 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHISA: Efficient Hierarchical Indexing for Fine-Grained Sparse Attention
Apr 01, 2026Token-level sparse attention mechanisms, exemplified by DeepSeek Sparse Attention (DSA), achieve fine-grained key selection by scoring every historical key for each query through a lightweight indexer, then computing attention only on the selected subset. While the downstream sparse attention itself scales favorably, the indexer must still scan the entire prefix for every query, introducing an per-layer bottleneck that grows prohibitively with context length. We propose HISA (Hierarchical Indexed Sparse Attention), a plug-and-play replacement for the indexer that rewrites the search path from a flat token scan into a two-stage hierarchical procedure: (1) a block-level coarse filtering stage that scores pooled block representations to discard irrelevant regions, followed by (2) a token-level refinement stage that applies the original indexer exclusively within the retained candidate blocks. HISA preserves the identical token-level top-sparse pattern consumed by the downstream Sparse MLA operator and requires no additional training. On kernel-level benchmarks, HISA achieves up to speedup at 64K context. On Needle-in-a-Haystack and LongBench, we directly replace the indexer in DeepSeek-V3.2 and GLM-5 with our HISA indexer, without any finetuning. HISA closely matches the original DSA in quality, while substantially outperforming block-sparse baselines.
WorldTravel: A Realistic Multimodal Travel-Planning Benchmark with Tightly Coupled Constraints
Feb 09, 2026Real-world autonomous planning requires coordinating tightly coupled constraints where a single decision dictates the feasibility of all subsequent actions. However, existing benchmarks predominantly feature loosely coupled constraints solvable through local greedy decisions and rely on idealized data, failing to capture the complexity of extracting parameters from dynamic web environments. We introduce \textbf{WorldTravel}, a benchmark comprising 150 real-world travel scenarios across 5 cities that demand navigating an average of 15+ interdependent temporal and logical constraints. To evaluate agents in realistic deployments, we develop \textbf{WorldTravel-Webscape}, a multi-modal environment