 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePLawBench: A Rubric-Based Benchmark for Evaluating LLMs in Real-World Legal Practice
Jan 23, 2026As large language models (LLMs) are increasingly applied to legal domain-specific tasks, evaluating their ability to perform legal work in real-world settings has become essential. However, existing legal benchmarks rely on simplified and highly standardized tasks, failing to capture the ambiguity, complexity, and reasoning demands of real legal practice. Moreover, prior evaluations often adopt coarse, single-dimensional metrics and do not explicitly assess fine-grained legal reasoning. To address these limitations, we introduce PLawBench, a Practical Law Benchmark designed to evaluate LLMs in realistic legal practice scenarios. Grounded in real-world legal workflows, PLawBench models the core processes of legal practitioners through three task categories: public legal consultation, practical case analysis, and legal document generation. These tasks assess a model's ability to identify legal issues and key facts, perform structured legal reasoning, and generate legally coherent documents. PLawBench comprises 850 questions across 13 practical legal scenarios, with each question accompanied by expert-designed evaluation rubrics, resulting in approximately 12,500 rubric items for fine-grained assessment. Using an LLM-based evaluator aligned with human expert judgments, we evaluate 10 state-of-the-art LLMs. Experimental results show that none achieves strong performance on PLawBench, revealing substantial limitations in the fine-grained legal reasoning capabilities of current LLMs and highlighting important directions for future evaluation and development of legal LLMs. Data is available at: https://github.com/skylenage/PLawbench.
Qwen3-VL-Embedding and Qwen3-VL-Reranker: A Unified Framework for State-of-the-Art Multimodal Retrieval and Ranking
Jan 08, 2026In this report, we introduce the Qwen3-VL-Embedding and Qwen3-VL-Reranker model series, the latest extensions of the Qwen family built on the Qwen3-VL foundation model. Together, they provide an end-to-end pipeline for high-precision multimodal search by mapping diverse modalities, including text, images, document images, and video, into a unified representation space. The Qwen3-VL-Embedding model employs a multi-stage training paradigm, progressing from large-scale contrastive pre-training to reranking model distillation, to generate semantically rich high-dimensional vectors. It supports Matryoshka Representation Learning, enabling flexible embedding dimensions, and handles inputs up to 32k tokens. Complementing this, Qwen3-VL-Reranker performs fine-grained relevance estimation for query-document pairs using a cross-encoder architecture with cross-attention mechanisms. Both model series inherit the multilingual capabilities of Qwen3-VL, supporting more than 30 languages, and are released in $\textbf{2B}$ and $\textbf{8B}$ parameter sizes to accommodate diverse deployment requirements. Empirical evaluations demonstrate that the Qwen3-VL-Embedding series achieves state-of-the-art results across diverse multimodal embedding evaluation benchmarks. Specifically, Qwen3-VL-Embedding-8B attains an overall score of $\textbf{77.8}$ on MMEB-V2, ranking first among all models (as of January 8, 2025). This report presents the architecture, training methodology, and practical capabilities of the series, demonstrating their effectiveness on various multimodal retrieval tasks, including image-text retrieval, visual question answering, and video-text matching.
Qwen3Guard Technical Report
Oct 16, 2025As large language models (LLMs) become more capable and widely used, ensuring the safety of their outputs is increasingly critical. Existing guardrail models, though useful in static evaluation settings, face two major limitations in real-world applications: (1) they typically output only binary "safe/unsafe" labels, which can be interpreted inconsistently across diverse safety policies, rendering them incapable of accommodating varying safety tolerances across domains; and (2) they require complete model outputs before performing safety checks, making them fundamentally incompatible with streaming LLM inference, thereby preventing timely intervention during generation and increasing exposure to harmful partial outputs. To address these challenges, we present Qwen3Guard, a series of multilingual safety guardrail models with two specialized variants: Generative Qwen3Guard, which casts safety classification as an instruction-following task to enable fine-grained tri-class judgments (safe, controversial, unsafe); and Stream Qwen3Guard, which introduces a token-level classification head for real-time safety monitoring during incremental text generation. Both variants are available in three sizes (0.6B, 4B, and 8B parameters) and support up to 119 languages and dialects, providing comprehensive, scalable, and low-latency safety moderation for global LLM deployments. Evaluated across English, Chinese, and multilingual benchmarks, Qwen3Guard achieves state-of-the-art performance in both prompt and response safety classification. All models are released under the Apache 2.0 license for public use.
RMTBench: Benchmarking LLMs Through Multi-Turn User-Centric Role-Playing
Jul 27, 2025Recent advancements in Large Language Models (LLMs) have shown outstanding potential for role-playing applications. Evaluating these capabilities is becoming crucial yet remains challenging. