 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhere Relevance Emerges: A Layer-Wise Study of Internal Attention for Zero-Shot Re-Ranking
Feb 26, 2026Zero-shot document re-ranking with Large Language Models (LLMs) has evolved from Pointwise methods to Listwise and Setwise approaches that optimize computational efficiency. Despite their success, these methods predominantly rely on generative scoring or output logits, which face bottlenecks in inference latency and result consistency. In-Context Re-ranking (ICR) has recently been proposed as an $O(1)$ alternative method. ICR extracts internal attention signals directly, avoiding the overhead of text generation. However, existing ICR methods simply aggregate signals across all layers; layer-wise contributions and their consistency across architectures have been left unexplored. Furthermore, no unified study has compared internal attention with traditional generative and likelihood-based mechanisms across diverse ranking frameworks under consistent conditions. In this paper, we conduct an orthogonal evaluation of generation, likelihood, and internal attention mechanisms across multiple ranking frameworks. We further identify a universal "bell-curve" distribution of relevance signals across transformer layers, which motivates the proposed Selective-ICR strategy that reduces inference latency by 30%-50% without compromising effectiveness. Finally, evaluation on the reasoning-intensive BRIGHT benchmark shows that precisely capturing high-quality in-context attention signals fundamentally reduces the need for model scaling and reinforcement learning: a zero-shot 8B model matches the performance of 14B reinforcement-learned re-rankers, while even a 0.6B model outperforms state-of-the-art generation-based approaches. These findings redefine the efficiency-effectiveness frontier for LLM-based re-ranking and highlight the latent potential of internal signals for complex reasoning ranking tasks. Our code and results are publicly available at https://github.com/ielab/Selective-ICR.
Beyond Chunk-Then-Embed: A Comprehensive Taxonomy and Evaluation of Document Chunking Strategies for Information Retrieval
Feb 19, 2026Document chunking is a critical preprocessing step in dense retrieval systems, yet the design space of chunking strategies remains poorly understood. Recent research has proposed several concurrent approaches, including LLM-guided methods (e.g., DenseX and LumberChunker) and contextualized strategies(e.g., Late Chunking), which generate embeddings before segmentation to preserve contextual information. However, these methods emerged independently and were evaluated on benchmarks with minimal overlap, making direct comparisons difficult. This paper reproduces prior studies in document chunking and presents a systematic framework that unifies existing strategies along two key dimensions: (1) segmentation methods, including structure-based methods (fixed-size, sentence-based, and paragraph-based) as well as semantically-informed and LLM-guided methods; and (2) embedding paradigms, which determine the timing of chunking relative to embedding (pre-embedding chunking vs. contextualized chunking). Our reproduction evaluates these approaches in two distinct retrieval settings established in previous work: in-document retrieval (needle-in-a-haystack) and in-corpus retrieval (the standard information retrieval task). Our comprehensive evaluation reveals that optimal chunking strategies are task-dependent: simple structure-based methods outperform LLM-guided alternatives for in-corpus retrieval, while LumberChunker performs best for in-document retrieval. Contextualized chunking improves in-corpus effectiveness but degrades in-document retrieval. We also find that chunk size correlates moderately with in-document but weakly with in-corpus effectiveness, suggesting segmentation method differences are not purely driven by chunk size. Our code and evaluation benchmarks are publicly available at (Anonymoused).
Inferential Question Answering
Feb 01, 2026Despite extensive research on a wide range of question answering (QA) systems, most existing work focuses on answer containment-i.e., assuming that answers can be directly extracted and/or generated from documents in the corpus. However, some questions require inference, i.e., deriving answers that are not explicitly stated but can be inferred from the available information. We introduce Inferential QA -- a new task that challenges models to infer answers from answer-supporting passages which provide only clues. To study this problem, we construct QUIT (QUestions requiring Inference from Texts) dataset, comprising 7,401 questions and 2.4M passages built from high-convergence human- and machine-authored hints, labeled across three relevance levels using LLM-based answerability and human verification. Through comprehensive evaluation of retrievers, rerankers, and LLM-based readers, we show that methods effective on traditional QA tasks struggle in inferential QA: retrievers underperform, rerankers offer limited gains, and fine-tuning provides inconsistent improvements. Even reasoning-oriented LLMs fail to outperform smaller general-purpose models. These findings reveal that current QA pipelines are not yet ready for inference-based reasoning. Inferential QA thus establishes a new class of QA tasks that move towards understanding and reasoning from indirect textual evidence.