featuring over 2,000 rendered webpages where agents must perceive constraint parameters directly from visual layouts to inform their planning. Our evaluation of 10 frontier models reveals a significant performance collapse: even the state-of-the-art GPT-5.2 achieves only 32.67\% feasibility in text-only settings, which plummets to 19.33\% in multi-modal environments. We identify a critical Perception-Action Gap and a Planning Horizon threshold at approximately 10 constraints where model reasoning consistently fails, suggesting that perception and reasoning remain independent bottlenecks. These findings underscore the need for next-generation agents that unify high-fidelity visual perception with long-horizon reasoning to handle brittle real-world logistics.
IFFair: Influence Function-driven Sample Reweighting for Fair Classification
Dec 08, 2025
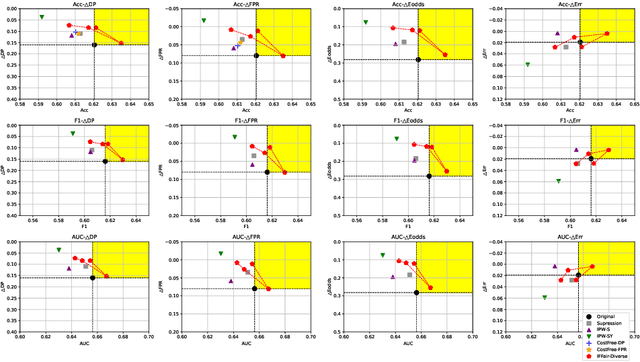
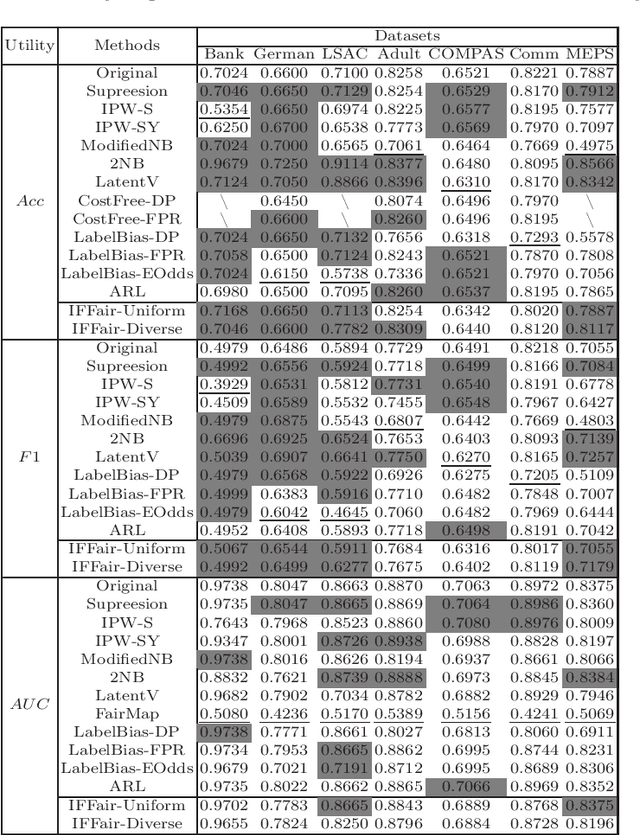
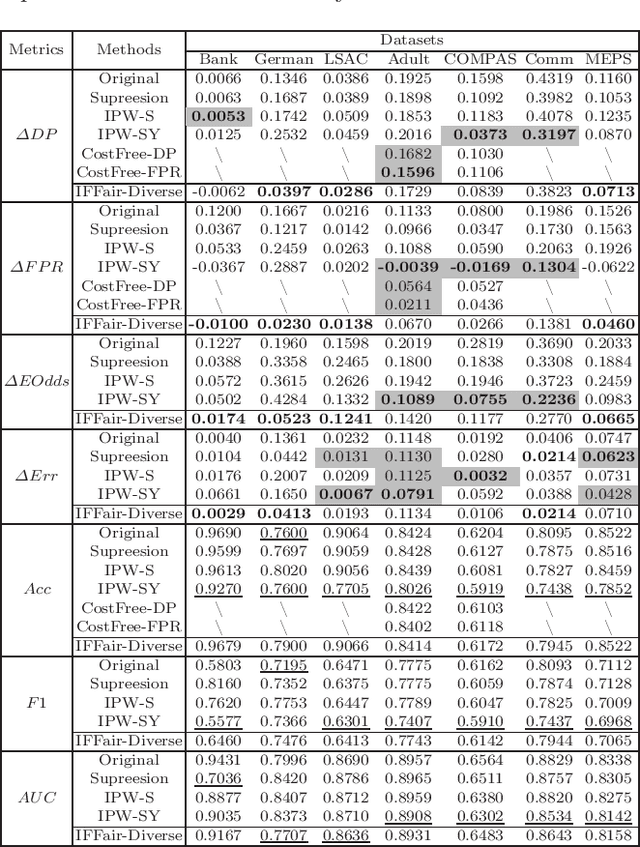
Because machine learning has significantly improved efficiency and convenience in the society, it's increasingly used to assist or replace human decision-making. However, the data-based pattern makes related algorithms learn and even exacerbate potential bias in samples, resulting in discriminatory decisions against certain unprivileged groups, depriving them of the rights to equal treatment, thus damaging the social well-being and hindering the development of related applications. Therefore, we propose a pre-processing method IFFair based on the influence function. Compared with other fairness optimization approaches, IFFair only uses the influence disparity of training samples on different groups as a guidance to dynamically adjust the sample weights during training without modifying the network structure, data features and decision boundaries. To evaluate the validity of IFFair, we conduct experiments on multiple real-world datasets and metrics. The experimental results show that our approach mitigates bias of multiple accepted metrics in the classification setting, including demographic parity, equalized odds, equality of opportunity and error rate parity without conflicts. It also demonstrates that IFFair achieves better trade-off between multiple utility and fairness metrics compared with previous pre-processing methods.
