 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual and Domain-Agnostic Tip-of-the-Tongue Query Generation for Simulated Evaluation
Apr 22, 2026Tip-of-the-Tongue (ToT) retrieval benchmarks have largely focused on English, limiting their applicability to multilingual information access. In this work, we construct multilingual ToT test collections for Chinese, Japanese, Korean, and English, using an LLM-based query simulation framework. We systematically study how prompt language and source document language affect the fidelity of simulated ToT queries, validating synthetic queries through system rank correlation against real user queries. Our results show that effective ToT simulation requires language-aware design choices: non-English language sources are generally important, while English Wikipedia can be beneficial when non-English sources provide insufficient information for query generation. Based on these findings, we release four ToT test collections with 5,000 queries per language across multiple domains. This work provides the first large-scale multilingual ToT benchmark and offers practical guidance for constructing realistic ToT datasets beyond English.
Open, to What End? A Capability-Theoretic Perspective on Open Search
Mar 15, 2026The hegemony of control over our search platforms by a few large corporations raises justifiable concerns, particularly in light of emerging geopolitical tensions and growing instances of ideological imposition by authoritarian actors to manipulate public opinion. Recent movement for promote open search has emerged in response. This follows from past and ongoing push for openness to challenge corporate oligopolies (e.g., open source and open AI models) which have seen significant ongoing negotiations and renegotiations to establish standards around what constitutes being open. These tensions have hindered these movements from effectively challenging power, in turn allowing powerful corporations to neutralize or co-opt these movements to further entrench their dominance. We argue that the push for open search will inevitably encounter similar conflicts, and should foreground these tensions to safefguard against similar challenges as these adjacent movements. In particular, we argue that the concept of open should be understood not with respect to what is being made open but through a capability-theoretic lens, in terms of the capabilities it affords to the actors the system is being opened to.
From Noise to Order: Learning to Rank via Denoising Diffusion
Feb 12, 2026In information retrieval (IR), learning-to-rank (LTR) methods have traditionally limited themselves to discriminative machine learning approaches that model the probability of the document being relevant to the query given some feature representation of the query-document pair. In this work, we propose an alternative denoising diffusion-based deep generative approach to LTR that instead models the full joint distribution over feature vectors and relevance labels. While in the discriminative setting, an over-parameterized ranking model may find different ways to fit the training data, we hypothesize that candidate solutions that can explain the full data distribution under the generative setting produce more robust ranking models. With this motivation, we propose DiffusionRank that extends TabDiff, an existing denoising diffusion-based generative model for tabular datasets, to create generative equivalents of classical discriminative pointwise and pairwise LTR objectives. Our empirical results demonstrate significant improvements from DiffusionRank models over their discriminative counterparts. Our work points to a rich space for future research exploration on how we can leverage ongoing advancements in deep generative modeling approaches, such as diffusion, for learning-to-rank in IR.
Overview of the TREC 2025 Tip-of-the-Tongue track
Jan 28, 2026Tip-of-the-tongue (ToT) known-item retrieval involves re-finding an item for which the searcher does not reliably recall an identifier. ToT information requests (or queries) are verbose and tend to include several complex phenomena, making them especially difficult for existing information retrieval systems. The TREC 2025 ToT track focused on a single ad-hoc retrieval task. This year, we extended the track to general domain and incorporated different sets of test queries from diverse sources, namely from the MS-ToT dataset, manual topic development, and LLM-based synthetic query generation. This year, 9 groups (including the track coordinators) submitted 32 runs.
Information Access of the Oppressed: A Problem-Posing Framework for Envisioning Emancipatory Information Access Platforms
Jan 14, 2026Online information access (IA) platforms are targets of authoritarian capture. These concerns are particularly serious and urgent today in light of the rising levels of democratic erosion worldwide, the emerging capabilities of generative AI technologies such as AI persuasion, and the increasing concentration of economic and political power in the hands of Big Tech. This raises the question of what alternative IA infrastructure we must reimagine and build to mitigate the risks of authoritarian capture of our information ecosystems. We explore this question through the lens of Paulo Freire's theories of emancipatory pedagogy. Freire's theories provide a radically different lens for exploring IA's sociotechnical concerns relative to the current dominating frames of fairness, accountability, confidentiality, transparency, and safety. We make explicit, with the intention to challenge, the dichotomy of how we relate to technology as either technologists (who envision and build technology) and its users. We posit that this mirrors the teacher-student relationship in Freire's analysis. By extending Freire's analysis to IA, we challenge the notion that it is the burden of the (altruistic) technologists to come up with interventions to mitigate the risks that emerging technologies pose to marginalized communities. Instead, we advocate that the first task for the technologists is to pose these as problems to the marginalized communities, to encourage them to make and unmake the technology as part of their material struggle against oppression. Their second task is to redesign our online technology stacks to structurally expose spaces for community members to co-opt and co-construct the technology in aid of their emancipatory struggles. We operationalize Freire's theories to develop a problem-posing framework for envisioning emancipatory IA platforms of the future.