Beyond GeneGPT: A Multi-Agent Architecture with Open-Source LLMs for Enhanced Genomic Question Answering
Nov 19, 2025Genomic question answering often requires complex reasoning and integration across diverse biomedical sources. GeneGPT addressed this challenge by combining domain-specific APIs with OpenAI's code-davinci-002 large language model to enable natural language interaction with genomic databases. However, its reliance on a proprietary model limits scalability, increases operational costs, and raises concerns about data privacy and generalization. In this work, we revisit and reproduce GeneGPT in a pilot study using open source models, including Llama 3.1, Qwen2.5, and Qwen2.5 Coder, within a monolithic architecture; this allows us to identify the limitations of this approach. Building on this foundation, we then develop OpenBioLLM, a modular multi-agent framework that extends GeneGPT by introducing agent specialization for tool routing, query generation, and response validation. This enables coordinated reasoning and role-based task execution. OpenBioLLM matches or outperforms GeneGPT on over 90% of the benchmark tasks, achieving average scores of 0.849 on Gene-Turing and 0.830 on GeneHop, while using smaller open-source models without additional fine-tuning or tool-specific pretraining. OpenBioLLM's modular multi-agent design reduces latency by 40-50% across benchmark tasks, significantly improving efficiency without compromising model capability. The results of our comprehensive evaluation highlight the potential of open-source multi-agent systems for genomic question answering. Code and resources are available at https://github.com/ielab/OpenBioLLM.
Unlearning for Federated Online Learning to Rank: A Reproducibility Study
May 19, 2025This paper reports on findings from a comparative study on the effectiveness and efficiency of federated unlearning strategies within Federated Online Learning to Rank (FOLTR), with specific attention to systematically analysing the unlearning capabilities of methods in a verifiable manner. Federated approaches to ranking of search results have recently garnered attention to address users privacy concerns. In FOLTR, privacy is safeguarded by collaboratively training ranking models across decentralized data sources, preserving individual user data while optimizing search results based on implicit feedback, such as clicks. Recent legislation introduced across numerous countries is establishing the so called "the right to be forgotten", according to which services based on machine learning models like those in FOLTR should provide capabilities that allow users to remove their own data from those used to train models. This has sparked the development of unlearning methods, along with evaluation practices to measure whether unlearning of a user data successfully occurred. Current evaluation practices are however often controversial, necessitating the use of multiple metrics for a more comprehensive assessment -- but previous proposals of unlearning methods only used single evaluation metrics. This paper addresses this limitation: our study rigorously assesses the effectiveness of unlearning strategies in managing both under-unlearning and over-unlearning scenarios using adapted, and newly proposed evaluation metrics. Thanks to our detailed analysis, we uncover the strengths and limitations of five unlearning strategies, offering valuable insights into optimizing federated unlearning to balance data privacy and system performance within FOLTR. We publicly release our code and complete results at https://github.com/Iris1026/Unlearning-for-FOLTR.git.
Pre-training vs. Fine-tuning: A Reproducibility Study on Dense Retrieval Knowledge Acquisition
May 12, 2025Dense retrievers utilize pre-trained backbone language models (e.g., BERT, LLaMA) that are fine-tuned via contrastive learning to perform the task of encoding text into sense representations that can be then compared via a shallow similarity operation, e.g. inner product. Recent research has questioned the role of fine-tuning vs. that of pre-training within dense retrievers, specifically arguing that retrieval knowledge is primarily gained during pre-training, meaning knowledge not acquired during pre-training cannot be sub-sequentially acquired via fine-tuning. We revisit this idea here as the claim was only studied in the context of a BERT-based encoder using DPR as representative dense retriever. We extend the previous analysis by testing other representation approaches (comparing the use of CLS tokens with that of mean pooling), backbone architectures (encoder-only BERT vs. decoder-only LLaMA), and additional datasets (MSMARCO in addition to Natural Questions). Our study confirms that in DPR tuning, pre-trained knowledge underpins retrieval performance, with fine-tuning primarily adjusting neuron activation rather than reorganizing knowledge. However, this pattern does not hold universally, such as in mean-pooled (Contriever) and decoder-based (LLaMA) models. We ensure full reproducibility and make our implementation publicly available at https://github.com/ielab/DenseRetriever-Knowledge-Acquisition.