R3GS: Gaussian Splatting for Robust Reconstruction and Relocalization in Unconstrained Image Collections
May 21, 2025



We propose R3GS, a robust reconstruction and relocalization framework tailored for unconstrained datasets. Our method uses a hybrid representation during training. Each anchor combines a global feature from a convolutional neural network (CNN) with a local feature encoded by the multiresolution hash grids [2]. Subsequently, several shallow multi-layer perceptrons (MLPs) predict the attributes of each Gaussians, including color, opacity, and covariance. To mitigate the adverse effects of transient objects on the reconstruction process, we ffne-tune a lightweight human detection network. Once ffne-tuned, this network generates a visibility map that efffciently generalizes to other transient objects (such as posters, banners, and cars) with minimal need for further adaptation. Additionally, to address the challenges posed by sky regions in outdoor scenes, we propose an effective sky-handling technique that incorporates a depth prior as a constraint. This allows the inffnitely distant sky to be represented on the surface of a large-radius sky sphere, signiffcantly reducing ffoaters caused by errors in sky reconstruction. Furthermore, we introduce a novel relocalization method that remains robust to changes in lighting conditions while estimating the camera pose of a given image within the reconstructed 3DGS scene. As a result, R3GS significantly enhances rendering ffdelity, improves both training and rendering efffciency, and reduces storage requirements. Our method achieves state-of-the-art performance compared to baseline methods on in-the-wild datasets. The code will be made open-source following the acceptance of the paper.
* 7 pages, 4 figures
Real-time Ad retrieval via LLM-generative Commercial Intention for Sponsored Search Advertising
Apr 02, 2025



The integration of Large Language Models (LLMs) with retrieval systems has shown promising potential in retrieving documents (docs) or advertisements (ads) for a given query. Existing LLM-based retrieval methods generate numeric or content-based DocIDs to retrieve docs/ads. However, the one-to-few mapping between numeric IDs and docs, along with the time-consuming content extraction, leads to semantic inefficiency and limits scalability in large-scale corpora. In this paper, we propose the Real-time Ad REtrieval (RARE) framework, which leverages LLM-generated text called Commercial Intentions (CIs) as an intermediate semantic representation to directly retrieve ads for queries in real-time. These CIs are generated by a customized LLM injected with commercial knowledge, enhancing its domain relevance. Each CI corresponds to multiple ads, yielding a lightweight and scalable set of CIs. RARE has been implemented in a real-world online system, handling daily search volumes in the hundreds of millions. The online implementation has yielded significant benefits: a 5.04% increase in consumption, a 6.37% rise in Gross Merchandise Volume (GMV), a 1.28% enhancement in click-through rate (CTR) and a 5.29% increase in shallow conversions. Extensive offline experiments show RARE's superiority over ten competitive baselines in four major categories.
MAFT: Efficient Model-Agnostic Fairness Testing for Deep Neural Networks via Zero-Order Gradient Search
Dec 28, 2024



Deep neural networks (DNNs) have shown powerful performance in various applications and are increasingly being used in decision-making systems. However, concerns about fairness in DNNs always persist. Some efficient white-box fairness testing methods about individual fairness have been proposed. Nevertheless, the development of black-box methods has stagnated, and the performance of existing methods is far behind that of white-box methods. In this paper, we propose a novel black-box individual fairness testing method called Model-Agnostic Fairness Testing (MAFT). By leveraging MAFT, practitioners can effectively identify and address discrimination in DL models, regardless of the specific algorithm or architecture employed. Our approach adopts lightweight procedures such as gradient estimation and attribute perturbation rather than non-trivial procedures like symbol execution, rendering it significantly more scalable and applicable than existing methods. We demonstrate that MAFT achieves the same effectiveness as state-of-the-art white-box methods whilst improving the applicability to large-scale networks. Compared to existing black-box approaches, our approach demonstrates distinguished performance in discovering fairness violations w.r.t effectiveness (approximately 14.69 times) and efficiency (approximately 32.58 times).
