 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterplay: Training Independent Simulators for Reference-Free Conversational Recommendation
Mar 19, 2026Training conversational recommender systems (CRS) requires extensive dialogue data, which is challenging to collect at scale. To address this, researchers have used simulated user-recommender conversations. Traditional simulation approaches often utilize a single large language model (LLM) that generates entire conversations with prior knowledge of the target items, leading to scripted and artificial dialogues. We propose a reference-free simulation framework that trains two independent LLMs, one as the user and one as the conversational recommender. These models interact in real-time without access to predetermined target items, but preference summaries and target attributes, enabling the recommender to genuinely infer user preferences through dialogue. This approach produces more realistic and diverse conversations that closely mirror authentic human-AI interactions. Our reference-free simulators match or exceed existing methods in quality, while offering a scalable solution for generating high-quality conversational recommendation data without constraining conversations to pre-defined target items. We conduct both quantitative and human evaluations to confirm the effectiveness of our reference-free approach.
When AI Benchmarks Plateau: A Systematic Study of Benchmark Saturation
Feb 18, 2026Artificial Intelligence (AI) benchmarks play a central role in measuring progress in model development and guiding deployment decisions. However, many benchmarks quickly become saturated, meaning that they can no longer differentiate between the best-performing models, diminishing their long-term value. In this study, we analyze benchmark saturation across 60 Large Language Model (LLM) benchmarks selected from technical reports by major model developers. To identify factors driving saturation, we characterize benchmarks along 14 properties spanning task design, data construction, and evaluation format. We test five hypotheses examining how each property contributes to saturation rates. Our analysis reveals that nearly half of the benchmarks exhibit saturation, with rates increasing as benchmarks age. Notably, hiding test data (i.e., public vs. private) shows no protective effect, while expert-curated benchmarks resist saturation better than crowdsourced ones. Our findings highlight which design choices extend benchmark longevity and inform strategies for more durable evaluation.
InnoEval: On Research Idea Evaluation as a Knowledge-Grounded, Multi-Perspective Reasoning Problem
Feb 16, 2026The rapid evolution of Large Language Models has catalyzed a surge in scientific idea production, yet this leap has not been accompanied by a matching advance in idea evaluation. The fundamental nature of scientific evaluation needs knowledgeable grounding, collective deliberation, and multi-criteria decision-making. However, existing idea evaluation methods often suffer from narrow knowledge horizons, flattened evaluation dimensions, and the inherent bias in LLM-as-a-Judge. To address these, we regard idea evaluation as a knowledge-grounded, multi-perspective reasoning problem and introduce InnoEval, a deep innovation evaluation framework designed to emulate human-level idea assessment. We apply a heterogeneous deep knowledge search engine that retrieves and grounds dynamic evidence from diverse online sources. We further achieve review consensus with an innovation review board containing reviewers with distinct academic backgrounds, enabling a multi-dimensional decoupled evaluation across multiple metrics. We construct comprehensive datasets derived from authoritative peer-reviewed submissions to benchmark InnoEval. Experiments demonstrate that InnoEval can consistently outperform baselines in point-wise, pair-wise, and group-wise evaluation tasks, exhibiting judgment patterns and consensus highly aligned with human experts.
Beyond Output Critique: Self-Correction via Task Distillation
Jan 31, 2026Large language models (LLMs) have shown promising self-correction abilities, where iterative refinement improves the quality of generated responses. However, most existing approaches operate at the level of output critique, patching surface errors while often failing to correct deeper reasoning flaws. We propose SELF-THOUGHT, a framework that introduces an intermediate step of task abstraction before solution refinement. Given an input and an initial response, the model first distills the task into a structured template that captures key variables, constraints, and problem structure. This abstraction then guides solution instantiation, grounding subsequent responses in a clearer understanding of the task and reducing error propagation. Crucially, we show that these abstractions can be transferred across models: templates generated by larger models can serve as structured guides for smaller LLMs, which typically struggle with intrinsic self-correction. By reusing distilled task structures, smaller models achieve more reliable refinements without heavy fine-tuning or reliance on external verifiers. Experiments across diverse reasoning tasks demonstrate that SELF-THOUGHT improves accuracy, robustness, and generalization for both large and small models, offering a scalable path toward more reliable self-correcting language systems.