Reassessing Large Language Model Boolean Query Generation for Systematic Reviews
May 12, 2025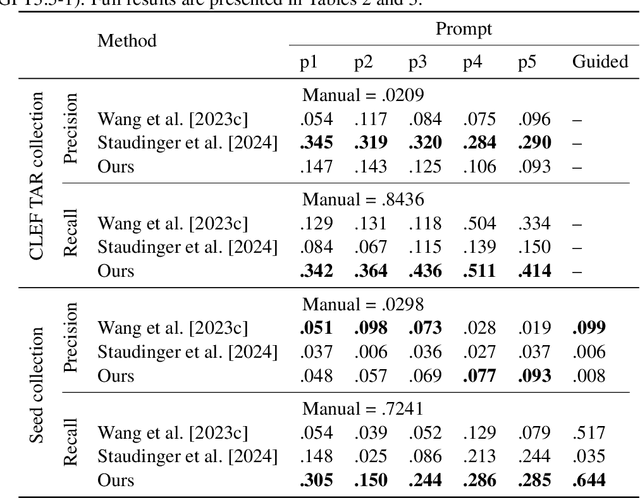
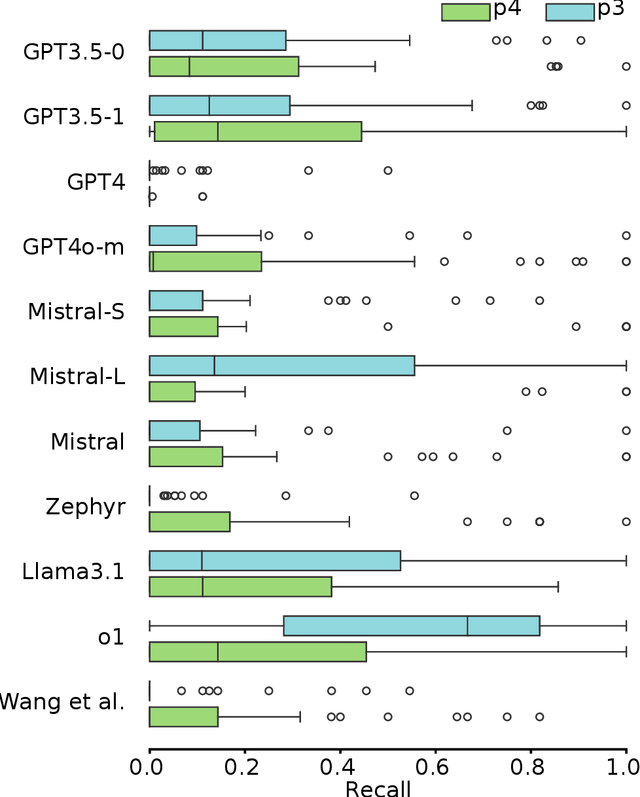
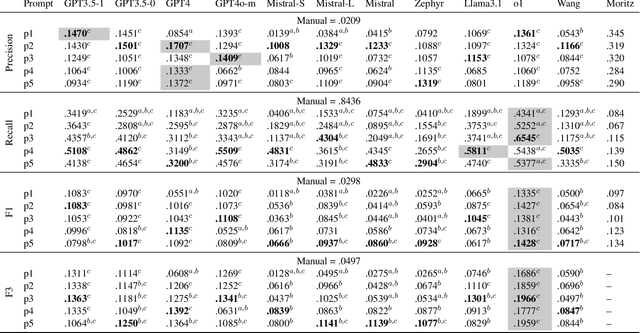

Systematic reviews are comprehensive literature reviews that address highly focused research questions and represent the highest form of evidence in medicine. A critical step in this process is the development of complex Boolean queries to retrieve relevant literature. Given the difficulty of manually constructing these queries, recent efforts have explored Large Language Models (LLMs) to assist in their formulation. One of the first studies,Wang et al., investigated ChatGPT for this task, followed by Staudinger et al., which evaluated multiple LLMs in a reproducibility study. However, the latter overlooked several key aspects of the original work, including (i) validation of generated queries, (ii) output formatting constraints, and (iii) selection of examples for chain-of-thought (Guided) prompting. As a result, its findings diverged significantly from the original study. In this work, we systematically reproduce both studies while addressing these overlooked factors. Our results show that query effectiveness varies significantly across models and prompt designs, with guided query formulation benefiting from well-chosen seed studies. Overall, prompt design and model selection are key drivers of successful query formulation. Our findings provide a clearer understanding of LLMs' potential in Boolean query generation and highlight the importance of model- and prompt-specific optimisations. The complex nature of systematic reviews adds to challenges in both developing and reproducing methods but also highlights the importance of reproducibility studies in this domain.