PiSSA: Principal Singular Values and Singular Vectors Adaptation of Large Language Models
Apr 14, 2024As the parameters of LLMs expand, the computational cost of fine-tuning the entire model becomes prohibitive. To address this challenge, we introduce a PEFT method, Principal Singular values and Singular vectors Adaptation (PiSSA), which optimizes a significantly reduced parameter space while achieving or surpassing the performance of full-parameter fine-tuning. PiSSA is inspired by Intrinsic SAID, which suggests that pre-trained, over-parametrized models inhabit a space of low intrinsic dimension. Consequently, PiSSA represents a matrix W within the model by the product of two trainable matrices A and B, plus a residual matrix $W^{res}$ for error correction. SVD is employed to factorize W, and the principal singular values and vectors of W are utilized to initialize A and B. The residual singular values and vectors initialize the residual matrix $W^{res}$, which keeps frozen during fine-tuning. Notably, PiSSA shares the same architecture with LoRA. However, LoRA approximates Delta W through the product of two matrices, A, initialized with Gaussian noise, and B, initialized with zeros, while PiSSA initializes A and B with principal singular values and vectors of the original matrix W. PiSSA can better approximate the outcomes of full-parameter fine-tuning at the beginning by changing the essential parts while freezing the "noisy" parts. In comparison, LoRA freezes the original matrix and updates the "noise". This distinction enables PiSSA to convergence much faster than LoRA and also achieve better performance in the end. Due to the same architecture, PiSSA inherits many of LoRA's advantages, such as parameter efficiency and compatibility with quantization. Leveraging a fast SVD method, the initialization of PiSSA takes only a few seconds, inducing negligible cost of switching LoRA to PiSSA.
CoSSegGaussians: Compact and Swift Scene Segmenting 3D Gaussians with Dual Feature Fusion
Jan 30, 2024We propose Compact and Swift Segmenting 3D Gaussians(CoSSegGaussians), a method for compact 3D-consistent scene segmentation at fast rendering speed with only RGB images input. Previous NeRF-based segmentation methods have relied on time-consuming neural scene optimization. While recent 3D Gaussian Splatting has notably improved speed, existing Gaussian-based segmentation methods struggle to produce compact masks, especially in zero-shot segmentation. This issue probably stems from their straightforward assignment of learnable parameters to each Gaussian, resulting in a lack of robustness against cross-view inconsistent 2D machine-generated labels. Our method aims to address this problem by employing Dual Feature Fusion Network as Gaussians' segmentation field. Specifically, we first optimize 3D Gaussians under RGB supervision. After Gaussian Locating, DINO features extracted from images are applied through explicit unprojection, which are further incorporated with spatial features from the efficient point cloud processing network. Feature aggregation is utilized to fuse them in a global-to-local strategy for compact segmentation features. Experimental results show that our model outperforms baselines on both semantic and panoptic zero-shot segmentation task, meanwhile consumes less than 10% inference time compared to NeRF-based methods. Code and more results will be available at https://David-Dou.github.io/CoSSegGaussians
Seeing through the Mask: Multi-task Generative Mask Decoupling Face Recognition
Nov 20, 2023

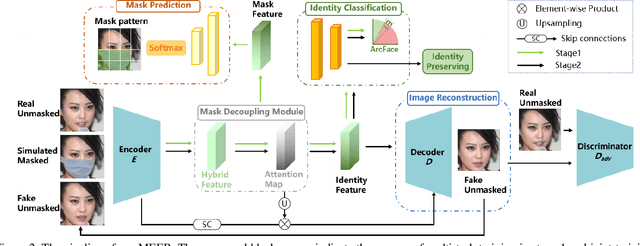

The outbreak of COVID-19 pandemic make people wear masks more frequently than ever. Current general face recognition system suffers from serious performance degradation,when encountering occluded scenes. The potential reason is that face features are corrupted by occlusions on key facial regions. To tackle this problem, previous works either extract identity-related embeddings on feature level by additional mask prediction, or restore the occluded facial part by generative models. However, the former lacks visual results for model interpretation, while the latter suffers from artifacts which may affect downstream recognition. Therefore, this paper proposes a Multi-task gEnerative mask dEcoupling face Recognition (MEER) network to jointly handle these two tasks, which can learn occlusionirrelevant and identity-related representation while achieving unmasked face synthesis. We first present a novel mask decoupling module to disentangle mask and identity information, which makes the network obtain purer identity features from visible facial components. Then, an unmasked face is restored by a joint-training strategy, which will be further used to refine the recognition network with an id-preserving loss. Experiments on masked face recognition under realistic and synthetic occlusions benchmarks demonstrate that the MEER can outperform the state-ofthe-art methods.
