 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhite-Box Op-Amp Design via Human-Mimicking Reasoning
Jan 29, 2026This brief proposes \emph{White-Op}, an interpretable operational amplifier (op-amp) parameter design framework based on the human-mimicking reasoning of large-language-model agents. We formalize the implicit human reasoning mechanism into explicit steps of \emph{\textbf{introducing hypothetical constraints}}, and develop an iterative, human-like \emph{\textbf{hypothesis-verification-decision}} workflow. Specifically, the agent is guided to introduce hypothetical constraints to derive and properly regulate positions of symbolically tractable poles and zeros, thus formulating a closed-form mathematical optimization problem, which is then solved programmatically and verified via simulation. Theory-simulation result analysis guides the decision-making for refinement. Experiments on 9 op-amp topologies show that, unlike the uninterpretable black-box baseline which finally fails in 5 topologies, White-Op achieves reliable, interpretable behavioral-level designs with only 8.52\% theoretical prediction error and the design functionality retains after transistor-level mapping for all topologies. White-Op is open-sourced at \textcolor{blue}{https://github.com/zhchenfdu/whiteop}.
Making Every Head Count: Sparse Attention Without the Speed-Performance Trade-off
Nov 12, 2025The design of Large Language Models (LLMs) has long been hampered by a fundamental conflict within their core attention mechanism: its remarkable expressivity is built upon a computational complexity of $O(H \cdot N^2)$ that grows quadratically with the context size ($N$) and linearly with the number of heads ($H$). This standard implementation harbors significant computational redundancy, as all heads independently compute attention over the same sequence space. Existing sparse methods, meanwhile, often trade information integrity for computational efficiency. To resolve this efficiency-performance trade-off, we propose SPAttention, whose core contribution is the introduction of a new paradigm we term Principled Structural Sparsity. SPAttention does not merely drop connections but instead reorganizes the computational task by partitioning the total attention workload into balanced, non-overlapping distance bands, assigning each head a unique segment. This approach transforms the multi-head attention mechanism from $H$ independent $O(N^2)$ computations into a single, collaborative $O(N^2)$ computation, fundamentally reducing complexity by a factor of $H$. The structured inductive bias compels functional specialization among heads, enabling a more efficient allocation of computational resources from redundant modeling to distinct dependencies across the entire sequence span. Extensive empirical validation on the OLMoE-1B-7B and 0.25B-1.75B model series demonstrates that while delivering an approximately two-fold increase in training throughput, its performance is on par with standard dense attention, even surpassing it on select key metrics, while consistently outperforming representative sparse attention methods including Longformer, Reformer, and BigBird across all evaluation metrics.
GSE: Evaluating Sticker Visual Semantic Similarity via a General Sticker Encoder
Nov 07, 2025
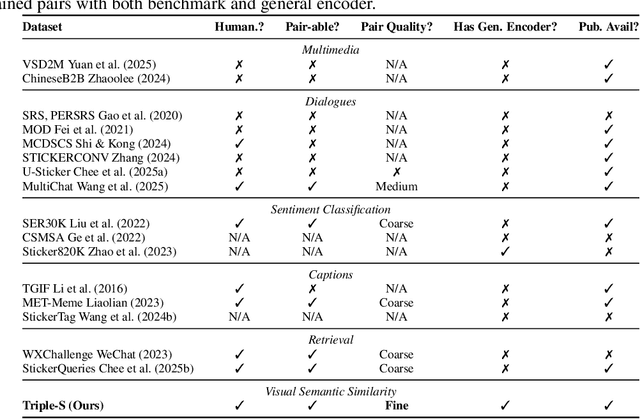
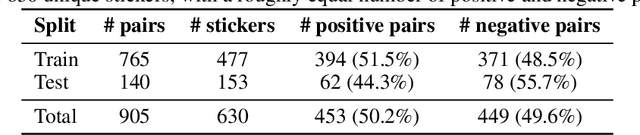
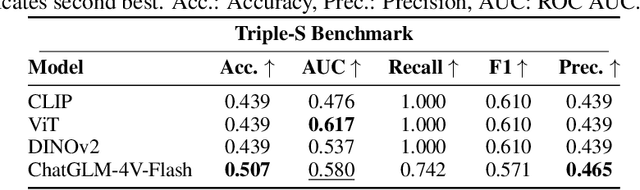
Stickers have become a popular form of visual communication, yet understanding their semantic relationships remains challenging due to their highly diverse and symbolic content. In this work, we formally {define the Sticker Semantic Similarity task} and introduce {Triple-S}, the first benchmark for this task, consisting of 905 human-annotated positive and negative sticker pairs. Through extensive evaluation, we show that existing pretrained vision and multimodal models struggle to capture nuanced sticker semantics. To address this, we propose the {General Sticker Encoder (GSE)}, a lightweight and versatile model that learns robust sticker embeddings using both Triple-S and additional datasets. GSE achieves superior performance on unseen stickers, and demonstrates strong results on downstream tasks such as emotion classification and sticker-to-sticker retrieval. By releasing both Triple-S and GSE, we provide standardized evaluation tools and robust embeddings, enabling future research in sticker understanding, retrieval, and multimodal content generation. The Triple-S benchmark and GSE have been publicly released and are available here.
