 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Decentralized Composite Optimization via Three-Operator Splitting
Feb 19, 2026The paper studies decentralized optimization over networks, where agents minimize a sum of {\it locally} smooth (strongly) convex losses and plus a nonsmooth convex extended value term. We propose decentralized methods wherein agents {\it adaptively} adjust their stepsize via local backtracking procedures coupled with lightweight min-consensus protocols. Our design stems from a three-operator splitting factorization applied to an equivalent reformulation of the problem. The reformulation is endowed with a new BCV preconditioning metric (Bertsekas-O'Connor-Vandenberghe), which enables efficient decentralized implementation and local stepsize adjustments. We establish robust convergence guarantees. Under mere convexity, the proposed methods converge with a sublinear rate. Under strong convexity of the sum-function, and assuming the nonsmooth component is partly smooth, we further prove linear convergence. Numerical experiments corroborate the theory and highlight the effectiveness of the proposed adaptive stepsize strategy.
Personalized Tree based progressive regression model for watch-time prediction in short video recommendation
May 28, 2025In online video platforms, accurate watch time prediction has become a fundamental and challenging problem in video recommendation. Previous research has revealed that the accuracy of watch time prediction highly depends on both the transformation of watch-time labels and the decomposition of the estimation process. TPM (Tree based Progressive Regression Model) achieves State-of-the-Art performance with a carefully designed and effective decomposition paradigm. TPM discretizes the watch time into several ordinal intervals and organizes them into a binary decision tree, where each node corresponds to a specific interval. At each non-leaf node, a binary classifier is used to determine the specific interval in which the watch time variable most likely falls, based on the prediction outcome at its parent node. The tree structure serves as the core of TPM, as it defines the decomposition of watch time estimation and determines how the ordinal intervals are discretized. However, in TPM, the tree is predefined as a full binary tree, which may be sub-optimal for the following reasons. First, a full binary tree implies an equal partitioning of the watch time space, which may struggle to capture the complexity of real-world watch time distributions. Second, instead of relying on a globally fixed tree structure, we advocate for a personalized, data-driven tree that can be learned in an end-to-end manner. Therefore, we propose PTPM to enable a highly personalized decomposition of watch estimation with better efficacy and efficiency. Moreover, we reveal that TPM is affected by selection bias due to conditional modeling and devise a simple approach to address it. We conduct extensive experiments on both offline datasets and online environments. PTPM has been fully deployed in core traffic scenarios and serves more than 400 million users per day.
Convert Language Model into a Value-based Strategic Planner
May 11, 2025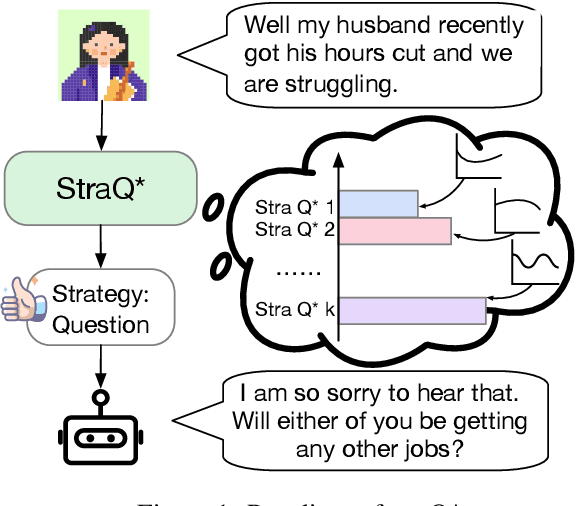
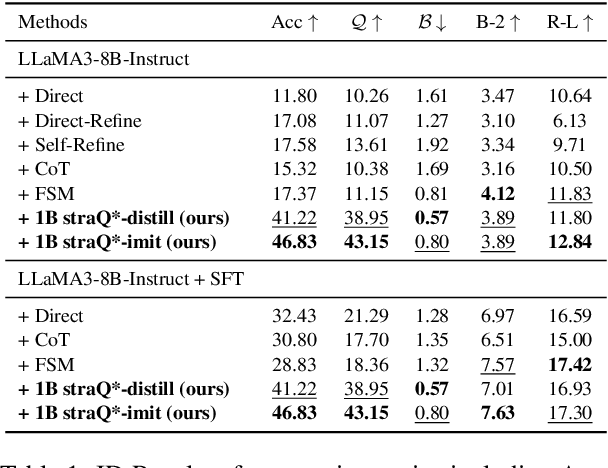
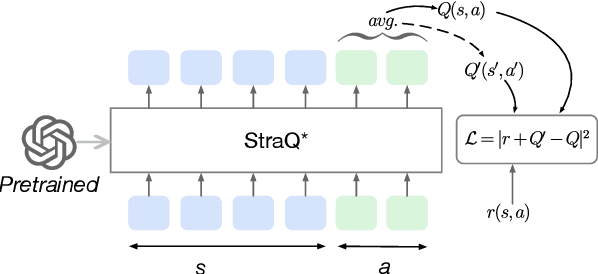
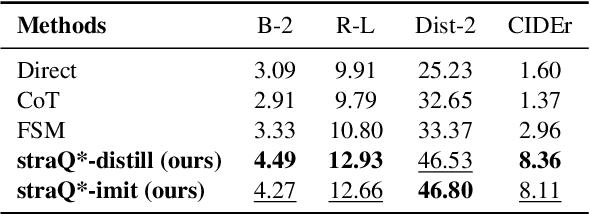