Towards Privacy-Supporting Fall Detection via Deep Unsupervised RGB2Depth Adaptation
Aug 23, 2023
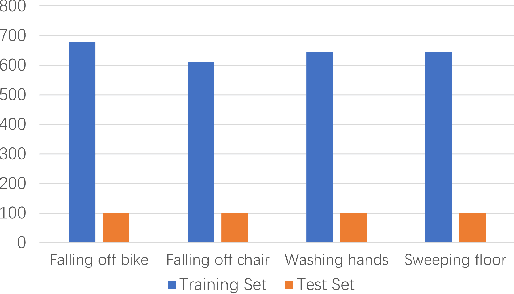
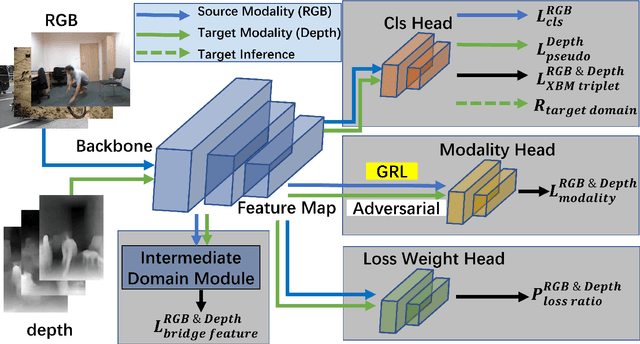
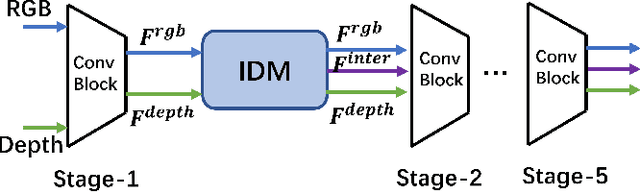
Fall detection is a vital task in health monitoring, as it allows the system to trigger an alert and therefore enabling faster interventions when a person experiences a fall. Although most previous approaches rely on standard RGB video data, such detailed appearance-aware monitoring poses significant privacy concerns. Depth sensors, on the other hand, are better at preserving privacy as they merely capture the distance of objects from the sensor or camera, omitting color and texture information. In this paper, we introduce a privacy-supporting solution that makes the RGB-trained model applicable in depth domain and utilizes depth data at test time for fall detection. To achieve cross-modal fall detection, we present an unsupervised RGB to Depth (RGB2Depth) cross-modal domain adaptation approach that leverages labelled RGB data and unlabelled depth data during training. Our proposed pipeline incorporates an intermediate domain module for feature bridging, modality adversarial loss for modality discrimination, classification loss for pseudo-labeled depth data and labeled source data, triplet loss that considers both source and target domains, and a novel adaptive loss weight adjustment method for improved coordination among various losses. Our approach achieves state-of-the-art results in the unsupervised RGB2Depth domain adaptation task for fall detection. Code is available at https://github.com/1015206533/privacy_supporting_fall_detection.