Automated Rubrics for Reliable Evaluation of Medical Dialogue Systems
Jan 21, 2026Large Language Models (LLMs) are increasingly used for clinical decision support, where hallucinations and unsafe suggestions may pose direct risks to patient safety. These risks are particularly challenging as they often manifest as subtle clinical errors that evade detection by generic metrics, while expert-authored fine-grained rubrics remain costly to construct and difficult to scale. In this paper, we propose a retrieval-augmented multi-agent framework designed to automate the generation of instance-specific evaluation rubrics. Our approach grounds evaluation in authoritative medical evidence by decomposing retrieved content into atomic facts and synthesizing them with user interaction constraints to form verifiable, fine-grained evaluation criteria. Evaluated on HealthBench, our framework achieves a Clinical Intent Alignment (CIA) score of 60.12%, a statistically significant improvement over the GPT-4o baseline (55.16%). In discriminative tests, our rubrics yield a mean score delta ($μ_Δ = 8.658$) and an AUROC of 0.977, nearly doubling the quality separation achieved by GPT-4o baseline (4.972). Beyond evaluation, our rubrics effectively guide response refinement, improving quality by 9.2% (from 59.0% to 68.2%). This provides a scalable and transparent foundation for both evaluating and improving medical LLMs. The code is available at https://anonymous.4open.science/r/Automated-Rubric-Generation-AF3C/.
Self-Correcting Large Language Models: Generation vs. Multiple Choice
Nov 12, 2025Large language models have recently demonstrated remarkable abilities to self-correct their responses through iterative refinement, often referred to as self-consistency or self-reflection. However, the dynamics of this self-correction mechanism may differ substantially depending on whether the model is tasked with open-ended text generation or with selecting the most appropriate response from multiple predefined options. In this paper, we conduct a systematic investigation of these two paradigms by comparing performance trends and error-correction behaviors across various natural language understanding and reasoning tasks, covering language models of different scales and families. Our experimental results reveal distinct patterns of improvement and failure modes: \textit{While open-ended generation often benefits from the flexibility of re-interpretation and compositional refinement, multiple-choice selection can leverage clearer solution boundaries but may be limited by the provided options}. This contrast also reflects the dual demands faced by emerging agentic LLM applications: effective agents must not only generate and refine open-ended plans or explanations, but also make reliable discrete choices when operating within constrained action spaces. Our findings, therefore, highlight that the design of self-correction mechanisms should take into account the interaction between task structure and output space, with implications for both knowledge-intensive reasoning and decision-oriented applications of LLMs.
Who Evaluates AI's Social Impacts? Mapping Coverage and Gaps in First and Third Party Evaluations
Nov 06, 2025



Foundation models are increasingly central to high-stakes AI systems, and governance frameworks now depend on evaluations to assess their risks and capabilities. Although general capability evaluations are widespread, social impact assessments covering bias, fairness, privacy, environmental costs, and labor practices remain uneven across the AI ecosystem. To characterize this landscape, we conduct the first comprehensive analysis of both first-party and third-party social impact evaluation reporting across a wide range of model developers. Our study examines 186 first-party release reports and 183 post-release evaluation sources, and complements this quantitative analysis with interviews of model developers. We find a clear division of evaluation labor: first-party reporting is sparse, often superficial, and has declined over time in key areas such as environmental impact and bias, while third-party evaluators including academic researchers, nonprofits, and independent organizations provide broader and more rigorous coverage of bias, harmful content, and performance disparities. However, this complementarity has limits. Only model developers can authoritatively report on data provenance, content moderation labor, financial costs, and training infrastructure, yet interviews reveal that these disclosures are often deprioritized unless tied to product adoption or regulatory compliance. Our findings indicate that current evaluation practices leave major gaps in assessing AI's societal impacts, highlighting the urgent need for policies that promote developer transparency, strengthen independent evaluation ecosystems, and create shared infrastructure to aggregate and compare third-party evaluations in a consistent and accessible way.
