 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCogPortrait: Fine-Grained Eye-Region Control in Portrait Animation via Hierarchical Agent Planning
May 27, 2026Portrait animation methods have achieved substantial visual quality and lip synchronization, but fine-grained manipulation of the eye region still faces a trade-off between input granularity and motion accuracy. Existing methods using emotion labels or coarse text prompts are insufficient for describing subtle ocular dynamics, whereas approaches based on Action Units or driving videos provide higher fidelity at the cost of a heavier input burden. These limitations are still restrictive for beyond-emotion states (e.g., thinking) and drowsiness. In light of the above, we propose CogPortrait, a two-stage framework that generates portrait animations from high-level labels. In the first stage, three chain-of-thought Multimodal Large Language Models (MLLMs) agents compile high-level labels into facial keypoints through temporal event planning, prototype retrieval, and composition from a real-behavior library, and semantic-physiological constraint enforcement. In the second stage, a DiT-based video generation backbone synthesizes the final animation conditioned on the keypoints, reference portrait, audio, and text prompt, enhanced by a dynamic classifier-free guidance strategy with eye-region-aware reweighting and KTO-based refinement for boundary cases. We further introduce the EMH benchmark covering diverse emotions and beyond-emotion categories with two AU-level metrics for evaluating fine-grained eye-region and head-motion control. Extensive experiments on HDTF and the EMH benchmark demonstrate that CogPortrait achieves more precise eye-region control than existing methods while maintaining supe- rior visual quality and identity consistency
EverybodyDance: Bipartite Graph-Based Identity Correspondence for Multi-Character Animation
Dec 18, 2025
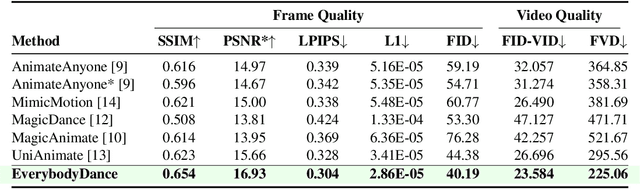

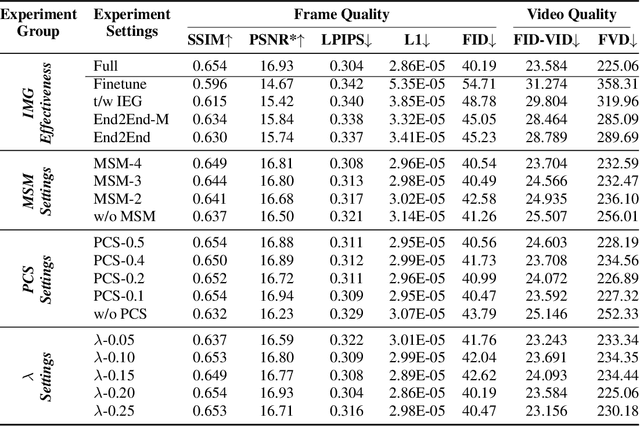
Consistent pose-driven character animation has achieved remarkable progress in single-character scenarios. However, extending these advances to multi-character settings is non-trivial, especially when position swap is involved. Beyond mere scaling, the core challenge lies in enforcing correct Identity Correspondence (IC) between characters in reference and generated frames. To address this, we introduce EverybodyDance, a systematic solution targeting IC correctness in multi-character animation. EverybodyDance is built around the Identity Matching Graph (IMG), which models characters in the generated and reference frames as two node sets in a weighted complete bipartite graph. Edge weights, computed via our proposed Mask-Query Attention (MQA), quantify the affinity between each pair of characters. Our key insight is to formalize IC correctness as a graph structural metric and to optimize it during training. We also propose a series of targeted strategies tailored for multi-character animation, including identity-embedded guidance, a multi-scale matching strategy, and pre-classified sampling, which work synergistically. Finally, to evaluate IC performance, we curate the Identity Correspondence Evaluation benchmark, dedicated to multi-character IC correctness. Extensive experiments demonstrate that EverybodyDance substantially outperforms state-of-the-art baselines in both IC and visual fidelity.
Adams Bashforth Moulton Solver for Inversion and Editing in Rectified Flow
Mar 17, 2025Rectified flow models have achieved remarkable performance in image and video generation tasks. However, existing numerical solvers face a trade-off between fast sampling and high-accuracy solutions, limiting their effectiveness in downstream applications such as reconstruction and editing. To address this challenge, we propose leveraging the Adams-Bashforth-Moulton (ABM) predictor-corrector method to enhance the accuracy of ODE solving in rectified flow models. Specifically, we introduce ABM-Solver, which integrates a multi step predictor corrector approach to reduce local truncation errors and employs Adaptive Step Size Adjustment to improve sampling speed. Furthermore, to effectively preserve non edited regions while facilitating semantic modifications, we introduce a Mask Guided Feature Injection module. We estimate self-similarity to generate a spatial mask that differentiates preserved regions from those available for editing. Extensive experiments on multiple high-resolution image datasets validate that ABM-Solver significantly improves inversion precision and editing quality, outperforming existing solvers without requiring additional training or optimization.
UniCP: A Unified Caching and Pruning Framework for Efficient Video Generation
Feb 06, 2025



