 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariations in Relevance Judgments and the Shelf Life of Test Collections
Feb 28, 2025The fundamental property of Cranfield-style evaluations, that system rankings are stable even when assessors disagree on individual relevance decisions, was validated on traditional test collections. However, the paradigm shift towards neural retrieval models affected the characteristics of modern test collections, e.g., documents are short, judged with four grades of relevance, and information needs have no descriptions or narratives. Under these changes, it is unclear whether assessor disagreement remains negligible for system comparisons. We investigate this aspect under the additional condition that the few modern test collections are heavily re-used. Given more possible query interpretations due to less formalized information needs, an ''expiration date'' for test collections might be needed if top-effectiveness requires overfitting to a single interpretation of relevance. We run a reproducibility study and re-annotate the relevance judgments of the 2019 TREC Deep Learning track. We can reproduce prior work in the neural retrieval setting, showing that assessor disagreement does not affect system rankings. However, we observe that some models substantially degrade with our new relevance judgments, and some have already reached the effectiveness of humans as rankers, providing evidence that test collections can expire.
Judging the Judges: A Collection of LLM-Generated Relevance Judgements
Feb 19, 2025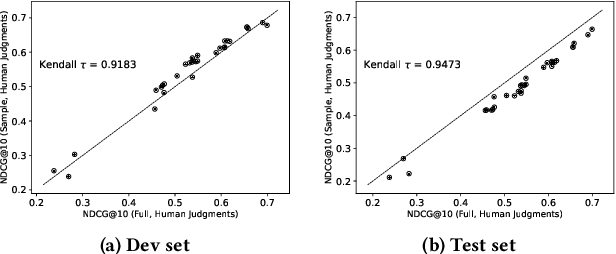
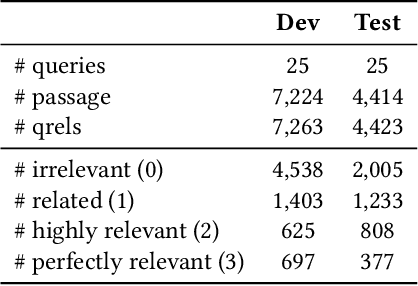
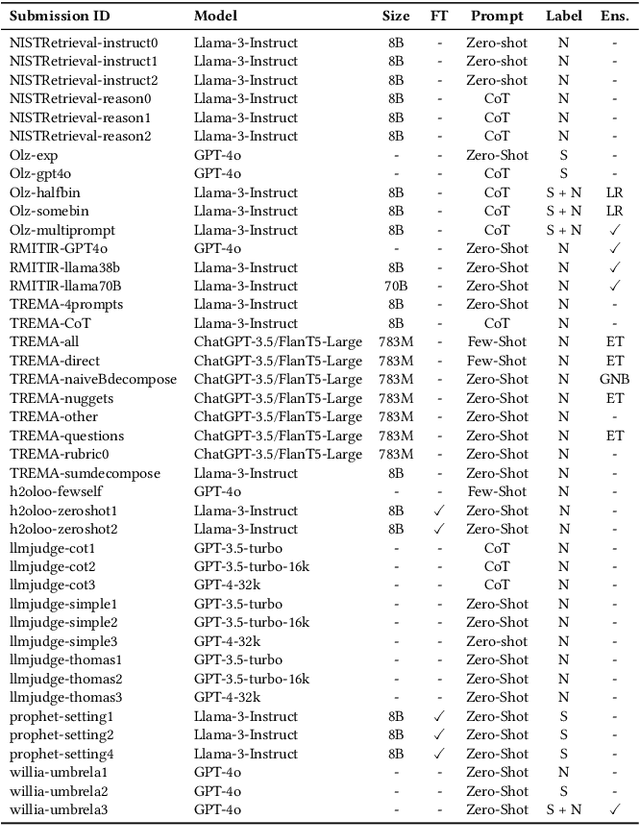
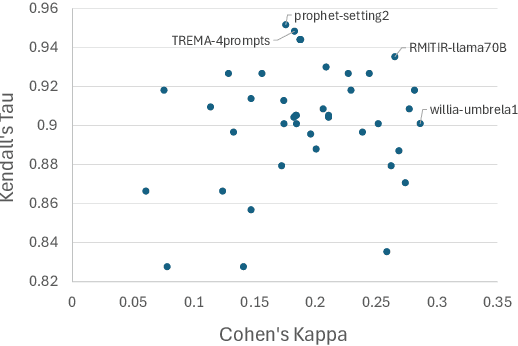
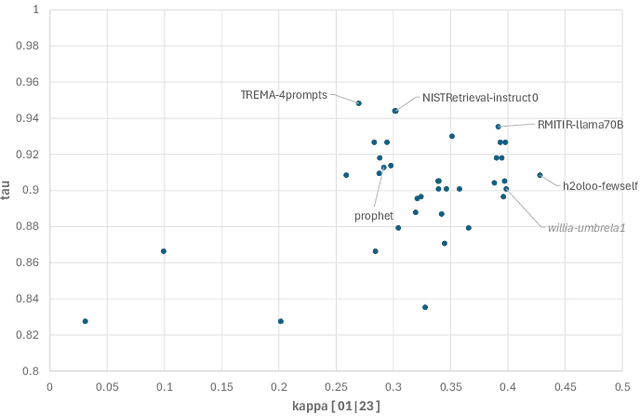
Using Large Language Models (LLMs) for relevance assessments offers promising opportunities to improve Information Retrieval (IR), Natural Language Processing (NLP), and related fields. Indeed, LLMs hold the promise of allowing IR experimenters to build evaluation collections with a fraction of the manual human labor currently required. This could help with fresh topics on which there is still limited knowledge and could mitigate the challenges of evaluating ranking systems in low-resource scenarios, where it is challenging to find human annotators. Given the fast-paced recent developments in the domain, many questions concerning