 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePLOT: Enhancing Preference Learning via Optimal Transport
Apr 02, 2026Preference learning in Large Language Models (LLMs) has advanced significantly, yet existing methods remain limited by modest performance gains, high computational costs, hyperparameter sensitivity, and insufficient modeling of global token-level relationships. We introduce PLOT, which enhances Preference Learning in fine-tuning-based alignment through a token-level loss derived from Optimal Transport. By formulating preference learning as an Optimal Transport Problem, PLOT aligns model outputs with human preferences while preserving the original distribution of LLMs, ensuring stability and robustness. Furthermore, PLOT leverages token embeddings to capture semantic relationships, enabling globally informed optimization. Experiments across two preference categories - Human Values and Logic & Problem Solving - spanning seven subpreferences demonstrate that PLOT consistently improves alignment performance while maintaining fluency and coherence. These results substantiate optimal transport as a principled methodology for preference learning, establishing a theoretically grounded framework that provides new insights for preference learning of LLMs.
Mitigating topology biases in Graph Diffusion via Counterfactual Intervention
Mar 02, 2026Graph diffusion models have gained significant attention in graph generation tasks, but they often inherit and amplify topology biases from sensitive attributes (e.g. gender, age, region), leading to unfair synthetic graphs. Existing fair graph generation using diffusion models is limited to specific graph-based applications with complete labels or requires simultaneous updates for graph structure and node attributes, making them unsuitable for general usage. To relax these limitations by applying the debiasing method directly on graph topology, we propose Fair Graph Diffusion Model (FairGDiff), a counterfactual-based one-step solution that mitigates topology biases while balancing fairness and utility. In detail, we construct a causal model to capture the relationship between sensitive attributes, biased link formation, and the generated graph structure. By answering the counterfactual question "Would the graph structure change if the sensitive attribute were different?", we estimate an unbiased treatment and incorporate it into the diffusion process. FairGDiff integrates counterfactual learning into both forward diffusion and backward denoising, ensuring that the generated graphs are independent of sensitive attributes while preserving structural integrity. Extensive experiments on real-world datasets demonstrate that FairGDiff achieves a superior trade-off between fairness and utility, outperforming existing fair graph generation methods while maintaining scalability.
Qwen3-Coder-Next Technical Report
Feb 28, 2026We present Qwen3-Coder-Next, an open-weight language model specialized for coding agents. Qwen3-Coder-Next is an 80-billion-parameter model that activates only 3 billion parameters during inference, enabling strong coding capability with efficient inference. In this work, we explore how far strong training recipes can push the capability limits of models with small parameter footprints. To achieve this, we perform agentic training through large-scale synthesis of verifiable coding tasks paired with executable environments, allowing learning directly from environment feedback via mid-training and reinforcement learning. Across agent-centric benchmarks including SWE-Bench and Terminal-Bench, Qwen3-Coder-Next achieves competitive performance relative to its active parameter count. We release both base and instruction-tuned open-weight versions to support research and real-world coding agent development.
Scaling Agentic Verifier for Competitive Coding
Feb 04, 2026Large language models (LLMs) have demonstrated strong coding capabilities but still struggle to solve competitive programming problems correctly in a single attempt. Execution-based re-ranking offers a promising test-time scaling strategy, yet existing methods are constrained by either difficult test case generation or inefficient random input sampling. To address this limitation, we propose Agentic Verifier, an execution-based agent that actively reasons about program behaviors and searches for highly discriminative test inputs that expose behavioral discrepancies among candidate solutions. Through multi-turn interaction with code execution environments, the verifier iteratively refines the candidate input generator and produces targeted counterexamples rather than blindly sampling inputs. We train the verifier to acquire this discriminative input generation capability via a scalable pipeline combining large-scale data synthesis, rejection fine-tuning, and agentic reinforcement learning. Extensive experiments across five competitive programming benchmarks demonstrate consistent improvements over strong execution-based baselines, achieving up to +10-15% absolute gains in Best@K accuracy. Further analysis reveals clear test-time scaling behavior and highlights the verifier's broader potential beyond reranking.
