 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClarifying Before Reasoning: A Coq Prover with Structural Context
Jul 03, 2025In this work, we investigate whether improving task clarity can enhance reasoning ability of large language models, focusing on theorem proving in Coq. We introduce a concept-level metric to evaluate task clarity and show that adding structured semantic context to the standard input used by modern LLMs, leads to a 1.85$\times$ improvement in clarity score (44.5\%~$\rightarrow$~82.3\%). Using the general-purpose model \texttt{DeepSeek-V3}, our approach leads to a 2.1$\times$ improvement in proof success (21.8\%~$\rightarrow$~45.8\%) and outperforms the previous state-of-the-art \texttt{Graph2Tac} (33.2\%). We evaluate this on 1,386 theorems randomly sampled from 15 standard Coq packages, following the same evaluation protocol as \texttt{Graph2Tac}. Furthermore, fine-tuning smaller models on our structured data can achieve even higher performance (48.6\%). Our method uses selective concept unfolding to enrich task descriptions, and employs a Planner--Executor architecture. These findings highlight the value of structured task representations in bridging the gap between understanding and reasoning.
Fed-NDIF: A Noise-Embedded Federated Diffusion Model For Low-Count Whole-Body PET Denoising
Mar 20, 2025



Low-count positron emission tomography (LCPET) imaging can reduce patients' exposure to radiation but often suffers from increased image noise and reduced lesion detectability, necessitating effective denoising techniques. Diffusion models have shown promise in LCPET denoising for recovering degraded image quality. However, training such models requires large and diverse datasets, which are challenging to obtain in the medical domain. To address data scarcity and privacy concerns, we combine diffusion models with federated learning -- a decentralized training approach where models are trained individually at different sites, and their parameters are aggregated on a central server over multiple iterations. The variation in scanner types and image noise levels within and across institutions poses additional challenges for federated learning in LCPET denoising. In this study, we propose a novel noise-embedded federated learning diffusion model (Fed-NDIF) to address these challenges, leveraging a multicenter dataset and varying count levels. Our approach incorporates liver normalized standard deviation (NSTD) noise embedding into a 2.5D diffusion model and utilizes the Federated Averaging (FedAvg) algorithm to aggregate locally trained models into a global model, which is subsequently fine-tuned on local datasets to optimize performance and obtain personalized models. Extensive validation on datasets from the University of Bern, Ruijin Hospital in Shanghai, and Yale-New Haven Hospital demonstrates the superior performance of our method in enhancing image quality and improving lesion quantification. The Fed-NDIF model shows significant improvements in PSNR, SSIM, and NMSE of the entire 3D volume, as well as enhanced lesion detectability and quantification, compared to local diffusion models and federated UNet-based models.
An Interpretable ML-based Model for Predicting p-y Curves of Monopile Foundations in Sand
Jan 08, 2025



Predicting the lateral pile response is challenging due to the complexity of pile-soil interactions. Machine learning (ML) techniques have gained considerable attention for their effectiveness in non-linear analysis and prediction. This study develops an interpretable ML-based model for predicting p-y curves of monopile foundations. An XGBoost model was trained using a database compiled from existing research. The results demonstrate that the model achieves superior predictive accuracy. Shapley Additive Explanations (SHAP) was employed to enhance interpretability. The SHAP value distributions for each variable demonstrate strong alignment with established theoretical knowledge on factors affecting the lateral response of pile foundations.
Bi-directional Mapping of Morphology Metrics and 3D City Blocks for Enhanced Characterization and Generation of Urban Form
Dec 20, 2024Urban morphology, examining city spatial configurations, links urban design to sustainability. Morphology metrics play a fundamental role in performance-driven computational urban design (CUD) which integrates urban form generation, performance evaluation and optimization. However, a critical gap remains between performance evaluation and complex urban form generation, caused by the disconnection between morphology metrics and urban form, particularly in metric-to-form workflows. It prevents the application of optimized metrics to generate improved urban form with enhanced urban performance. Formulating morphology metrics that not only effectively characterize complex urban forms but also enable the reconstruction of diverse forms is of significant importance. This paper highlights the importance of establishing a bi-directional mapping between morphology metrics and complex urban form to enable the integration of urban form generation with performance evaluation. We present an approach that can 1) formulate morphology metrics to both characterize urban forms and in reverse, retrieve diverse similar 3D urban forms, and 2) evaluate the effectiveness of morphology metrics in representing 3D urban form characteristics of blocks by comparison. We demonstrate the methodology with 3D urban models of New York City, covering 14,248 blocks. We use neural networks and information retrieval for morphology metric encoding, urban form clustering and morphology metric evaluation. We identified an effective set of morphology metrics for characterizing block-scale urban forms through comparison. The proposed methodology tightly couples complex urban forms with morphology metrics, hence it can enable a seamless and bidirectional relationship between urban form generation and optimization in performance-driven urban design towards sustainable urban design and planning.
Complexity boosted adaptive training for better low resource ASR performance
Dec 01, 2024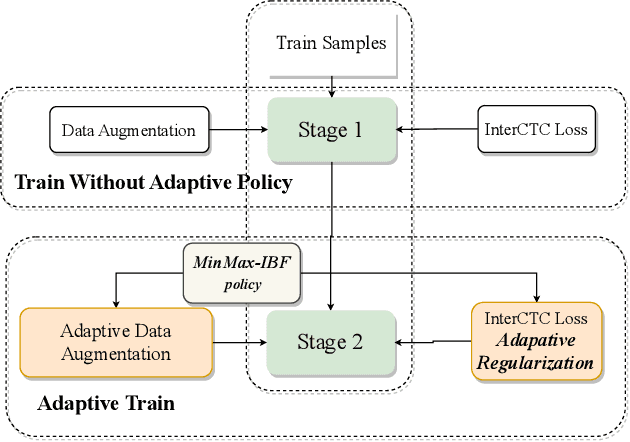