LLMs as assessors are yet to be answered. Among the aspects that require further investigation, we can list the impact of various components in a relevance judgment generation pipeline, such as the prompt used or the LLM chosen. This paper benchmarks and reports on the results of a large-scale automatic relevance judgment evaluation, the LLMJudge challenge at SIGIR 2024, where different relevance assessment approaches were proposed. In detail, we release and benchmark 42 LLM-generated labels of the TREC 2023 Deep Learning track relevance judgments produced by eight international teams who participated in the challenge. Given their diverse nature, these automatically generated relevance judgments can help the community not only investigate systematic biases caused by LLMs but also explore the effectiveness of ensemble models, analyze the trade-offs between different models and human assessors, and advance methodologies for improving automated evaluation techniques. The released resource is available at the following link: https://llm4eval.github.io/LLMJudge-benchmark/
LLMJudge: LLMs for Relevance Judgments
Aug 09, 2024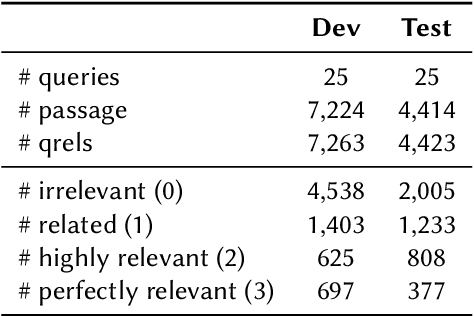
The LLMJudge challenge is organized as part of the LLM4Eval workshop at SIGIR 2024. Test collections are essential for evaluating information retrieval (IR) systems. The evaluation and tuning of a search system is largely based on relevance labels, which indicate whether a document is useful for a specific search and user. However, collecting relevance judgments on a large scale is costly and resource-intensive. Consequently, typical experiments rely on third-party labelers who may not always produce accurate annotations. The LLMJudge challenge aims to explore an alternative approach by using LLMs to generate relevance judgments. Recent studies have shown that LLMs can generate reliable relevance judgments for search systems. However, it remains unclear which LLMs can match the accuracy of human labelers, which prompts are most effective, how fine-tuned open-source LLMs compare to closed-source LLMs like GPT-4, whether there are biases in synthetically generated data, and if data leakage affects the quality of generated labels. This challenge will investigate these questions, and the collected data will be released as a package to support automatic relevance judgment research in information retrieval and search.
