 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeADORE: Iterative Query Expansion with Retrieval-Grounded Relevance Feedback
Jun 11, 2026LLM-based query expansion improves retrieval by enriching the original query with additional context. Yet most methods remain generation-driven, producing plausible pseudo-documents or expansions without checking how the target corpus responds. This can introduce retrieval drift, amplify misleading vocabulary, or miss terms that distinguish relevant from non-relevant documents. We argue that effective expansion requires retrieval-grounded feedback, not just single-pass generation or unverified iteration. We introduce ADORE (ADapt, Observe, Relevance Evaluate), an iterative framework that turns retrieval outcomes into feedback for the next expansion. At each round, an LLM generates pseudo-passages, a retriever exposes the corpus response, and a relevance assessor evaluates retrieved documents against the original query. These judgments identify what to reinforce, what remains undercovered, and what to suppress. Across TREC Deep Learning, BEIR, and BRIGHT, ADORE consistently outperforms strong query expansion baselines with notable improvements across nearly all evaluation settings, improving average nDCG@10 by 24.5% over BM25 and 3.6% over the strongest prior query expansion method on BEIR, and by 122.9% over BM25 and 9.2% over the best query expansion baseline on BRIGHT. Our code and data are publicly available.
ReFormeR: Learning and Applying Explicit Query Reformulation Patterns
Apr 01, 2026We present ReFormeR, a pattern-guided approach for query reformulation. Instead of prompting a language model to generate reformulations of a query directly, ReFormeR first elicits short reformulation patterns from pairs of initial queries and empirically stronger reformulations, consolidates them into a compact library of transferable reformulation patterns, and then selects an appropriate reformulation pattern for a new query given its retrieval context. The selected pattern constrains query reformulation to controlled operations such as sense disambiguation, vocabulary grounding, or discriminative facet addition, to name a few. As such, our proposed approach makes the reformulation policy explicit through these reformulation patterns, guiding the LLM towards targeted and effective query reformulations. Our extensive experiments on TREC DL 2019, DL 2020, and DL Hard show consistent improvements over classical feedback methods and recent LLM-based query reformulation and expansion approaches.
Resources for Automated Evaluation of Assistive RAG Systems that Help Readers with News Trustworthiness Assessment
Feb 27, 2026Many readers today struggle to assess the trustworthiness of online news because reliable reporting coexists with misinformation. The TREC 2025 DRAGUN (Detection, Retrieval, and Augmented Generation for Understanding News) Track provided a venue for researchers to develop and evaluate assistive RAG systems that support readers' news trustworthiness assessment by producing reader-oriented, well-attributed reports. As the organizers of the DRAGUN track, we describe the resources that we have newly developed to allow for the reuse of the track's tasks. The track had two tasks: (Task 1) Question Generation, producing 10 ranked investigative questions; and (Task 2, the main task) Report Generation, producing a 250-word report grounded in the MS MARCO V2.1 Segmented Corpus. As part of the track's evaluation, we had TREC assessors create importance-weighted rubrics of questions with expected short answers for 30 different news articles. These rubrics represent the information that assessors believe is important for readers to assess an article's trustworthiness. The assessors then used their rubrics to manually judge the participating teams' submitted runs. To make these tasks and their rubrics reusable, we have created an automated process to judge runs not part of the original assessing. We show that our AutoJudge ranks existing runs well compared to the TREC human-assessed evaluation (Kendall's $τ= 0.678$ for Task 1 and $τ= 0.872$ for Task 2). These resources enable both the evaluation of RAG systems for assistive news trustworthiness assessment and, with the human evaluation as a benchmark, research on improving automated RAG evaluation.