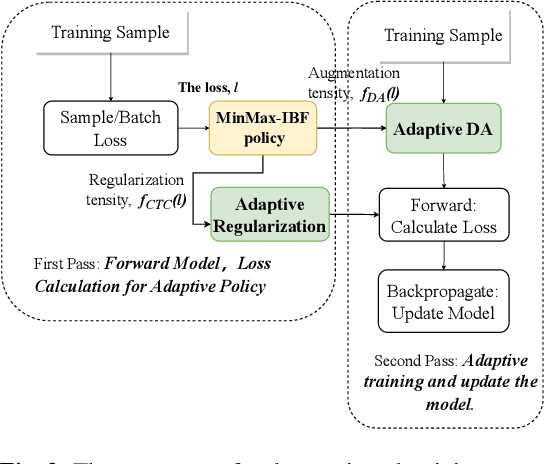

During the entire training process of the ASR model, the intensity of data augmentation and the approach of calculating training loss are applied in a regulated manner based on preset parameters. For example, SpecAugment employs a predefined strength of augmentation to mask parts of the time-frequency domain spectrum. Similarly, in CTC-based multi-layer models, the loss is generally determined based on the output of the encoder's final layer during the training process. However, ignoring dynamic characteristics may suboptimally train models. To address the issue, we present a two-stage training method, known as complexity-boosted adaptive (CBA) training. It involves making dynamic adjustments to data augmentation strategies and CTC loss propagation based on the complexity of the training samples. In the first stage, we train the model with intermediate-CTC-based regularization and data augmentation without any adaptive policy. In the second stage, we propose a novel adaptive policy, called MinMax-IBF, which calculates the complexity of samples. We combine the MinMax-IBF policy to data augmentation and intermediate CTC loss regularization to continue training. The proposed CBA training approach shows considerable improvements, up to 13.4% and 14.1% relative reduction in WER on the LibriSpeech 100h test-clean and test-other dataset and also up to 6.3% relative reduction on AISHELL-1 test set, over the Conformer architecture in Wenet.
Sample adaptive data augmentation with progressive scheduling
Nov 30, 2024