Emotional support conversation (ESC) aims to alleviate the emotional distress of individuals through effective conversations. Although large language models (LLMs) have obtained remarkable progress on ESC, most of these studies might not define the diagram from the state model perspective, therefore providing a suboptimal solution for long-term satisfaction. To address such an issue, we leverage the Q-learning on LLMs, and propose a framework called straQ*. Our framework allows a plug-and-play LLM to bootstrap the planning during ESC, determine the optimal strategy based on long-term returns, and finally guide the LLM to response. Substantial experiments on ESC datasets suggest that straQ* outperforms many baselines, including direct inference, self-refine, chain of thought, finetuning, and finite state machines.
Adams Bashforth Moulton Solver for Inversion and Editing in Rectified Flow
Mar 17, 2025Rectified flow models have achieved remarkable performance in image and video generation tasks. However, existing numerical solvers face a trade-off between fast sampling and high-accuracy solutions, limiting their effectiveness in downstream applications such as reconstruction and editing. To address this challenge, we propose leveraging the Adams-Bashforth-Moulton (ABM) predictor-corrector method to enhance the accuracy of ODE solving in rectified flow models. Specifically, we introduce ABM-Solver, which integrates a multi step predictor corrector approach to reduce local truncation errors and employs Adaptive Step Size Adjustment to improve sampling speed. Furthermore, to effectively preserve non edited regions while facilitating semantic modifications, we introduce a Mask Guided Feature Injection module. We estimate self-similarity to generate a spatial mask that differentiates preserved regions from those available for editing. Extensive experiments on multiple high-resolution image datasets validate that ABM-Solver significantly improves inversion precision and editing quality, outperforming existing solvers without requiring additional training or optimization.
DCatalyst: A Unified Accelerated Framework for Decentralized Optimization
Jan 30, 2025
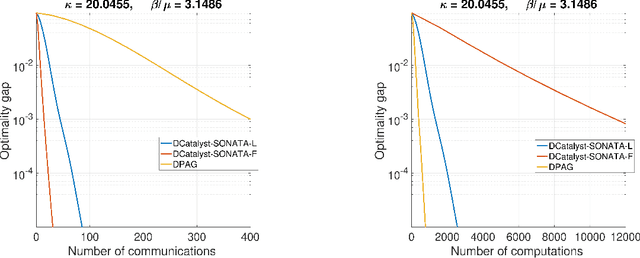

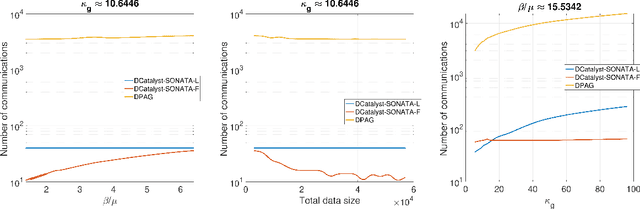
We study decentralized optimization over a network of agents, modeled as graphs, with no central server. The goal is to minimize $f+r$, where $f$ represents a (strongly) convex function averaging the local agents' losses, and $r$ is a convex, extended-value function. We introduce DCatalyst, a unified black-box framework that integrates Nesterov acceleration into decentralized optimization algorithms. %, enhancing their performance. At its core, DCatalyst operates as an \textit{inexact}, \textit{momentum-accelerated} proximal method (forming the outer loop) that seamlessly incorporates any selected decentralized algorithm (as the inner loop). We demonstrate that DCatalyst achieves optimal communication and computational complexity (up to log-factors) across various decentralized algorithms and problem instances. Notably, it extends acceleration capabilities to problem classes previously lacking accelerated solution methods, thereby broadening the effectiveness of decentralized methods. On the technical side, our framework introduce the {\it inexact estimating sequences}--a novel extension of the well-known Nesterov's estimating sequences, tailored for the minimization of composite losses in decentralized settings. This method adeptly handles consensus errors and inexact solutions of agents' subproblems, challenges not addressed by existing models.