How Far Can LLMs Improve from Experience? Measuring Test-Time Learning Ability in LLMs with Human Comparison
Jun 17, 2025As evaluation designs of large language models may shape our trajectory toward artificial general intelligence, comprehensive and forward-looking assessment is essential. Existing benchmarks primarily assess static knowledge, while intelligence also entails the ability to rapidly learn from experience. To this end, we advocate for the evaluation of Test-time Learning, the capacity to improve performance in experience-based, reasoning-intensive tasks during test time. In this work, we propose semantic games as effective testbeds for evaluating test-time learning, due to their resistance to saturation and inherent demand for strategic reasoning. We introduce an objective evaluation framework that compares model performance under both limited and cumulative experience settings, and contains four forms of experience representation. To provide a comparative baseline, we recruit eight human participants to complete the same task. Results show that LLMs exhibit measurable test-time learning capabilities; however, their improvements are less stable under cumulative experience and progress more slowly than those observed in humans. These findings underscore the potential of LLMs as general-purpose learning machines, while also revealing a substantial intellectual gap between models and humans, irrespective of how well LLMs perform on static benchmarks.
RIVAL: Reinforcement Learning with Iterative and Adversarial Optimization for Machine Translation
Jun 05, 2025Large language models (LLMs) possess strong multilingual capabilities, and combining Reinforcement Learning from Human Feedback (RLHF) with translation tasks has shown great potential. However, we observe that this paradigm performs unexpectedly poorly when applied to colloquial subtitle translation tasks. In this work, we investigate this issue and find that the offline reward model (RM) gradually diverges from the online LLM due to distributional shift, ultimately leading to undesirable training outcomes. To address this, we propose RIVAL, an adversarial training framework that formulates the process as a min-max game between the RM and the LLM. RIVAL iteratively updates the both models, with the RM trained to distinguish strong from weak translations (qualitative preference reward), and the LLM trained to enhance its translation for closing this gap. To stabilize training and improve generalizability, we also incorporate quantitative preference reward (e.g., BLEU) into the RM, enabling reference-free quality modeling aligned with human evaluation. Through extensive experiments, we demonstrate that the proposed adversarial training framework significantly improves upon translation baselines.
WXImpactBench: A Disruptive Weather Impact Understanding Benchmark for Evaluating Large Language Models
May 26, 2025Climate change adaptation requires the understanding of disruptive weather impacts on society, where large language models (LLMs) might be applicable. However, their effectiveness is under-explored due to the difficulty of high-quality corpus collection and the lack of available benchmarks. The climate-related events stored in regional newspapers record how communities adapted and recovered from disasters. However, the processing of the original corpus is non-trivial. In this study, we first develop a disruptive weather impact dataset with a four-stage well-crafted construction pipeline. Then, we propose WXImpactBench, the first benchmark for evaluating the capacity of LLMs on disruptive weather impacts. The benchmark involves two evaluation tasks, multi-label classification and ranking-based question answering. Extensive experiments on evaluating a set of LLMs provide first-hand analysis of the challenges in developing disruptive weather impact understanding and climate change adaptation systems. The constructed dataset and the code for the evaluation framework are available to help society protect against vulnerabilities from disasters.