Report on the 1st Workshop on Large Language Model for Evaluation in Information Retrieval (LLM4Eval 2024) at SIGIR 2024
Aug 09, 2024
The first edition of the workshop on Large Language Model for Evaluation in Information Retrieval (LLM4Eval 2024) took place in July 2024, co-located with the ACM SIGIR Conference 2024 in the USA (SIGIR 2024). The aim was to bring information retrieval researchers together around the topic of LLMs for evaluation in information retrieval that gathered attention with the advancement of large language models and generative AI. Given the novelty of the topic, the workshop was focused around multi-sided discussions, namely panels and poster sessions of the accepted proceedings papers.
Words Blending Boxes. Obfuscating Queries in Information Retrieval using Differential Privacy
May 15, 2024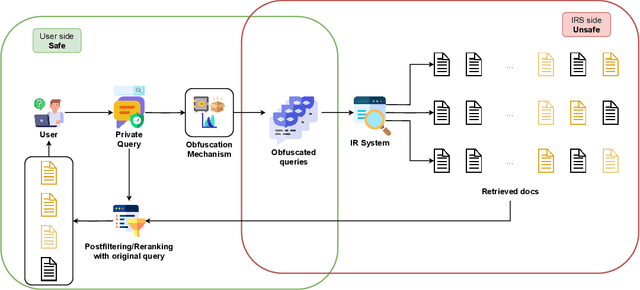
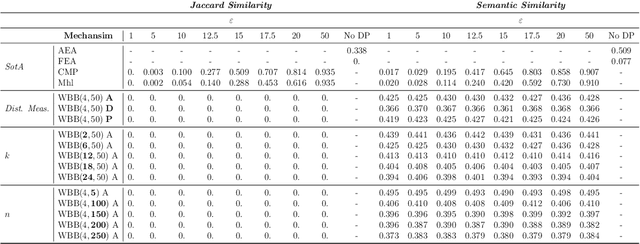
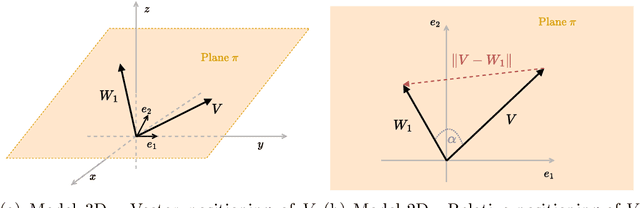
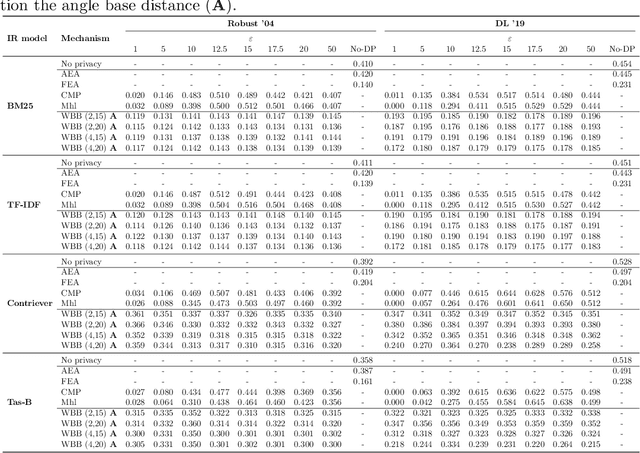
Ensuring the effectiveness of search queries while protecting user privacy remains an open issue. When an Information Retrieval System (IRS) does not protect the privacy of its users, sensitive information may be disclosed through the queries sent to the system. Recent improvements, especially in NLP, have shown the potential of using Differential Privacy to obfuscate texts while maintaining satisfactory effectiveness. However, such approaches may protect the user's privacy only from a theoretical perspective while, in practice, the real user's information need can still be inferred if perturbed terms are too semantically similar to the original ones. We overcome such limitations by proposing Word Blending Boxes, a novel differentially private mechanism for query obfuscation, which protects the words in the user queries by employing safe boxes. To measure the overall effectiveness of the proposed WBB mechanism, we measure the privacy obtained by the obfuscation process, i.e., the lexical and semantic similarity between original and obfuscated queries. Moreover, we assess the effectiveness of the privatized queries in retrieving relevant documents from the IRS. Our findings indicate that WBB can be integrated effectively into existing IRSs, offering a key to the challenge of protecting user privacy from both a theoretical and a practical point of view.