Enhancing Convergence of Decentralized Gradient Tracking under the KL Property
Dec 12, 2024



We study decentralized multiagent optimization over networks, modeled as undirected graphs. The optimization problem consists of minimizing a nonconvex smooth function plus a convex extended-value function, which enforces constraints or extra structure on the solution (e.g., sparsity, low-rank). We further assume that the objective function satisfies the Kurdyka-{\L}ojasiewicz (KL) property, with given exponent $\theta\in [0,1)$. The KL property is satisfied by several (nonconvex) functions of practical interest, e.g., arising from machine learning applications; in the centralized setting, it permits to achieve strong convergence guarantees. Here we establish convergence of the same type for the notorious decentralized gradient-tracking-based algorithm SONATA. Specifically, $\textbf{(i)}$ when $\theta\in (0,1/2]$, the sequence generated by SONATA converges to a stationary solution of the problem at R-linear rate;$ \textbf{(ii)} $when $\theta\in (1/2,1)$, sublinear rate is certified; and finally $\textbf{(iii)}$ when $\theta=0$, the iterates will either converge in a finite number of steps or converges at R-linear rate. This matches the convergence behavior of centralized proximal-gradient algorithms except when $\theta=0$. Numerical results validate our theoretical findings.
Multi-Party Supervised Fine-tuning of Language Models for Multi-Party Dialogue Generation
Dec 06, 2024Large Language Models (LLM) are usually fine-tuned to participate in dyadic or two-party dialogues, which can not adapt well to multi-party dialogues (MPD), which hinders their applications in such scenarios including multi-personal meetings, discussions and daily communication. Previous LLM-based researches mainly focus on the multi-agent framework, while their base LLMs are still pairwisely fine-tuned. In this work, we design a multi-party fine-tuning framework (MuPaS) for LLMs on the multi-party dialogue datasets, and prove such a straightforward framework can let the LLM align with the multi-party conversation style efficiently and effectively. We also design two training strategies which can convert MuPaS into the MPD simulator. Substantial experiments show that MuPaS can achieve state-of-the-art multi-party response, higher accuracy of the-next-speaker prediction, higher human and automatic evaluated utterance qualities, and can even generate reasonably with out-of-distribution scene, topic and role descriptions. The MuPaS framework bridges the LLM training with more complicated multi-party applications, such as conversation generation, virtual rehearsal or meta-universe.