PLawBench: A Rubric-Based Benchmark for Evaluating LLMs in Real-World Legal Practice
Jan 23, 2026As large language models (LLMs) are increasingly applied to legal domain-specific tasks, evaluating their ability to perform legal work in real-world settings has become essential. However, existing legal benchmarks rely on simplified and highly standardized tasks, failing to capture the ambiguity, complexity, and reasoning demands of real legal practice. Moreover, prior evaluations often adopt coarse, single-dimensional metrics and do not explicitly assess fine-grained legal reasoning. To address these limitations, we introduce PLawBench, a Practical Law Benchmark designed to evaluate LLMs in realistic legal practice scenarios. Grounded in real-world legal workflows, PLawBench models the core processes of legal practitioners through three task categories: public legal consultation, practical case analysis, and legal document generation. These tasks assess a model's ability to identify legal issues and key facts, perform structured legal reasoning, and generate legally coherent documents. PLawBench comprises 850 questions across 13 practical legal scenarios, with each question accompanied by expert-designed evaluation rubrics, resulting in approximately 12,500 rubric items for fine-grained assessment. Using an LLM-based evaluator aligned with human expert judgments, we evaluate 10 state-of-the-art LLMs. Experimental results show that none achieves strong performance on PLawBench, revealing substantial limitations in the fine-grained legal reasoning capabilities of current LLMs and highlighting important directions for future evaluation and development of legal LLMs. Data is available at: https://github.com/skylenage/PLawbench.
Evaluation of Large Language Models in Legal Applications: Challenges, Methods, and Future Directions
Jan 21, 2026Large language models (LLMs) are being increasingly integrated into legal applications, including judicial decision support, legal practice assistance, and public-facing legal services. While LLMs show strong potential in handling legal knowledge and tasks, their deployment in real-world legal settings raises critical concerns beyond surface-level accuracy, involving the soundness of legal reasoning processes and trustworthy issues such as fairness and reliability. Systematic evaluation of LLM performance in legal tasks has therefore become essential for their responsible adoption. This survey identifies key challenges in evaluating LLMs for legal tasks grounded in real-world legal practice. We analyze the major difficulties involved in assessing LLM performance in the legal domain, including outcome correctness, reasoning reliability, and trustworthiness. Building on these challenges, we review and categorize existing evaluation methods and benchmarks according to their task design, datasets, and evaluation metrics. We further discuss the extent to which current approaches address these challenges, highlight their limitations, and outline future research directions toward more realistic, reliable, and legally grounded evaluation frameworks for LLMs in legal domains.
Benchmarking LLM-based Relevance Judgment Methods
Apr 17, 2025Large Language Models (LLMs) are increasingly deployed in both academic and industry settings to automate the evaluation of information seeking systems, particularly by generating graded relevance judgments. Previous work on LLM-based relevance assessment has primarily focused on replicating graded human relevance judgments through various prompting strategies. However, there has been limited exploration of alternative assessment methods or comprehensive comparative studies. In this paper, we systematically compare multiple LLM-based relevance assessment methods, including binary relevance judgments, graded relevance assessments, pairwise preference-based methods, and two nugget-based evaluation methods~--~document-agnostic and document-dependent. In addition to a traditional comparison based on system rankings using Kendall correlations, we also examine how well LLM judgments align with human preferences, as inferred from relevance grades. We conduct extensive experiments on datasets from three TREC Deep Learning tracks 2019, 2020 and 2021 as well as the ANTIQUE dataset, which focuses on non-factoid open-domain question answering. As part of our data release, we include relevance judgments generated by both an open-source (Llama3.2b) and a commercial (gpt-4o) model. Our goal is to \textit{reproduce} various LLM-based relevance judgment methods to provide a comprehensive comparison. All code, data, and resources are publicly available in our GitHub Repository at https://github.com/Narabzad/llm-relevance-judgement-comparison.