AiReview: An Open Platform for Accelerating Systematic Reviews with LLMs
Apr 05, 2025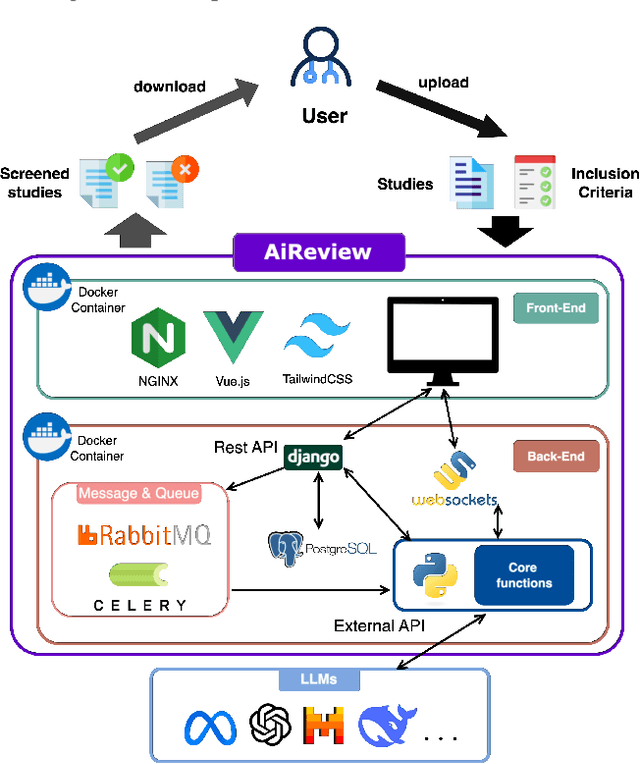
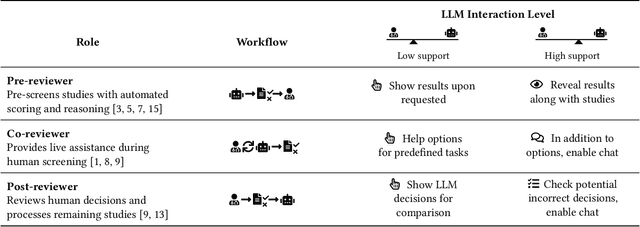
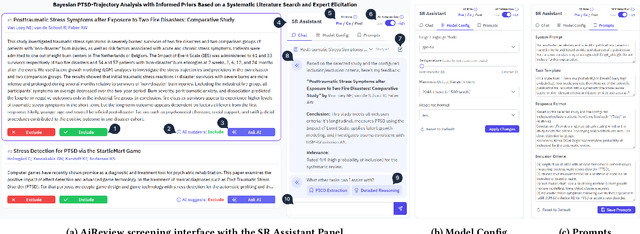
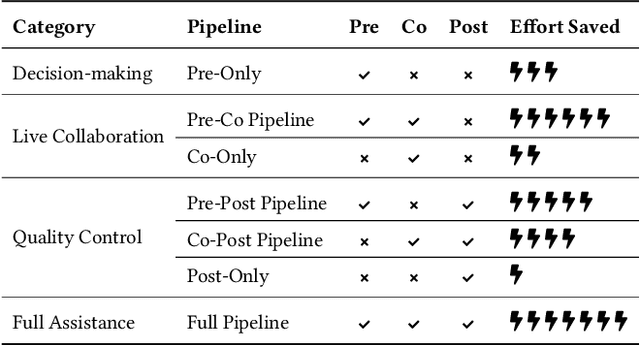
Systematic reviews are fundamental to evidence-based medicine. Creating one is time-consuming and labour-intensive, mainly due to the need to screen, or assess, many studies for inclusion in the review. Several tools have been developed to streamline this process, mostly relying on traditional machine learning methods. Large language models (LLMs) have shown potential in further accelerating the screening process. However, no tool currently allows end users to directly leverage LLMs for screening or facilitates systematic and transparent usage of LLM-assisted screening methods. This paper introduces (i) an extensible framework for applying LLMs to systematic review tasks, particularly title and abstract screening, and (ii) a web-based interface for LLM-assisted screening. Together, these elements form AiReview-a novel platform for LLM-assisted systematic review creation. AiReview is the first of its kind to bridge the gap between cutting-edge LLM-assisted screening methods and those that create medical systematic reviews. The tool is available at https://aireview.ielab.io. The source code is also open sourced at https://github.com/ielab/ai-review.
