 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting RAG Advertisements Across Advertising Styles
Mar 05, 2026Large language models (LLMs) enable a new form of advertising for retrieval-augmented generation (RAG) systems in which organic responses are blended with contextually relevant ads. The prospect of such "generated native ads" has sparked interest in whether they can be detected automatically. Existing datasets, however, do not reflect the diversity of advertising styles discussed in the marketing literature. In this paper, we (1) develop a taxonomy of advertising styles for LLMs, combining the style dimensions of explicitness and type of appeal, (2) simulate that advertisers may attempt to evade detection by changing their advertising style, and (3) evaluate a variety of ad-detection approaches with respect to their robustness under these changes. Expanding previous work on ad detection, we train models that use entity recognition to exactly locate an ad in an LLM response and find them to be both very effective at detecting responses with ads and largely robust to changes in the advertising style. Since ad blocking will be performed on low-resource end-user devices, we include lightweight models like random forests and SVMs in our evaluation. These models, however, are brittle under such changes, highlighting the need for further efficiency-oriented research for a practical approach to blocking of generated ads.
The Viability of Crowdsourcing for RAG Evaluation
Apr 22, 2025



How good are humans at writing and judging responses in retrieval-augmented generation (RAG) scenarios? To answer this question, we investigate the efficacy of crowdsourcing for RAG through two complementary studies: response writing and response utility judgment. We present the Crowd RAG Corpus 2025 (CrowdRAG-25), which consists of 903 human-written and 903 LLM-generated responses for the 301 topics of the TREC RAG'24 track, across the three discourse styles 'bulleted list', 'essay', and 'news'. For a selection of 65 topics, the corpus further contains 47,320 pairwise human judgments and 10,556 pairwise LLM judgments across seven utility dimensions (e.g., coverage and coherence). Our analyses give insights into human writing behavior for RAG and the viability of crowdsourcing for RAG evaluation. Human pairwise judgments provide reliable and cost-effective results compared to LLM-based pairwise or human/LLM-based pointwise judgments, as well as automated comparisons with human-written reference responses. All our data and tools are freely available.
Counterfactual Query Rewriting to Use Historical Relevance Feedback
Feb 06, 2025When a retrieval system receives a query it has encountered before, previous relevance feedback, such as clicks or explicit judgments can help to improve retrieval results. However, the content of a previously relevant document may have changed, or the document might not be available anymore. Despite this evolved corpus, we counterfactually use these previously relevant documents as relevance signals. In this paper we proposed approaches to rewrite user queries and compare them against a system that directly uses the previous qrels for the ranking. We expand queries with terms extracted from the previously relevant documents or derive so-called keyqueries that rank the previously relevant documents to the top of the current corpus. Our evaluation in the CLEF LongEval scenario shows that rewriting queries with historical relevance feedback improves the retrieval effectiveness and even outperforms computationally expensive transformer-based approaches.
Lightning IR: Straightforward Fine-tuning and Inference of Transformer-based Language Models for Information Retrieval
Nov 07, 2024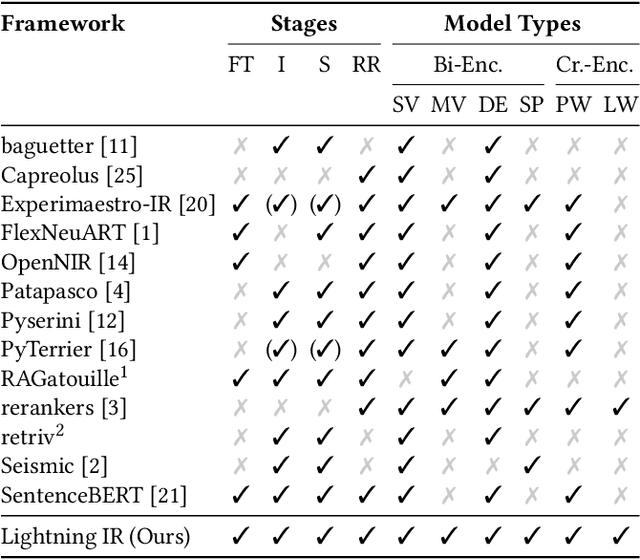

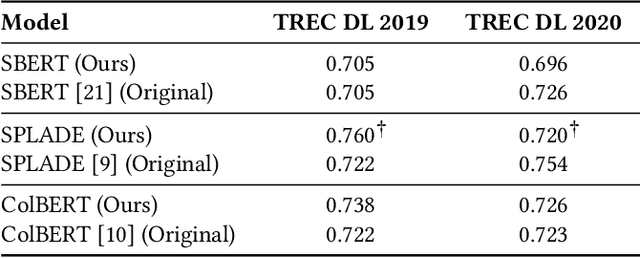
A wide range of transformer-based language models have been proposed for information retrieval tasks. However, fine-tuning and inference of these models is often complex and requires substantial engineering effort. This paper introduces Lightning IR, a PyTorch Lightning-based framework for fine-tuning and inference of transformer-based language models for information retrieval. Lightning IR provides a modular and extensible architecture that supports all stages of an information retrieval pipeline: from fine-tuning and indexing to searching and re-ranking. It is designed to be straightforward to use, scalable, and reproducible. Lightning IR is available as open-source: https://github.com/webis-de/lightning-ir.