SWE-Universe: Scale Real-World Verifiable Environments to Millions
Feb 02, 2026We propose SWE-Universe, a scalable and efficient framework for automatically constructing real-world software engineering (SWE) verifiable environments from GitHub pull requests (PRs). To overcome the prevalent challenges of automatic building, such as low production yield, weak verifiers, and prohibitive cost, our framework utilizes a building agent powered by an efficient custom-trained model. This agent employs iterative self-verification and in-loop hacking detection to ensure the reliable generation of high-fidelity, verifiable tasks. Using this method, we scale the number of real-world multilingual SWE environments to a million scale (807,693). We demonstrate the profound value of our environments through large-scale agentic mid-training and reinforcement learning. Finally, we applied this technique to Qwen3-Max-Thinking and achieved a score of 75.3% on SWE-Bench Verified. Our work provides both a critical resource and a robust methodology to advance the next generation of coding agents.
Steering to Say No: Configurable Refusal via Activation Steering in Vision Language Models
Jan 31, 2026With the rapid advancement of Vision Language Models (VLMs), refusal mechanisms have become a critical component for ensuring responsible and safe model behavior. However, existing refusal strategies are largely \textit{one-size-fits-all} and fail to adapt to diverse user needs and contextual constraints, leading to either under-refusal or over-refusal. In this work, we firstly explore the challenges mentioned above and develop \textbf{C}onfigurable \textbf{R}efusal in \textbf{VLM}s (\textbf{CR-VLM}), a robust and efficient approach for {\em configurable} refusal based on activation steering. CR-VLM consists of three integrated components: (1) extracting a configurable refusal vector via a teacher-forced mechanism to amplify the refusal signal; (2) introducing a gating mechanism that mitigates over-refusal by preserving acceptance for in-scope queries; and (3) designing a counterfactual vision enhancement module that aligns visual representations with refusal requirements. Comprehensive experiments across multiple datasets and various VLMs demonstrate that CR-VLM achieves effective, efficient, and robust configurable refusals, offering a scalable path toward user-adaptive safety alignment in VLMs.
Evaluating and Achieving Controllable Code Completion in Code LLM
Jan 22, 2026Code completion has become a central task, gaining significant attention with the rise of large language model (LLM)-based tools in software engineering. Although recent advances have greatly improved LLMs' code completion abilities, evaluation methods have not advanced equally. Most current benchmarks focus solely on functional correctness of code completions based on given context, overlooking models' ability to follow user instructions during completion-a common scenario in LLM-assisted programming. To address this limitation, we present the first instruction-guided code completion benchmark, Controllable Code Completion Benchmark (C3-Bench), comprising 2,195 carefully designed completion tasks. Through comprehensive evaluation of over 40 mainstream LLMs across C3-Bench and conventional benchmarks, we reveal substantial gaps in instruction-following capabilities between open-source and advanced proprietary models during code completion tasks. Moreover, we develop a straightforward data synthesis pipeline that leverages Qwen2.5-Coder to generate high-quality instruction-completion pairs for supervised fine-tuning (SFT). The resulting model, Qwen2.5-Coder-C3, achieves state-of-the-art performance on C3-Bench. Our findings provide valuable insights for enhancing LLMs' code completion and instruction-following capabilities, establishing new directions for future research in code LLMs. To facilitate reproducibility and foster further research in code LLMs, we open-source all code, datasets, and models.
From Completion to Editing: Unlocking Context-Aware Code Infilling via Search-and-Replace Instruction Tuning
Jan 19, 2026The dominant Fill-in-the-Middle (FIM) paradigm for code completion is constrained by its rigid inability to correct contextual errors and reliance on unaligned, insecure Base models. While Chat LLMs offer safety and Agentic workflows provide flexibility, they suffer from performance degradation and prohibitive latency, respectively. To resolve this dilemma, we propose Search-and-Replace Infilling (SRI), a framework that internalizes the agentic verification-and-editing mechanism into a unified, single-pass inference process. By structurally grounding edits via an explicit search phase, SRI harmonizes completion tasks with the instruction-following priors of Chat LLMs, extending the paradigm from static infilling to dynamic context-aware editing. We synthesize a high-quality dataset, SRI-200K, and fine-tune the SRI-Coder series. Extensive evaluations demonstrate that with minimal data (20k samples), SRI-Coder enables Chat models to surpass the completion performance of their Base counterparts. Crucially, unlike FIM-style tuning, SRI preserves general coding competencies and maintains inference latency comparable to standard FIM. We empower the entire Qwen3-Coder series with SRI, encouraging the developer community to leverage this framework for advanced auto-completion and assisted development.