Towards Understanding Bias in Synthetic Data for Evaluation
Jun 12, 2025Test collections are crucial for evaluating Information Retrieval (IR) systems. Creating a diverse set of user queries for these collections can be challenging, and obtaining relevance judgments, which indicate how well retrieved documents match a query, is often costly and resource-intensive. Recently, generating synthetic datasets using Large Language Models (LLMs) has gained attention in various applications. While previous work has used LLMs to generate synthetic queries or documents to improve ranking models, using LLMs to create synthetic test collections is still relatively unexplored. Previous work~\cite{rahmani2024synthetic} showed that synthetic test collections have the potential to be used for system evaluation, however, more analysis is needed to validate this claim. In this paper, we thoroughly investigate the reliability of synthetic test collections constructed using LLMs, where LLMs are used to generate synthetic queries, labels, or both. In particular, we examine the potential biases that might occur when such test collections are used for evaluation. We first empirically show the presence of such bias in evaluation results and analyse the effects it might have on system evaluation. We further validate the presence of such bias using a linear mixed-effects model. Our analysis shows that while the effect of bias present in evaluation results obtained using synthetic test collections could be significant, for e.g.~computing absolute system performance, its effect may not be as significant in comparing relative system performance. Codes and data are available at: https://github.com/rahmanidashti/BiasSyntheticData.
Tip of the Tongue Query Elicitation for Simulated Evaluation
Feb 25, 2025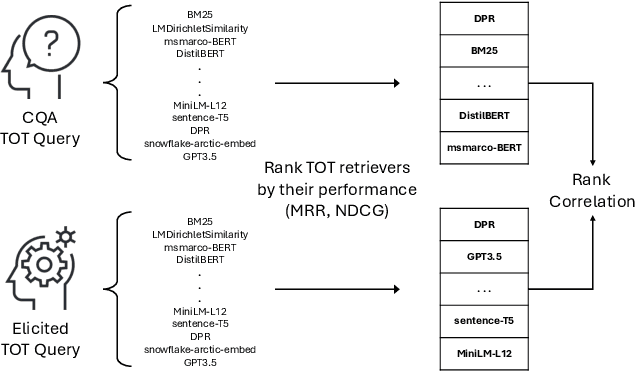
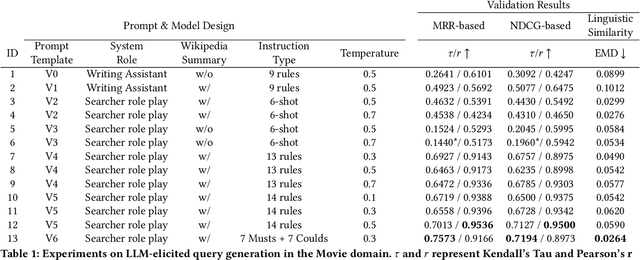
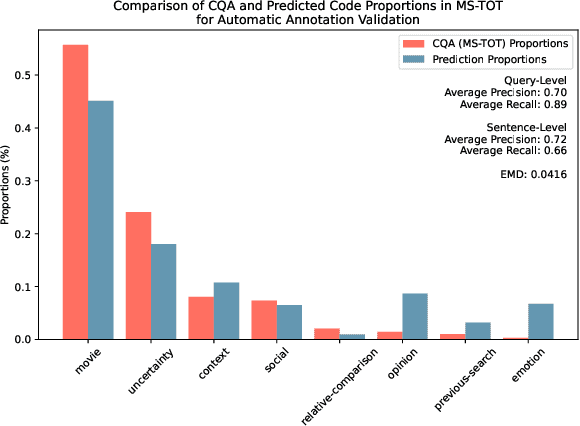

Tip-of-the-tongue (TOT) search occurs when a user struggles to recall a specific identifier, such as a document title. While common, existing search systems often fail to effectively support TOT scenarios. Research on TOT retrieval is further constrained by the challenge of collecting queries, as current approaches rely heavily on community question-answering (CQA) websites, leading to labor-intensive evaluation and domain bias. To overcome these limitations, we introduce two methods for eliciting TOT queries - leveraging large language models (LLMs) and human participants - to facilitate simulated evaluations of TOT retrieval systems. Our LLM-based TOT user simulator generates synthetic TOT queries at scale, achieving high correlations with how CQA-based TOT queries rank TOT retrieval systems when tested in the Movie domain. Additionally, these synthetic queries exhibit high linguistic similarity to CQA-derived queries. For human-elicited queries, we developed an interface that uses visual stimuli to place participants in a TOT state, enabling the collection of natural queries. In the Movie domain, system rank correlation and linguistic similarity analyses confirm that human-elicited queries are both effective and closely resemble CQA-based queries. These approaches reduce reliance on CQA-based data collection while expanding coverage to underrepresented domains, such as Landmark and Person. LLM-elicited queries for the Movie, Landmark, and Person domains have been released as test queries in the TREC 2024 TOT track, with human-elicited queries scheduled for inclusion in the TREC 2025 TOT track. Additionally, we provide source code for synthetic query generation and the human query collection interface, along with curated visual stimuli used for eliciting TOT queries.