Perspectives on Large Language Models for Relevance Judgment
Apr 13, 2023
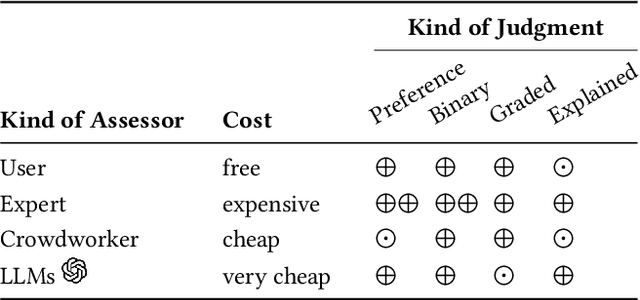

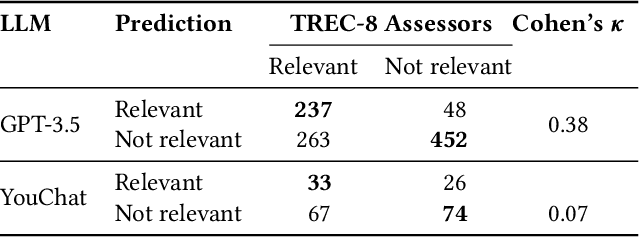
When asked, current large language models (LLMs) like ChatGPT claim that they can assist us with relevance judgments. Many researchers think this would not lead to credible IR research. In this perspective paper, we discuss possible ways for LLMs to assist human experts along with concerns and issues that arise. We devise a human-machine collaboration spectrum that allows categorizing different relevance judgment strategies, based on how much the human relies on the machine. For the extreme point of "fully automated assessment", we further include a pilot experiment on whether LLM-based relevance judgments correlate with judgments from trained human assessors. We conclude the paper by providing two opposing perspectives - for and against the use of LLMs for automatic relevance judgments - and a compromise perspective, informed by our analyses of the literature, our preliminary experimental evidence, and our experience as IR researchers. We hope to start a constructive discussion within the community to avoid a stale-mate during review, where work is dammed if is uses LLMs for evaluation and dammed if it doesn't.
Query Performance Prediction for Neural IR: Are We There Yet?
Feb 20, 2023Evaluation in Information Retrieval relies on post-hoc empirical procedures, which are time-consuming and expensive operations. To alleviate this, Query Performance Prediction (QPP) models have been developed to estimate the performance of a system without the need for human-made relevance judgements. Such models, usually relying on lexical features from queries and corpora, have been applied to traditional sparse IR methods - with various degrees of success. With the advent of neural IR and large Pre-trained Language Models, the retrieval paradigm has significantly shifted towards more semantic signals. In this work, we study and analyze to what extent current QPP models can predict the performance of such systems. Our experiments consider seven traditional bag-of-words and seven BERT-based IR approaches, as well as nineteen state-of-the-art QPPs evaluated on two collections, Deep Learning '19 and Robust '04. Our findings show that QPPs perform statistically significantly worse on neural IR systems. In settings where semantic signals are prominent (e.g., passage retrieval), their performance on neural models drops by as much as 10% compared to bag-of-words approaches. On top of that, in lexical-oriented scenarios, QPPs fail to predict performance for neural IR systems on those queries where they differ from traditional approaches the most.