A 106K Multi-Topic Multilingual Conversational User Dataset with Emoticons
Feb 26, 2025Instant messaging has become a predominant form of communication, with texts and emoticons enabling users to express emotions and ideas efficiently. Emoticons, in particular, have gained significant traction as a medium for conveying sentiments and information, leading to the growing importance of emoticon retrieval and recommendation systems. However, one of the key challenges in this area has been the absence of datasets that capture both the temporal dynamics and user-specific interactions with emoticons, limiting the progress of personalized user modeling and recommendation approaches. To address this, we introduce the emoticon dataset, a comprehensive resource that includes time-based data along with anonymous user identifiers across different conversations. As the largest publicly accessible emoticon dataset to date, it comprises 22K unique users, 370K emoticons, and 8.3M messages. The data was collected from a widely-used messaging platform across 67 conversations and 720 hours of crawling. Strict privacy and safety checks were applied to ensure the integrity of both text and image data. Spanning across 10 distinct domains, the emoticon dataset provides rich insights into temporal, multilingual, and cross-domain behaviors, which were previously unavailable in other emoticon-based datasets. Our in-depth experiments, both quantitative and qualitative, demonstrate the dataset's potential in modeling user behavior and personalized recommendation systems, opening up new possibilities for research in personalized retrieval and conversational AI. The dataset is freely accessible.
Image-to-Force Estimation for Soft Tissue Interaction in Robotic-Assisted Surgery Using Structured Light
Jan 15, 2025For Minimally Invasive Surgical (MIS) robots, accurate haptic interaction force feedback is essential for ensuring the safety of interacting with soft tissue. However, most existing MIS robotic systems cannot facilitate direct measurement of the interaction force with hardware sensors due to space limitations. This letter introduces an effective vision-based scheme that utilizes a One-Shot structured light projection with a designed pattern on soft tissue coupled with haptic information processing through a trained image-to-force neural network. The images captured from the endoscopic stereo camera are analyzed to reconstruct high-resolution 3D point clouds for soft tissue deformation. Based on this, a modified PointNet-based force estimation method is proposed, which excels in representing the complex mechanical properties of soft tissue. Numerical force interaction experiments are conducted on three silicon materials with different stiffness. The results validate the effectiveness of the proposed scheme.
Interpret the Internal States of Recommendation Model with Sparse Autoencoder
Nov 09, 2024



Explainable recommendation systems are important to enhance transparency, accuracy, and fairness. Beyond result-level explanations, model-level interpretations can provide valuable insights that allow developers to optimize system designs and implement targeted improvements. However, most current approaches depend on specialized model designs, which often lack generalization capabilities. Given the various kinds of recommendation models, existing methods have limited ability to effectively interpret them. To address this issue, we propose RecSAE, an automatic, generalizable probing method for interpreting the internal states of Recommendation models with Sparse AutoEncoder. RecSAE serves as a plug-in module that does not affect original models during interpretations, while also enabling predictable modifications to their behaviors based on interpretation results. Firstly, we train an autoencoder with sparsity constraints to reconstruct internal activations of recommendation models, making the RecSAE latents more interpretable and monosemantic than the original neuron activations. Secondly, we automated the construction of concept dictionaries based on the relationship between latent activations and input item sequences. Thirdly, RecSAE validates these interpretations by predicting latent activations on new item sequences using the concept dictionary and deriving interpretation confidence scores from precision and recall. We demonstrate RecSAE's effectiveness on two datasets, identifying hundreds of highly interpretable concepts from pure ID-based models. Latent ablation studies further confirm that manipulating latent concepts produces corresponding changes in model output behavior, underscoring RecSAE's utility for both understanding and targeted tuning recommendation models. Code and data are publicly available at https://github.com/Alice1998/RecSAE.
Beyond Utility: Evaluating LLM as Recommender
Nov 01, 2024



With the rapid development of Large Language Models (LLMs), recent studies employed LLMs as recommenders to provide personalized information services for distinct users. Despite efforts to improve the accuracy of LLM-based recommendation models, relatively little attention is paid to beyond-utility dimensions. Moreover, there are unique evaluation aspects of LLM-based recommendation models, which have been largely ignored. To bridge this gap, we explore four new evaluation dimensions and propose a multidimensional evaluation framework. The new evaluation dimensions include: 1) history length sensitivity, 2) candidate position bias, 3) generation-involved performance, and 4) hallucinations. All four dimensions have the potential to impact performance, but are largely unnecessary for consideration in traditional systems. Using this multidimensional evaluation framework, along with traditional aspects, we evaluate the performance of seven LLM-based recommenders, with three prompting strategies, comparing them with six traditional models on both ranking and re-ranking tasks on four datasets. We find that LLMs excel at handling tasks with prior knowledge and shorter input histories in the ranking setting, and perform better in the re-ranking setting, beating traditional models across multiple dimensions. However, LLMs exhibit substantial candidate position bias issues, and some models hallucinate non-existent items much more often than others. We intend our evaluation framework and observations to benefit future research on the use of LLMs as recommenders. The code and data are available at https://github.com/JiangDeccc/EvaLLMasRecommender.