Systematic Evaluation of Neural Retrieval Models on the Touché 2020 Argument Retrieval Subset of BEIR
Jul 10, 2024



The zero-shot effectiveness of neural retrieval models is often evaluated on the BEIR benchmark -- a combination of different IR evaluation datasets. Interestingly, previous studies found that particularly on the BEIR subset Touch\'e 2020, an argument retrieval task, neural retrieval models are considerably less effective than BM25. Still, so far, no further investigation has been conducted on what makes argument retrieval so "special". To more deeply analyze the respective potential limits of neural retrieval models, we run a reproducibility study on the Touch\'e 2020 data. In our study, we focus on two experiments: (i) a black-box evaluation (i.e., no model retraining), incorporating a theoretical exploration using retrieval axioms, and (ii) a data denoising evaluation involving post-hoc relevance judgments. Our black-box evaluation reveals an inherent bias of neural models towards retrieving short passages from the Touch\'e 2020 data, and we also find that quite a few of the neural models' results are unjudged in the Touch\'e 2020 data. As many of the short Touch\'e passages are not argumentative and thus non-relevant per se, and as the missing judgments complicate fair comparison, we denoise the Touch\'e 2020 data by excluding very short passages (less than 20 words) and by augmenting the unjudged data with post-hoc judgments following the Touch\'e guidelines. On the denoised data, the effectiveness of the neural models improves by up to 0.52 in nDCG@10, but BM25 is still more effective. Our code and the augmented Touch\'e 2020 dataset are available at \url{https://github.com/castorini/touche-error-analysis}.
A Systematic Investigation of Distilling Large Language Models into Cross-Encoders for Passage Re-ranking
May 13, 2024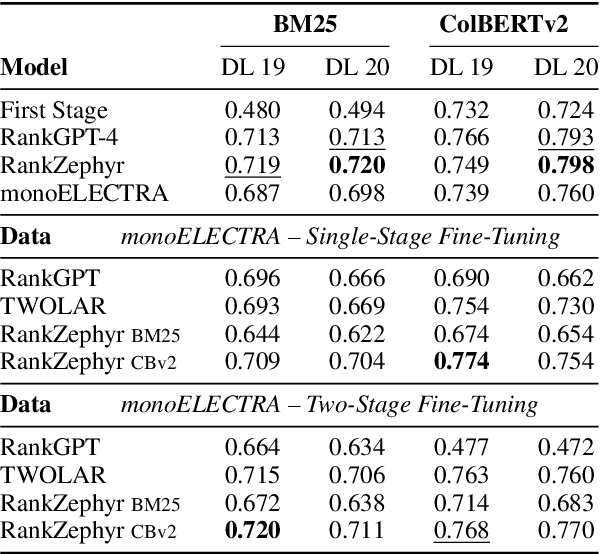
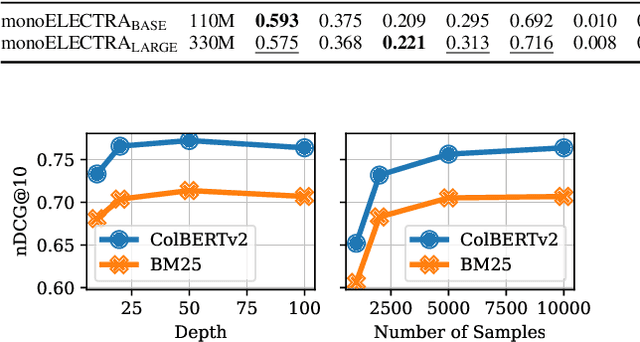
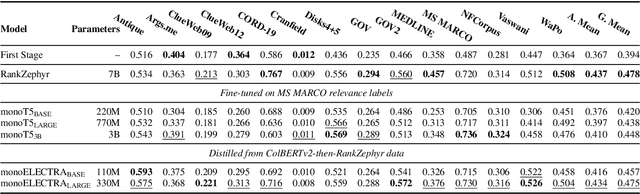
Cross-encoders distilled from large language models are more effective re-rankers than cross-encoders fine-tuned using manually labeled data. However, the distilled models do not reach the language model's effectiveness. We construct and release a new distillation dataset, named Rank-DistiLLM, to investigate whether insights from fine-tuning cross-encoders on manually labeled data -- hard-negative sampling, deep sampling, and listwise loss functions -- are transferable to large language model ranker distillation. Our dataset can be used to train cross-encoders that reach the effectiveness of large language models while being orders of magnitude more efficient. Code and data is available at: https://github.com/webis-de/msmarco-llm-distillation
Set-Encoder: Permutation-Invariant Inter-Passage Attention for Listwise Passage Re-Ranking with Cross-Encoders
Apr 11, 2024Cross-encoders are effective passage re-rankers. But when re-ranking multiple passages at once, existing cross-encoders inefficiently optimize the output ranking over several input permutations, as their passage interactions are not permutation-invariant. Moreover, their high memory footprint constrains the number of passages during listwise training. To tackle these issues, we propose the Set-Encoder, a new cross-encoder architecture that (1) introduces inter-passage attention with parallel passage processing to ensure permutation invariance between input passages, and that (2) uses fused-attention kernels to enable training with more passages at a time. In experiments on TREC Deep Learning and TIREx, the Set-Encoder is more effective than previous cross-encoders with a similar number of parameters. Compared to larger models, the Set-Encoder is more efficient and either on par or even more effective.