AgentCoMa: A Compositional Benchmark Mixing Commonsense and Mathematical Reasoning in Real-World Scenarios
Aug 27, 2025Large Language Models (LLMs) have achieved high accuracy on complex commonsense and mathematical problems that involve the composition of multiple reasoning steps. However, current compositional benchmarks testing these skills tend to focus on either commonsense or math reasoning, whereas LLM agents solving real-world tasks would require a combination of both. In this work, we introduce an Agentic Commonsense and Math benchmark (AgentCoMa), where each compositional task requires a commonsense reasoning step and a math reasoning step. We test it on 61 LLMs of different sizes, model families, and training strategies. We find that LLMs can usually solve both steps in isolation, yet their accuracy drops by ~30% on average when the two are combined. This is a substantially greater performance gap than the one we observe in prior compositional benchmarks that combine multiple steps of the same reasoning type. In contrast, non-expert human annotators can solve the compositional questions and the individual steps in AgentCoMa with similarly high accuracy. Furthermore, we conduct a series of interpretability studies to better understand the performance gap, examining neuron patterns, attention maps and membership inference. Our work underscores a substantial degree of model brittleness in the context of mixed-type compositional reasoning and offers a test bed for future improvement.
Towards Understanding Bias in Synthetic Data for Evaluation
Jun 12, 2025Test collections are crucial for evaluating Information Retrieval (IR) systems. Creating a diverse set of user queries for these collections can be challenging, and obtaining relevance judgments, which indicate how well retrieved documents match a query, is often costly and resource-intensive. Recently, generating synthetic datasets using Large Language Models (LLMs) has gained attention in various applications. While previous work has used LLMs to generate synthetic queries or documents to improve ranking models, using LLMs to create synthetic test collections is still relatively unexplored. Previous work~\cite{rahmani2024synthetic} showed that synthetic test collections have the potential to be used for system evaluation, however, more analysis is needed to validate this claim. In this paper, we thoroughly investigate the reliability of synthetic test collections constructed using LLMs, where LLMs are used to generate synthetic queries, labels, or both. In particular, we examine the potential biases that might occur when such test collections are used for evaluation. We first empirically show the presence of such bias in evaluation results and analyse the effects it might have on system evaluation. We further validate the presence of such bias using a linear mixed-effects model. Our analysis shows that while the effect of bias present in evaluation results obtained using synthetic test collections could be significant, for e.g.~computing absolute system performance, its effect may not be as significant in comparing relative system performance. Codes and data are available at: https://github.com/rahmanidashti/BiasSyntheticData.