Judging the Judges: A Collection of LLM-Generated Relevance Judgements
Feb 19, 2025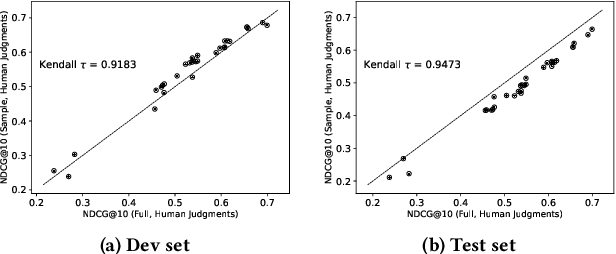
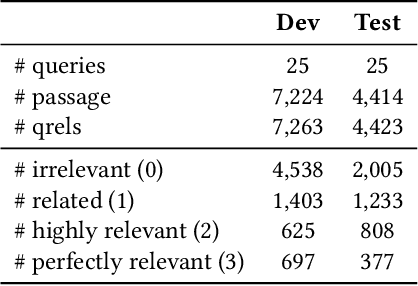
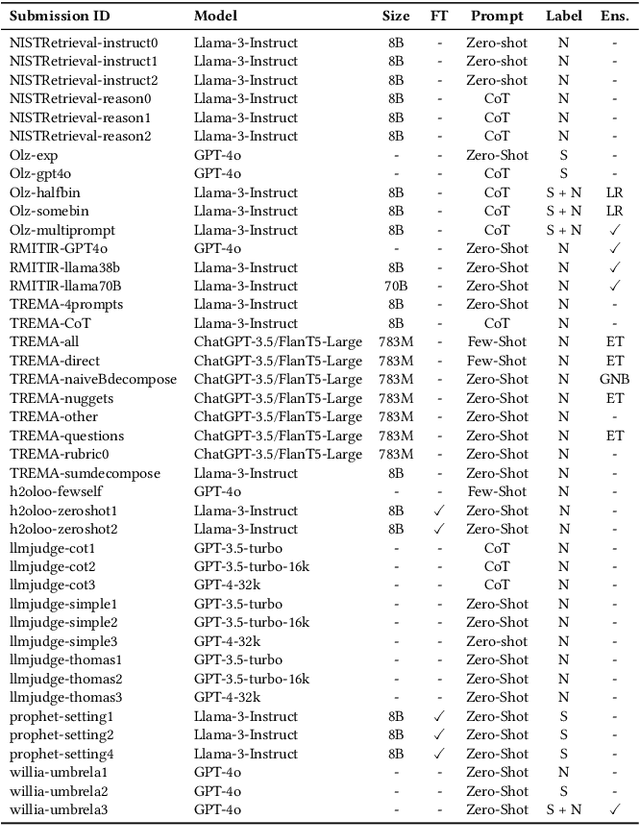
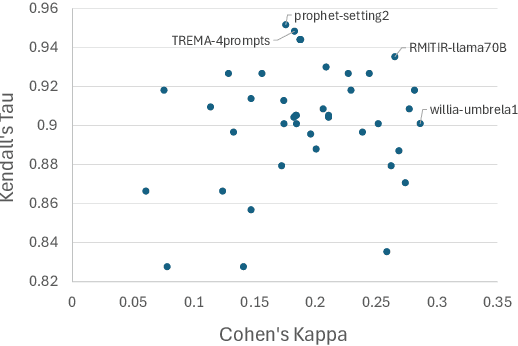
Using Large Language Models (LLMs) for relevance assessments offers promising opportunities to improve Information Retrieval (IR), Natural Language Processing (NLP), and related fields. Indeed, LLMs hold the promise of allowing IR experimenters to build evaluation collections with a fraction of the manual human labor currently required. This could help with fresh topics on which there is still limited knowledge and could mitigate the challenges of evaluating ranking systems in low-resource scenarios, where it is challenging to find human annotators. Given the fast-paced recent developments in the domain, many questions concerning LLMs as assessors are yet to be answered. Among the aspects that require further investigation, we can list the impact of various components in a relevance judgment generation pipeline, such as the prompt used or the LLM chosen. This paper benchmarks and reports on the results of a large-scale automatic relevance judgment evaluation, the LLMJudge challenge at SIGIR 2024, where different relevance assessment approaches were proposed. In detail, we release and benchmark 42 LLM-generated labels of the TREC 2023 Deep Learning track relevance judgments produced by eight international teams who participated in the challenge. Given their diverse nature, these automatically generated relevance judgments can help the community not only investigate systematic biases caused by LLMs but also explore the effectiveness of ensemble models, analyze the trade-offs between different models and human assessors, and advance methodologies for improving automated evaluation techniques. The released resource is available at the following link: https://llm4eval.github.io/LLMJudge-benchmark/
Emancipatory Information Retrieval
Jan 31, 2025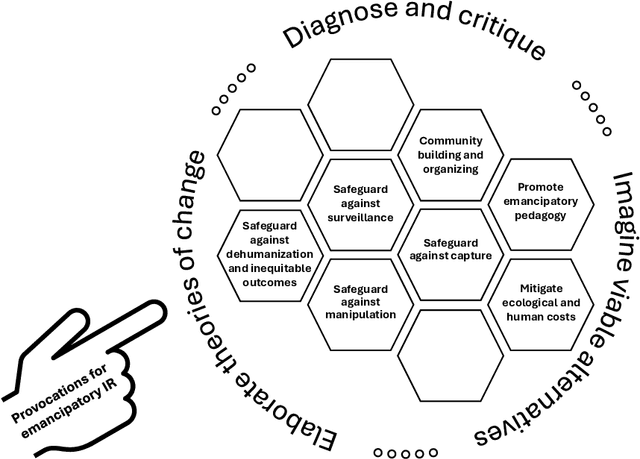