Diffusion Transformers (DiT) excel in video generation but encounter significant computational challenges due to the quadratic complexity of attention. Notably, attention differences between adjacent diffusion steps follow a U-shaped pattern. Current methods leverage this property by caching attention blocks, however, they still struggle with sudden error spikes and large discrepancies. To address these issues, we propose UniCP a unified caching and pruning framework for efficient video generation. UniCP optimizes both temporal and spatial dimensions through. Error Aware Dynamic Cache Window (EDCW): Dynamically adjusts cache window sizes for different blocks at various timesteps, adapting to abrupt error changes. PCA based Slicing (PCAS) and Dynamic Weight Shift (DWS): PCAS prunes redundant attention components, and DWS integrates caching and pruning by enabling dynamic switching between pruned and cached outputs. By adjusting cache windows and pruning redundant components, UniCP enhances computational efficiency and maintains video detail fidelity. Experimental results show that UniCP outperforms existing methods in both performance and efficiency.
Tuning-Free Long Video Generation via Global-Local Collaborative Diffusion
Jan 08, 2025



Creating high-fidelity, coherent long videos is a sought-after aspiration. While recent video diffusion models have shown promising potential, they still grapple with spatiotemporal inconsistencies and high computational resource demands. We propose GLC-Diffusion, a tuning-free method for long video generation. It models the long video denoising process by establishing denoising trajectories through Global-Local Collaborative Denoising to ensure overall content consistency and temporal coherence between frames. Additionally, we introduce a Noise Reinitialization strategy which combines local noise shuffling with frequency fusion to improve global content consistency and visual diversity. Further, we propose a Video Motion Consistency Refinement (VMCR) module that computes the gradient of pixel-wise and frequency-wise losses to enhance visual consistency and temporal smoothness. Extensive experiments, including quantitative and qualitative evaluations on videos of varying lengths (\textit{e.g.}, 3\times and 6\times longer), demonstrate that our method effectively integrates with existing video diffusion models, producing coherent, high-fidelity long videos superior to previous approaches.
One-Shot Pose-Driving Face Animation Platform
Jul 12, 2024
The objective of face animation is to generate dynamic and expressive talking head videos from a single reference face, utilizing driving conditions derived from either video or audio inputs. Current approaches often require fine-tuning for specific identities and frequently fail to produce expressive videos due to the limited effectiveness of Wav2Pose modules. To facilitate the generation of one-shot and more consecutive talking head videos, we refine an existing Image2Video model by integrating a Face Locator and Motion Frame mechanism. We subsequently optimize the model using extensive human face video datasets, significantly enhancing its ability to produce high-quality and expressive talking head videos. Additionally, we develop a demo platform using the Gradio framework, which streamlines the process, enabling users to quickly create customized talking head videos.
TrAME: Trajectory-Anchored Multi-View Editing for Text-Guided 3D Gaussian Splatting Manipulation
Jul 02, 2024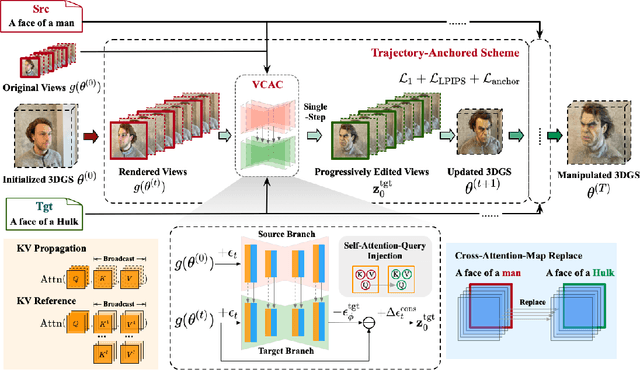



Despite significant strides in the field of 3D scene editing, current methods encounter substantial challenge, particularly in preserving 3D consistency in multi-view editing process. To tackle this challenge, we propose a progressive 3D editing strategy that ensures multi-view consistency via a Trajectory-Anchored Scheme (TAS) with a dual-branch editing mechanism. Specifically, TAS facilitates a tightly coupled iterative process between 2D view editing and 3D updating, preventing error accumulation yielded from text-to-image process. Additionally, we explore the relationship between optimization-based methods and reconstruction-based methods, offering a unified perspective for selecting superior design choice, supporting the rationale behind the designed TAS. We further present a tuning-free View-Consistent Attention Control (VCAC) module that leverages cross-view semantic and geometric reference from the source branch to yield aligned views from the target branch during the editing of 2D views. To validate the effectiveness of our method, we analyze 2D examples to demonstrate the improved consistency with the VCAC module. Further extensive quantitative and qualitative results in text-guided 3D scene editing indicate that our method achieves superior editing quality compared to state-of-the-art methods. We will make the complete codebase publicly available following the conclusion of the double-blind review process.
CoSSegGaussians: Compact and Swift Scene Segmenting 3D Gaussians with Dual Feature Fusion
Jan 30, 2024We propose Compact and Swift Segmenting 3D Gaussians(CoSSegGaussians), a method for compact 3D-consistent scene segmentation at fast rendering speed with only RGB images input. Previous NeRF-based segmentation methods have relied on time-consuming neural scene optimization. While recent 3D Gaussian Splatting has notably improved speed, existing Gaussian-based segmentation methods struggle to produce compact masks, especially in zero-shot segmentation. This issue probably stems from their straightforward assignment of learnable parameters to each Gaussian, resulting in a lack of robustness against cross-view inconsistent 2D machine-generated labels. Our method aims to address this problem by employing Dual Feature Fusion Network as Gaussians' segmentation field. Specifically, we first optimize 3D Gaussians under RGB supervision. After Gaussian Locating, DINO features extracted from images are applied through explicit unprojection, which are further incorporated with spatial features from the efficient point cloud processing network. Feature aggregation is utilized to fuse them in a global-to-local strategy for compact segmentation features. Experimental results show that our model outperforms baselines on both semantic and panoptic zero-shot segmentation task, meanwhile consumes less than 10% inference time compared to NeRF-based methods. Code and more results will be available at https://David-Dou.github.io/CoSSegGaussians