SWE-RM: Execution-free Feedback For Software Engineering Agents
Dec 26, 2025
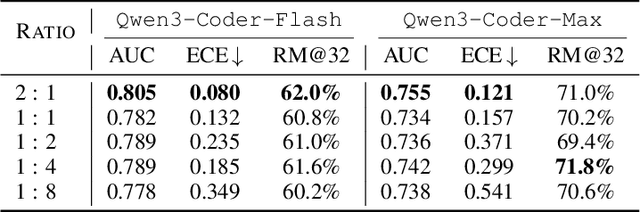

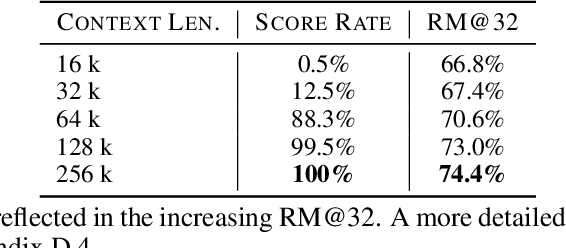
Execution-based feedback like unit testing is widely used in the development of coding agents through test-time scaling (TTS) and reinforcement learning (RL). This paradigm requires scalable and reliable collection of unit test cases to provide accurate feedback, and the resulting feedback is often sparse and cannot effectively distinguish between trajectories that are both successful or both unsuccessful. In contrast, execution-free feedback from reward models can provide more fine-grained signals without depending on unit test cases. Despite this potential, execution-free feedback for realistic software engineering (SWE) agents remains underexplored. Aiming to develop versatile reward models that are effective across TTS and RL, however, we observe that two verifiers with nearly identical TTS performance can nevertheless yield very different results in RL. Intuitively, TTS primarily reflects the model's ability to select the best trajectory, but this ability does not necessarily generalize to RL. To address this limitation, we identify two additional aspects that are crucial for RL training: classification accuracy and calibration. We then conduct comprehensive controlled experiments to investigate how to train a robust reward model that performs well across these metrics. In particular, we analyze the impact of various factors such as training data scale, policy mixtures, and data source composition. Guided by these investigations, we introduce SWE-RM, an accurate and robust reward model adopting a mixture-of-experts architecture with 30B total parameters and 3B activated during inference. SWE-RM substantially improves SWE agents on both TTS and RL performance. For example, it increases the accuracy of Qwen3-Coder-Flash from 51.6% to 62.0%, and Qwen3-Coder-Max from 67.0% to 74.6% on SWE-Bench Verified using TTS, achieving new state-of-the-art performance among open-source models.
SWE-Flow: Synthesizing Software Engineering Data in a Test-Driven Manner
Jun 11, 2025We introduce **SWE-Flow**, a novel data synthesis framework grounded in Test-Driven Development (TDD). Unlike existing software engineering data that rely on human-submitted issues, **SWE-Flow** automatically infers incremental development steps directly from unit tests, which inherently encapsulate high-level requirements. The core of **SWE-Flow** is the construction of a Runtime Dependency Graph (RDG), which precisely captures function interactions, enabling the generation of a structured, step-by-step *development schedule*. At each step, **SWE-Flow** produces a partial codebase, the corresponding unit tests, and the necessary code modifications, resulting in fully verifiable TDD tasks. With this approach, we generated 16,061 training instances and 2,020 test instances from real-world GitHub projects, creating the **SWE-Flow-Eval** benchmark. Our experiments show that fine-tuning open model on this dataset significantly improves performance in TDD-based coding. To facilitate further research, we release all code, datasets, models, and Docker images at [Github](https://github.com/Hambaobao/SWE-Flow).