Towards Feature Selection for Ranking and Classification Exploiting Quantum Annealers
May 09, 2022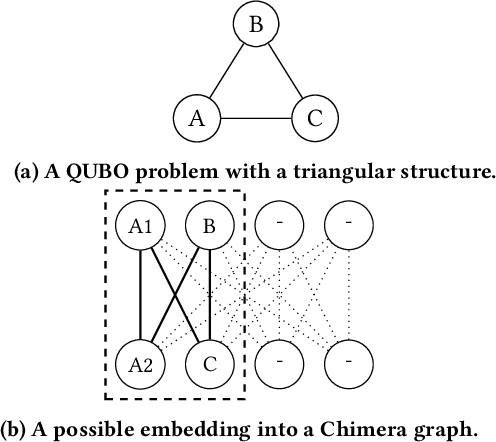
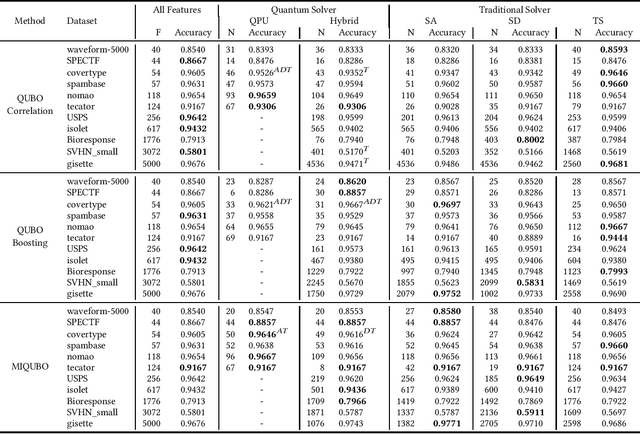
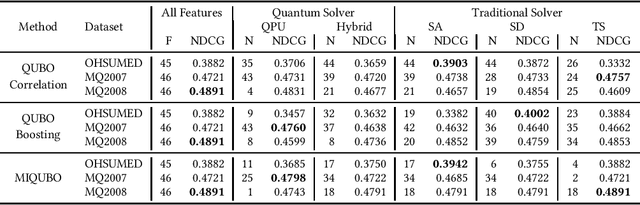
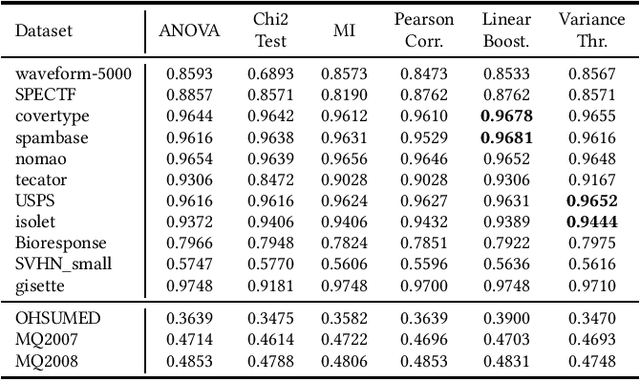
Feature selection is a common step in many ranking, classification, or prediction tasks and serves many purposes. By removing redundant or noisy features, the accuracy of ranking or classification can be improved and the computational cost of the subsequent learning steps can be reduced. However, feature selection can be itself a computationally expensive process. While for decades confined to theoretical algorithmic papers, quantum computing is now becoming a viable tool to tackle realistic problems, in particular special-purpose solvers based on the Quantum Annealing paradigm. This paper aims to explore the feasibility of using currently available quantum computing architectures to solve some quadratic feature selection algorithms for both ranking and classification. The experimental analysis includes 15 state-of-the-art datasets. The effectiveness obtained with quantum computing hardware is comparable to that of classical solvers, indicating that quantum computers are now reliable enough to tackle interesting problems. In terms of scalability, current generation quantum computers are able to provide a limited speedup over certain classical algorithms and hybrid quantum-classical strategies show lower computational cost for problems of more than a thousand features.
* Source code is available on Github https://github.com/qcpolimi/SIGIR22_QuantumFeatureSelection.git