Data augmentation is a widely adopted technique utilized to improve the robustness of automatic speech recognition (ASR). Employing a fixed data augmentation strategy for all training data is a common practice. However, it is important to note that there can be variations in factors such as background noise, speech rate, etc. among different samples within a single training batch. By using a fixed augmentation strategy, there is a risk that the model may reach a suboptimal state. In addition to the risks of employing a fixed augmentation strategy, the model's capabilities may differ across various training stages. To address these issues, this paper proposes the method of sample-adaptive data augmentation with progressive scheduling(PS-SapAug). The proposed method applies dynamic data augmentation in a two-stage training approach. It employs hybrid normalization to compute sample-specific augmentation parameters based on each sample's loss. Additionally, the probability of augmentation gradually increases throughout the training progression. Our method is evaluated on popular ASR benchmark datasets, including Aishell-1 and Librispeech-100h, achieving up to 8.13% WER reduction on LibriSpeech-100h test-clean, 6.23% on test-other, and 5.26% on AISHELL-1 test set, which demonstrate the efficacy of our approach enhancing performance and minimizing errors.
Lighten CARAFE: Dynamic Lightweight Upsampling with Guided Reassemble Kernels
Oct 29, 2024As a fundamental operation in modern machine vision models, feature upsampling has been widely used and investigated in the literatures. An ideal upsampling operation should be lightweight, with low computational complexity. That is, it can not only improve the overall performance but also not affect the model complexity. Content-aware Reassembly of Features (CARAFE) is a well-designed learnable operation to achieve feature upsampling. Albeit encouraging performance achieved, this method requires generating large-scale kernels, which brings a mass of extra redundant parameters, and inherently has limited scalability. To this end, we propose a lightweight upsampling operation, termed Dynamic Lightweight Upsampling (DLU) in this paper. In particular, it first constructs a small-scale source kernel space, and then samples the large-scale kernels from the kernel space by introducing learnable guidance offsets, hence avoiding introducing a large collection of trainable parameters in upsampling. Experiments on several mainstream vision tasks show that our DLU achieves comparable and even better performance to the original CARAFE, but with much lower complexity, e.g., DLU requires 91% fewer parameters and at least 63% fewer FLOPs (Floating Point Operations) than CARAFE in the case of 16x upsampling, but outperforms the CARAFE by 0.3% mAP in object detection. Code is available at https://github.com/Fu0511/Dynamic-Lightweight-Upsampling.
LpQcM: Adaptable Lesion-Quantification-Consistent Modulation for Deep Learning Low-Count PET Image Denoising
Apr 27, 2024
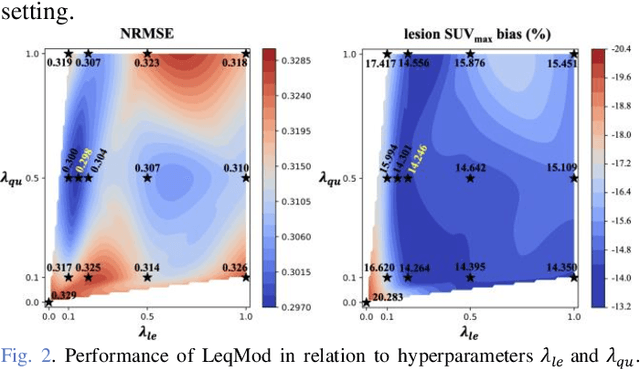


Deep learning-based positron emission tomography (PET) image denoising offers the potential to reduce radiation exposure and scanning time by transforming low-count images into high-count equivalents. However, existing methods typically blur crucial details, leading to inaccurate lesion quantification. This paper proposes a lesion-perceived and quantification-consistent modulation (LpQcM) strategy for enhanced PET image denoising, via employing downstream lesion quantification analysis as auxiliary tools. The LpQcM is a plug-and-play design adaptable to a wide range of model architectures, modulating the sampling and optimization procedures of model training without adding any computational burden to the inference phase. Specifically, the LpQcM consists of two components, the lesion-perceived modulation (LpM) and the multiscale quantification-consistent modulation (QcM). The LpM enhances lesion contrast and visibility by allocating higher sampling weights and stricter loss criteria to lesion-present samples determined by an auxiliary segmentation network than lesion-absent ones. The QcM further emphasizes accuracy of quantification for both the mean and maximum standardized uptake value (SUVmean and SUVmax) across multiscale sub-regions throughout the entire image, thereby enhancing the overall image quality. Experiments conducted on large PET datasets from multiple centers and vendors, and varying noise levels demonstrated the LpQcM efficacy across various denoising frameworks. Compared to frameworks without LpQcM, the integration of LpQcM reduces the lesion SUVmean bias by 2.92% on average and increases the peak signal-to-noise ratio (PSNR) by 0.34 on average, for denoising images of extremely low-count levels below 10%.
Discrete Conditional Diffusion for Reranking in Recommendation
Aug 14, 2023
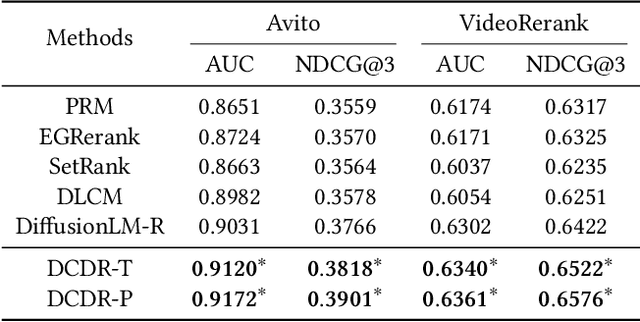
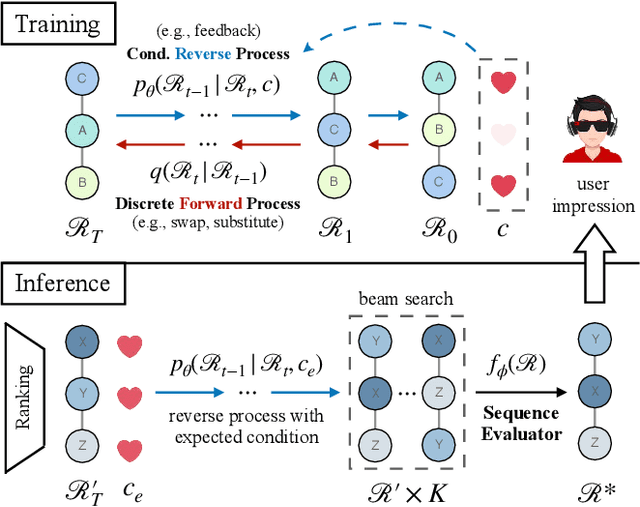

