electron, or brachytherapy), and Task (3) ICD-10 code prediction in radiation oncology. Methods: Data for 15,724 patient cases were extracted. Cases where patients had a single diagnostic record, and a clearly identifiable primary treatment plan were selected for preprocessing and manual annotation to have 7,903 cases of the patient diagnosis, treatment plan, treatment modality, and ICD-10 code. Each case was used to construct a pair consisting of patient diagnostics details and an answer (treatment regimen, treatment modality, or ICD-10 code respectively) for the supervised fine-tuning of these three tasks. Open source LLaMA2-7B and Mistral-7B models were utilized for the fine-tuning with the Low-Rank Approximations method. Accuracy and ROUGE-1 score were reported for the fine-tuned models and original models. Clinical evaluation was performed on Task (1) by radiation oncologists, while precision, recall, and F-1 score were evaluated for Task (2) and (3). One-sided Wilcoxon signed-rank tests were used to statistically analyze the results. Results: Fine-tuned LLMs outperformed original LLMs across all tasks with p-value <= 0.001. Clinical evaluation demonstrated that over 60% of the fine-tuned LLMs-generated treatment regimens were clinically acceptable. Precision, recall, and F1-score showed improved performance of fine-tuned LLMs.
Target-driven Self-Distillation for Partial Observed Trajectories Forecasting
Jan 28, 2025Accurate prediction of future trajectories of traffic agents is essential for ensuring safe autonomous driving. However, partially observed trajectories can significantly degrade the performance of even state-of-the-art models. Previous approaches often rely on knowledge distillation to transfer features from fully observed trajectories to partially observed ones. This involves firstly training a fully observed model and then using a distillation process to create the final model. While effective, they require multi-stage training, making the training process very expensive. Moreover, knowledge distillation can lead to a performance degradation of the model. In this paper, we introduce a Target-driven Self-Distillation method (TSD) for motion forecasting. Our method leverages predicted accurate targets to guide the model in making predictions under partial observation conditions. By employing self-distillation, the model learns from the feature distributions of both fully observed and partially observed trajectories during a single end-to-end training process. This enhances the model's ability to predict motion accurately in both fully observed and partially observed scenarios. We evaluate our method on multiple datasets and state-of-the-art motion forecasting models. Extensive experimental results demonstrate that our approach achieves significant performance improvements in both settings. To facilitate further research, we will release our code and model checkpoints.
Large Language Models for Bioinformatics
Jan 10, 2025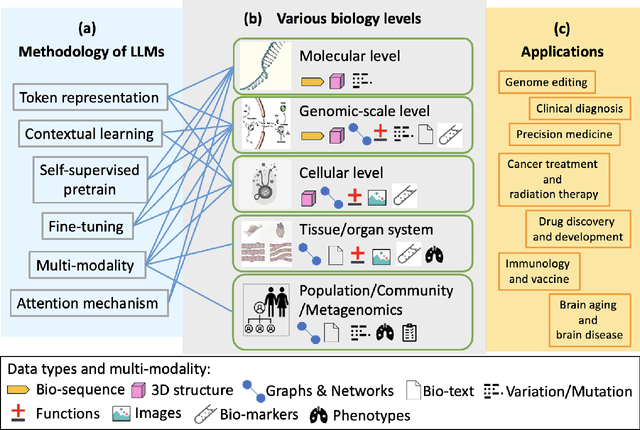
With the rapid advancements in large language model (LLM) technology and the emergence of bioinformatics-specific language models (BioLMs), there is a growing need for a comprehensive analysis of the current landscape, computational characteristics, and diverse applications. This survey aims to address this need by providing a thorough review of BioLMs, focusing on their evolution, classification, and distinguishing features, alongside a detailed examination of training methodologies, datasets, and evaluation frameworks. We explore the wide-ranging applications of BioLMs in critical areas such as disease diagnosis, drug discovery, and vaccine development, highlighting their impact and transformative potential in bioinformatics. We identify key challenges and limitations inherent in BioLMs, including data privacy and security concerns, interpretability issues, biases in training data and model outputs, and domain adaptation complexities. Finally, we highlight emerging trends and future directions, offering valuable insights to guide researchers and clinicians toward advancing BioLMs for increasingly sophisticated biological and clinical applications.