Judging the Judges: A Collection of LLM-Generated Relevance Judgements
Feb 19, 2025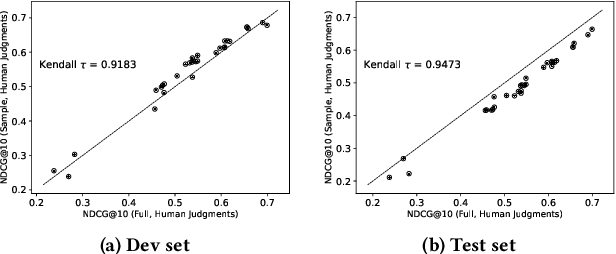
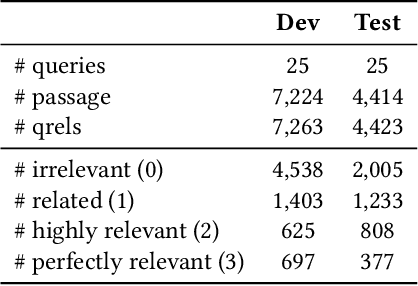
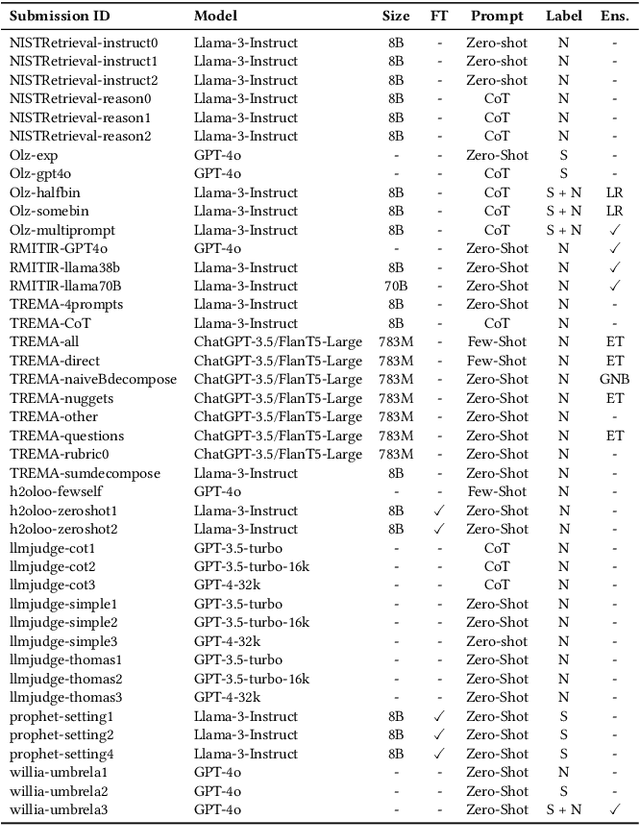
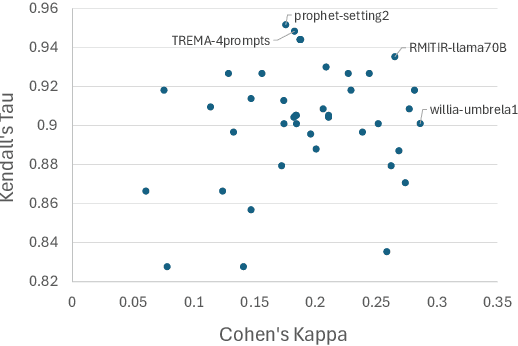
Using Large Language Models (LLMs) for relevance assessments offers promising opportunities to improve Information Retrieval (IR), Natural Language Processing (NLP), and related fields. Indeed, LLMs hold the promise of allowing IR experimenters to build evaluation collections with a fraction of the manual human labor currently required. This could help with fresh topics on which there is still limited knowledge and could mitigate the challenges of evaluating ranking systems in low-resource scenarios, where it is challenging to find human annotators. Given the fast-paced recent developments in the domain, many questions concerning LLMs as assessors are yet to be answered. Among the aspects that require further investigation, we can list the impact of various components in a relevance judgment generation pipeline, such as the prompt used or the LLM chosen. This paper benchmarks and reports on the results of a large-scale automatic relevance judgment evaluation, the LLMJudge challenge at SIGIR 2024, where different relevance assessment approaches were proposed. In detail, we release and benchmark 42 LLM-generated labels of the TREC 2023 Deep Learning track relevance judgments produced by eight international teams who participated in the challenge. Given their diverse nature, these automatically generated relevance judgments can help the community not only investigate systematic biases caused by LLMs but also explore the effectiveness of ensemble models, analyze the trade-offs between different models and human assessors, and advance methodologies for improving automated evaluation techniques. The released resource is available at the following link: https://llm4eval.github.io/LLMJudge-benchmark/
LLM-based relevance assessment still can't replace human relevance assessment
Dec 22, 2024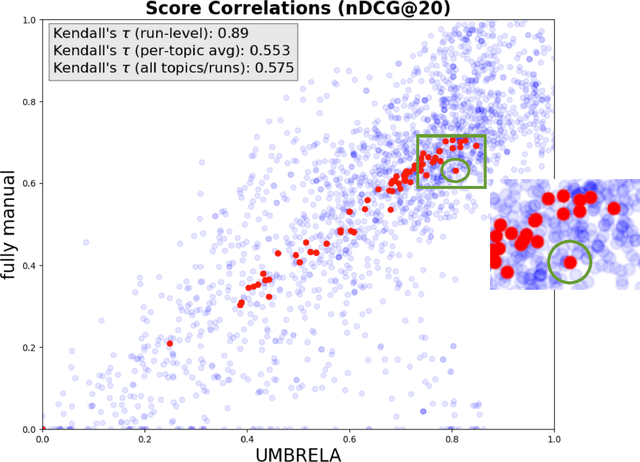
The use of large language models (LLMs) for relevance assessment in information retrieval has gained significant attention, with recent studies suggesting that LLM-based judgments provide comparable evaluations to human judgments. Notably, based on TREC 2024 data, Upadhyay et al. make a bold claim that LLM-based relevance assessments, such as those generated by the UMBRELA system, can fully replace traditional human relevance assessments in TREC-style evaluations. This paper critically examines this claim, highlighting practical and theoretical limitations that undermine the validity of this conclusion. First, we question whether the evidence provided by Upadhyay et al. really supports their claim, particularly if a test