LLM-VPRF: Large Language Model Based Vector Pseudo Relevance Feedback
Apr 02, 2025Vector Pseudo Relevance Feedback (VPRF) has shown promising results in improving BERT-based dense retrieval systems through iterative refinement of query representations. This paper investigates the generalizability of VPRF to Large Language Model (LLM) based dense retrievers. We introduce LLM-VPRF and evaluate its effectiveness across multiple benchmark datasets, analyzing how different LLMs impact the feedback mechanism. Our results demonstrate that VPRF's benefits successfully extend to LLM architectures, establishing it as a robust technique for enhancing dense retrieval performance regardless of the underlying models. This work bridges the gap between VPRF with traditional BERT-based dense retrievers and modern LLMs, while providing insights into their future directions.
Pseudo-Relevance Feedback Can Improve Zero-Shot LLM-Based Dense Retrieval
Mar 19, 2025
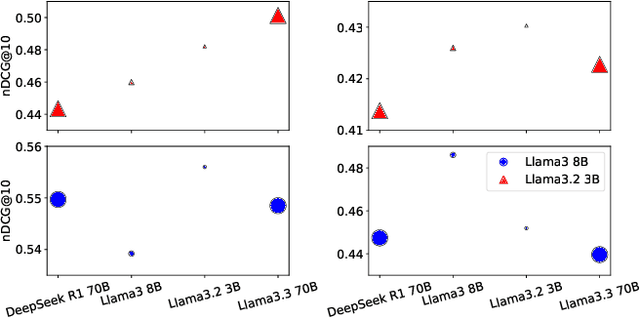

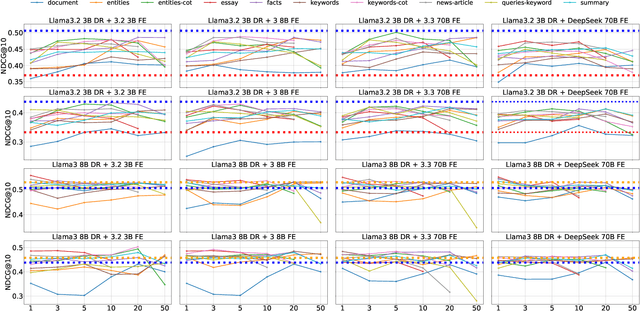
Pseudo-relevance feedback (PRF) refines queries by leveraging initially retrieved documents to improve retrieval effectiveness. In this paper, we investigate how large language models (LLMs) can facilitate PRF for zero-shot LLM-based dense retrieval, extending the recently proposed PromptReps method. Specifically, our approach uses LLMs to extract salient passage features-such as keywords and summaries-from top-ranked documents, which are then integrated into PromptReps to produce enhanced query representations. Experiments on passage retrieval benchmarks demonstrate that incorporating PRF significantly boosts retrieval performance. Notably, smaller rankers with PRF can match the effectiveness of larger rankers without PRF, highlighting PRF's potential to improve LLM-driven search while maintaining an efficient balance between effectiveness and resource usage.