Task-Oriented Paraphrase Analytics
Mar 26, 2024



Since paraphrasing is an ill-defined task, the term "paraphrasing" covers text transformation tasks with different characteristics. Consequently, existing paraphrasing studies have applied quite different (explicit and implicit) criteria as to when a pair of texts is to be considered a paraphrase, all of which amount to postulating a certain level of semantic or lexical similarity. In this paper, we conduct a literature review and propose a taxonomy to organize the 25~identified paraphrasing (sub-)tasks. Using classifiers trained to identify the tasks that a given paraphrasing instance fits, we find that the distributions of task-specific instances in the known paraphrase corpora vary substantially. This means that the use of these corpora, without the respective paraphrase conditions being clearly defined (which is the normal case), must lead to incomparable and misleading results.
Analyzing Adversarial Attacks on Sequence-to-Sequence Relevance Models
Mar 12, 2024Modern sequence-to-sequence relevance models like monoT5 can effectively capture complex textual interactions between queries and documents through cross-encoding. However, the use of natural language tokens in prompts, such as Query, Document, and Relevant for monoT5, opens an attack vector for malicious documents to manipulate their relevance score through prompt injection, e.g., by adding target words such as true. Since such possibilities have not yet been considered in retrieval evaluation, we analyze the impact of query-independent prompt injection via manually constructed templates and LLM-based rewriting of documents on several existing relevance models. Our experiments on the TREC Deep Learning track show that adversarial documents can easily manipulate different sequence-to-sequence relevance models, while BM25 (as a typical lexical model) is not affected. Remarkably, the attacks also affect encoder-only relevance models (which do not rely on natural language prompt tokens), albeit to a lesser extent.
Detecting Generated Native Ads in Conversational Search
Feb 07, 2024
Conversational search engines such as YouChat and Microsoft Copilot use large language models (LLMs) to generate answers to queries. It is only a small step to also use this technology to generate and integrate advertising within these answers - instead of placing ads separately from the organic search results. This type of advertising is reminiscent of native advertising and product placement, both of which are very effective forms of subtle and manipulative advertising. It is likely that information seekers will be confronted with such use of LLM technology in the near future, especially when considering the high computational costs associated with LLMs, for which providers need to develop sustainable business models. This paper investigates whether LLMs can also be used as a countermeasure against generated native ads, i.e., to block them. For this purpose we compile a large dataset of ad-prone queries and of generated answers with automatically integrated ads to experiment with fine-tuned sentence transformers and state-of-the-art LLMs on the task of recognizing the ads. In our experiments sentence transformers achieve detection precision and recall values above 0.9, while the investigated LLMs struggle with the task.