Discrete Conditional Diffusion for Reranking in Recommendation
Aug 14, 2023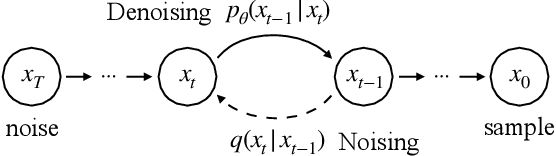
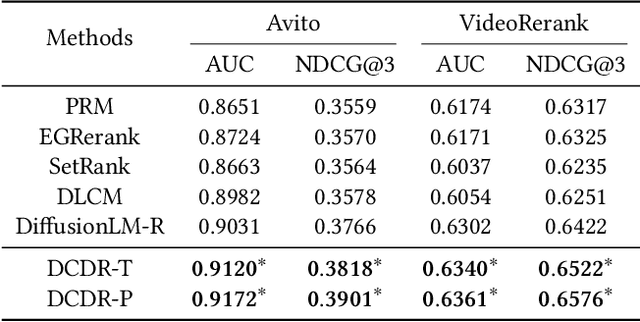
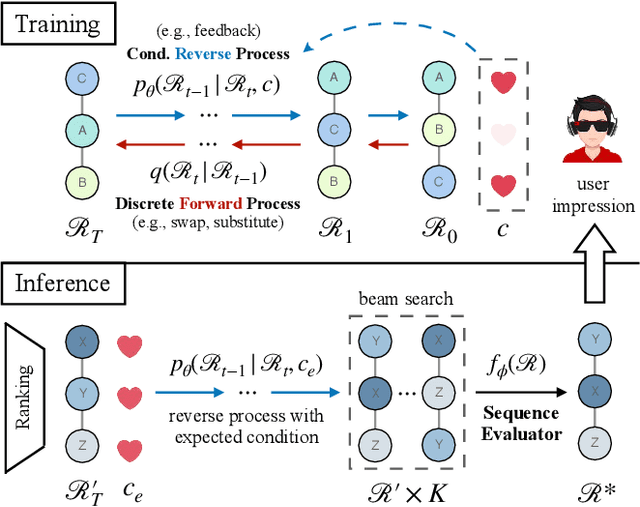

Reranking plays a crucial role in modern multi-stage recommender systems by rearranging the initial ranking list to model interplay between items. Considering the inherent challenges of reranking such as combinatorial searching space, some previous studies have adopted the evaluator-generator paradigm, with a generator producing feasible sequences and a evaluator selecting the best one based on estimated listwise utility. Inspired by the remarkable success of diffusion generative models, this paper explores the potential of diffusion models for generating high-quality sequences in reranking. However, we argue that it is nontrivial to take diffusion models as the generator in the context of recommendation. Firstly, diffusion models primarily operate in continuous data space, differing from the discrete data space of item permutations. Secondly, the recommendation task is different from conventional generation tasks as the purpose of recommender systems is to fulfill user interests. Lastly, real-life recommender systems require efficiency, posing challenges for the inference of diffusion models. To overcome these challenges, we propose a novel Discrete Conditional Diffusion Reranking (DCDR) framework for recommendation. DCDR extends traditional diffusion models by introducing a discrete forward process with tractable posteriors, which adds noise to item sequences through step-wise discrete operations (e.g., swapping). Additionally, DCDR incorporates a conditional reverse process that generates item sequences conditioned on expected user responses. Extensive offline experiments conducted on public datasets demonstrate that DCDR outperforms state-of-the-art reranking methods. Furthermore, DCDR has been deployed in a real-world video app with over 300 million daily active users, significantly enhancing online recommendation quality.
Tree based Progressive Regression Model for Watch-Time Prediction in Short-video Recommendation
Jun 06, 2023
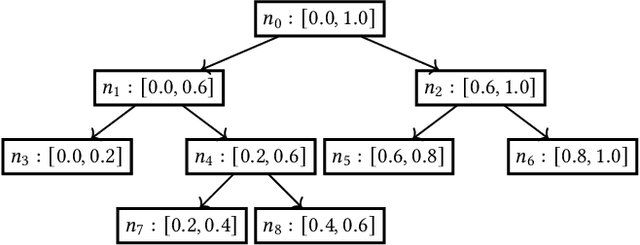
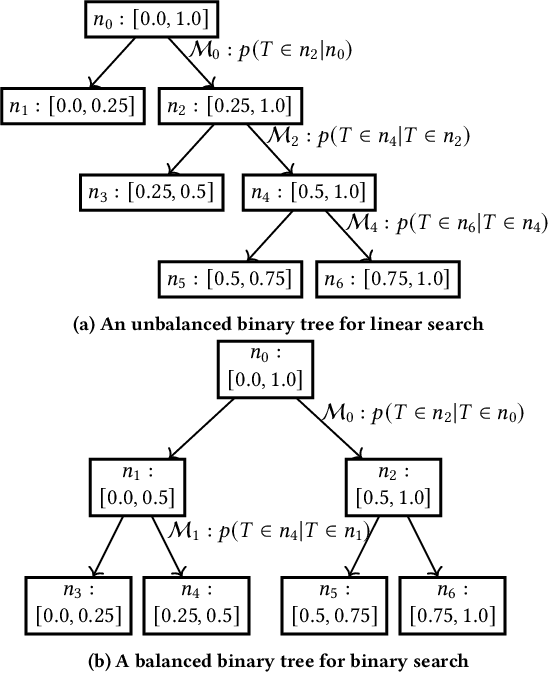

An accurate prediction of watch time has been of vital importance to enhance user engagement in video recommender systems. To achieve this, there are four properties that a watch time prediction framework should satisfy: first, despite its continuous value, watch time is also an ordinal variable and the relative ordering between its values reflects the differences in user preferences. Therefore the ordinal relations should be reflected in watch time predictions. Second, the conditional dependence between the video-watching behaviors should be captured in the model. For instance, one has to watch half of the