QueEn: A Large Language Model for Quechua-English Translation
Dec 06, 2024

Recent studies show that large language models (LLMs) are powerful tools for working with natural language, bringing advances in many areas of computational linguistics. However, these models face challenges when applied to low-resource languages due to limited training data and difficulty in understanding cultural nuances. In this paper, we propose QueEn, a novel approach for Quechua-English translation that combines Retrieval-Augmented Generation (RAG) with parameter-efficient fine-tuning techniques. Our method leverages external linguistic resources through RAG and uses Low-Rank Adaptation (LoRA) for efficient model adaptation. Experimental results show that our approach substantially exceeds baseline models, with a BLEU score of 17.6 compared to 1.5 for standard GPT models. The integration of RAG with fine-tuning allows our system to address the challenges of low-resource language translation while maintaining computational efficiency. This work contributes to the broader goal of preserving endangered languages through advanced language technologies.
OracleSage: Towards Unified Visual-Linguistic Understanding of Oracle Bone Scripts through Cross-Modal Knowledge Fusion
Nov 26, 2024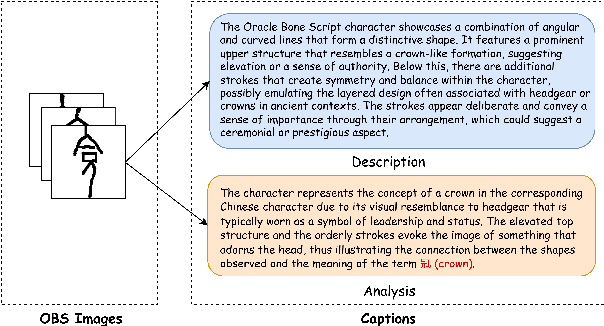

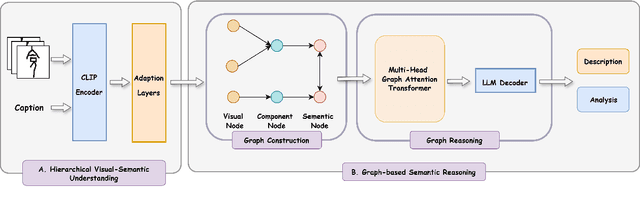
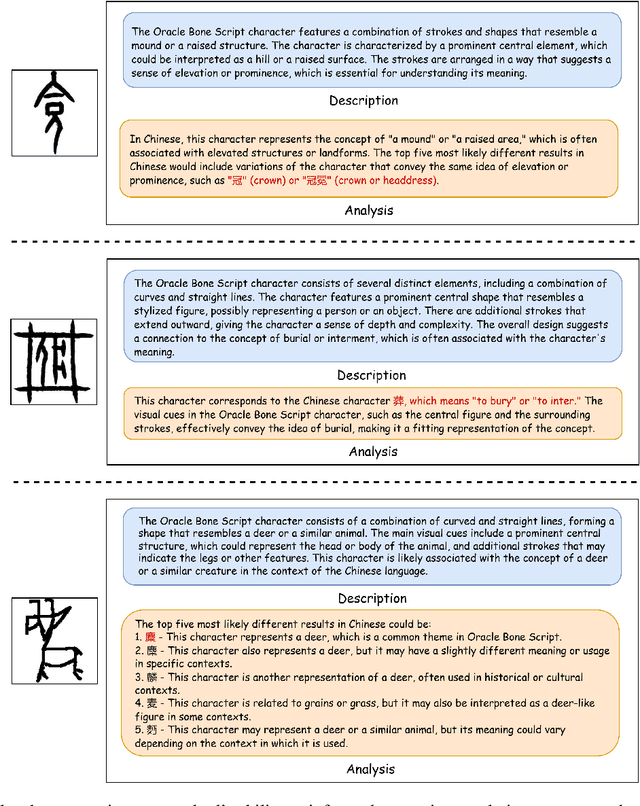
Oracle bone script (OBS), as China's earliest mature writing system, present significant challenges in automatic recognition due to their complex pictographic structures and divergence from modern Chinese characters. We introduce OracleSage, a novel cross-modal framework that integrates hierarchical visual understanding with graph-based semantic reasoning. Specifically, we propose (1) a Hierarchical Visual-Semantic Understanding module that enables multi-granularity feature extraction through progressive fine-tuning of LLaVA's visual backbone, (2) a Graph-based Semantic Reasoning Framework that captures relationships between visual components and semantic concepts through dynamic message passing, and (3) OracleSem, a semantically enriched OBS dataset with comprehensive pictographic and semantic annotations. Experimental results demonstrate that OracleSage significantly outperforms state-of-the-art vision-language models. This research establishes a new paradigm for ancient text interpretation while providing valuable technical support for archaeological studies.