Judging the Judges: A Collection of LLM-Generated Relevance Judgements
Feb 19, 2025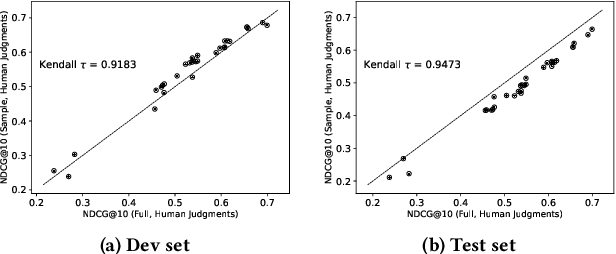
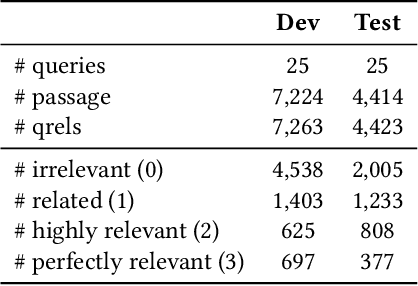
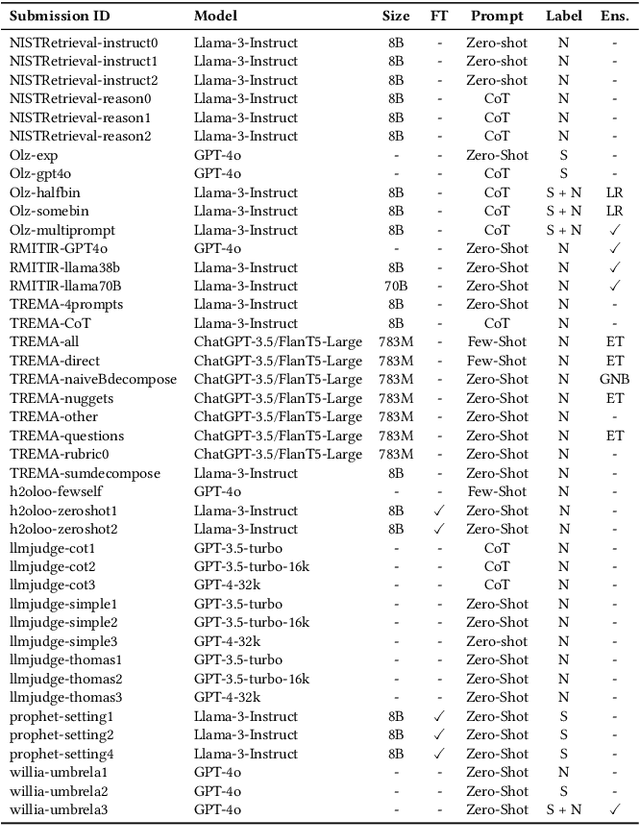
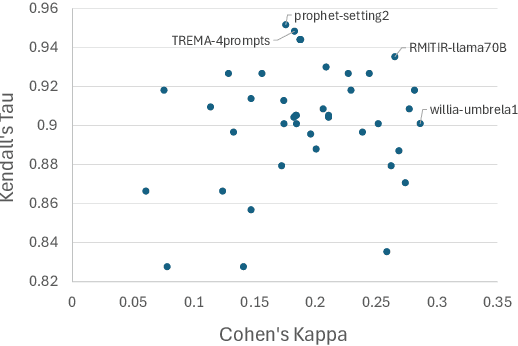
Using Large Language Models (LLMs) for relevance assessments offers promising opportunities to improve Information Retrieval (IR), Natural Language Processing (NLP), and related fields. Indeed, LLMs hold the promise of allowing IR experimenters to build evaluation collections with a fraction of the manual human labor currently required. This could help with fresh topics on which there is still limited knowledge and could mitigate the challenges of evaluating ranking systems in low-resource scenarios, where it is challenging to find human annotators. Given the fast-paced recent developments in the domain, many questions concerning LLMs as assessors are yet to be answered. Among the aspects that require further investigation, we can list the impact of various components in a relevance judgment generation pipeline, such as the prompt used or the LLM chosen. This paper benchmarks and reports on the results of a large-scale automatic relevance judgment evaluation, the LLMJudge challenge at SIGIR 2024, where different relevance assessment approaches were proposed. In detail, we release and benchmark 42 LLM-generated labels of the TREC 2023 Deep Learning track relevance judgments produced by eight international teams who participated in the challenge. Given their diverse nature, these automatically generated relevance judgments can help the community not only investigate systematic biases caused by LLMs but also explore the effectiveness of ensemble models, analyze the trade-offs between different models and human assessors, and advance methodologies for improving automated evaluation techniques. The released resource is available at the following link: https://llm4eval.github.io/LLMJudge-benchmark/