collection is used asa benchmark for future improvements. Second, through a submission deliberately intended to do so, we demonstrate the ease with which automatic evaluation metrics can be subverted, showing that systems designed to exploit these evaluations can achieve artificially high scores. Theoretical challenges -- such as the inherent narcissism of LLMs, the risk of overfitting to LLM-based metrics, and the potential degradation of future LLM performance -- must be addressed before LLM-based relevance assessments can be considered a viable replacement for human judgments.
EMPRA: Embedding Perturbation Rank Attack against Neural Ranking Models
Dec 20, 2024



Recent research has shown that neural information retrieval techniques may be susceptible to adversarial attacks. Adversarial attacks seek to manipulate the ranking of documents, with the intention of exposing users to targeted content. In this paper, we introduce the Embedding Perturbation Rank Attack (EMPRA) method, a novel approach designed to perform adversarial attacks on black-box Neural Ranking Models (NRMs). EMPRA manipulates sentence-level embeddings, guiding them towards pertinent context related to the query while preserving semantic integrity. This process generates adversarial texts that seamlessly integrate with the original content and remain imperceptible to humans. Our extensive evaluation conducted on the widely-used MS MARCO V1 passage collection demonstrate the effectiveness of EMPRA against a wide range of state-of-the-art baselines in promoting a specific set of target documents within a given ranked results. Specifically, EMPRA successfully achieves a re-ranking of almost 96% of target documents originally ranked between 51-100 to rank within the top 10. Furthermore, EMPRA does not depend on surrogate models for adversarial text generation, enhancing its robustness against different NRMs in realistic settings.
Annotative Indexing
Nov 20, 2024


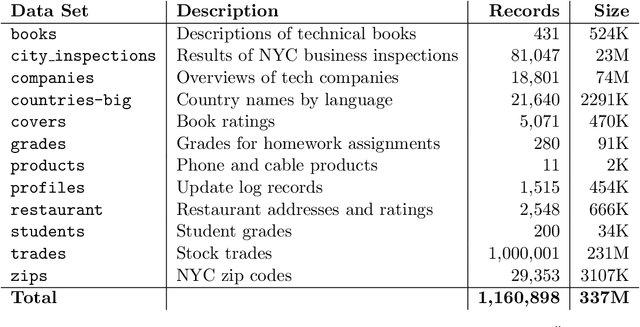
This paper introduces annotative indexing, a novel framework that unifies and generalizes traditional inverted indexes, column stores, object stores, and graph databases. As a result, annotative indexing can provide the underlying indexing framework for databases that support knowledge graphs, entity retrieval, semi-structured data, and ranked retrieval. While we primarily focus on human language data in the form of text, annotative indexing is sufficiently general to support a range of other datatypes, and we provide examples of SQL-like queries over a JSON store that includes numbers and dates. Taking advantage of the flexibility of annotative indexing, we also demonstrate a fully dynamic annotative index incorporating support for ACID properties of transactions with hundreds of multiple concurrent readers and writers.