Our world today is facing a confluence of several mutually reinforcing crises each of which intersects with concerns of social justice and emancipation. This paper is a provocation for the role of computer-mediated information access in our emancipatory struggles. We define emancipatory information retrieval as the study and development of information access methods that challenge various forms of human oppression, and situates its activities within broader collective emancipatory praxis. The term "emancipatory" here signifies the moral concerns of universal humanization of all peoples and the elimination of oppression to create the conditions under which we can collectively flourish. To develop an emancipatory research agenda for IR, in this paper we speculate about the practices that the community can adopt, enumerate some of the projects that the field should undertake, and discuss provocations to spark new ideas and directions for research. We challenge the field of information retrieval (IR) research to embrace humanistic values and commit to universal emancipation and social justice as part of our research.
JudgeBlender: Ensembling Judgments for Automatic Relevance Assessment
Dec 17, 2024



The effective training and evaluation of retrieval systems require a substantial amount of relevance judgments, which are traditionally collected from human assessors -- a process that is both costly and time-consuming. Large Language Models (LLMs) have shown promise in generating relevance labels for search tasks, offering a potential alternative to manual assessments. Current approaches often rely on a single LLM, such as GPT-4, which, despite being effective, are expensive and prone to intra-model biases that can favour systems leveraging similar models. In this work, we introduce JudgeBlender, a framework that employs smaller, open-source models to provide relevance judgments by combining evaluations across multiple LLMs (LLMBlender) or multiple prompts (PromptBlender). By leveraging the LLMJudge benchmark [18], we compare JudgeBlender with state-of-the-art methods and the top performers in the LLMJudge challenge. Our results show that JudgeBlender achieves competitive performance, demonstrating that very large models are often unnecessary for reliable relevance assessments.