Reranking plays a crucial role in modern multi-stage recommender systems by rearranging the initial ranking list to model interplay between items. Considering the inherent challenges of reranking such as combinatorial searching space, some previous studies have adopted the evaluator-generator paradigm, with a generator producing feasible sequences and a evaluator selecting the best one based on estimated listwise utility. Inspired by the remarkable success of diffusion generative models, this paper explores the potential of diffusion models for generating high-quality sequences in reranking. However, we argue that it is nontrivial to take diffusion models as the generator in the context of recommendation. Firstly, diffusion models primarily operate in continuous data space, differing from the discrete data space of item permutations. Secondly, the recommendation task is different from conventional generation tasks as the purpose of recommender systems is to fulfill user interests. Lastly, real-life recommender systems require efficiency, posing challenges for the inference of diffusion models. To overcome these challenges, we propose a novel Discrete Conditional Diffusion Reranking (DCDR) framework for recommendation. DCDR extends traditional diffusion models by introducing a discrete forward process with tractable posteriors, which adds noise to item sequences through step-wise discrete operations (e.g., swapping). Additionally, DCDR incorporates a conditional reverse process that generates item sequences conditioned on expected user responses. Extensive offline experiments conducted on public datasets demonstrate that DCDR outperforms state-of-the-art reranking methods. Furthermore, DCDR has been deployed in a real-world video app with over 300 million daily active users, significantly enhancing online recommendation quality.
Measuring Item Global Residual Value for Fair Recommendation
Jul 17, 2023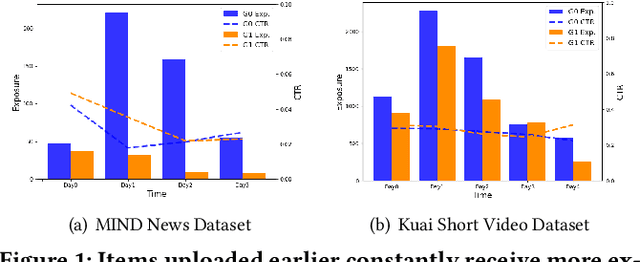

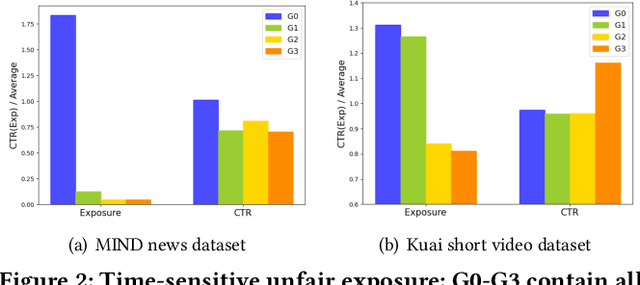

In the era of information explosion, numerous items emerge every day, especially in feed scenarios. Due to the limited system display slots and user browsing attention, various recommendation systems are designed not only to satisfy users' personalized information needs but also to allocate items' exposure. However, recent recommendation studies mainly focus on modeling user preferences to present satisfying results and maximize user interactions, while paying little attention to developing item-side fair exposure mechanisms for rational information delivery. This may lead to serious resource allocation problems on the item side, such as the Snowball Effect. Furthermore, unfair exposure mechanisms may hurt recommendation performance. In this paper, we call for a shift of attention from modeling user preferences to developing fair exposure mechanisms for items. We first conduct empirical analyses of feed scenarios to explore exposure problems between items with distinct uploaded times. This points out that unfair exposure caused by the time factor may be the major cause of the Snowball Effect. Then, we propose to explicitly model item-level customized timeliness distribution, Global Residual Value (GRV), for fair resource allocation. This GRV module is introduced into recommendations with the designed Timeliness-aware Fair Recommendation Framework (TaFR). Extensive experiments on two datasets demonstrate that TaFR achieves consistent improvements with various backbone recommendation models. By modeling item-side customized Global Residual Value, we achieve a fairer distribution of resources and, at the same time, improve recommendation performance.