video before he/she finishes watching the whole video. Third, modeling watch time with a point estimation ignores the fact that models might give results with high uncertainty and this could cause bad cases in recommender systems. Therefore the framework should be aware of prediction uncertainty. Forth, the real-life recommender systems suffer from severe bias amplifications thus an estimation without bias amplification is expected. Therefore we propose TPM for watch time prediction. Specifically, the ordinal ranks of watch time are introduced into TPM and the problem is decomposed into a series of conditional dependent classification tasks which are organized into a tree structure. The expectation of watch time can be generated by traversing the tree and the variance of watch time predictions is explicitly introduced into the objective function as a measurement for uncertainty. Moreover, we illustrate that backdoor adjustment can be seamlessly incorporated into TPM, which alleviates bias amplifications. Extensive offline evaluations have been conducted in public datasets and TPM have been deployed in a real-world video app Kuaishou with over 300 million DAUs. The results indicate that TPM outperforms state-of-the-art approaches and indeed improves video consumption significantly.
Boosting share routing for multi-task learning
Sep 01, 2020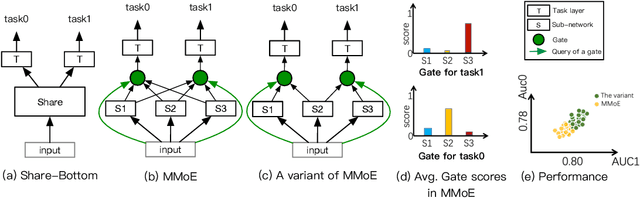

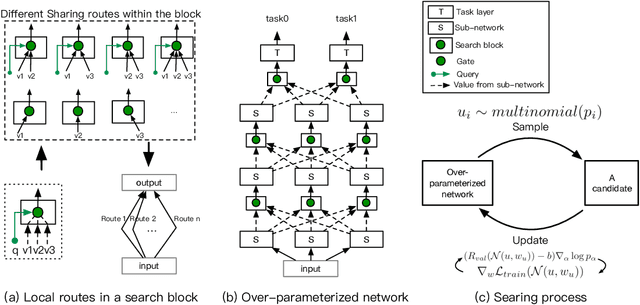
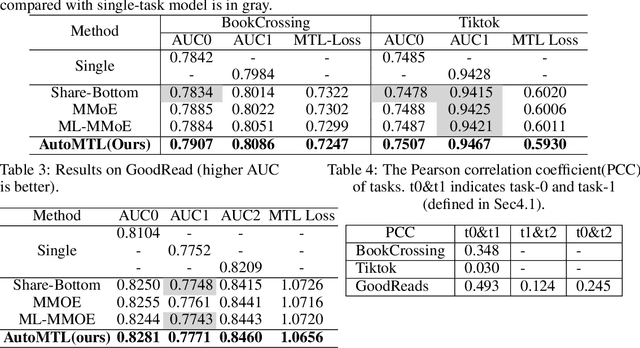
Multi-task learning (MTL) aims to make full use of the knowledge contained in multi-task supervision signals to improve the overall performance. How to make the knowledge of multiple tasks shared appropriately is an open problem for MTL. Most existing deep MTL models are based on parameter sharing. However, suitable sharing mechanism is hard to design as the relationship among tasks is complicated. In this paper, we propose a general framework called Multi-Task Neural Architecture Search (MTNAS) to efficiently find a suitable sharing route for a given MTL problem. MTNAS modularizes the sharing part into multiple layers of sub-networks. It allows sparse connection among these sub-networks and soft sharing based on gating is enabled for a certain route. Benefiting from such setting, each candidate architecture in our search space defines a dynamic sparse sharing route which is more flexible compared with full-sharing in previous approaches. We show that existing typical sharing approaches are sub-graphs in our search space. Extensive experiments on three real-world recommendation datasets demonstrate MTANS achieves consistent improvement compared with single-task models and typical multi-task methods while maintaining high computation efficiency. Furthermore, in-depth experiments demonstrates that MTNAS can learn suitable sparse route to mitigate negative transfer.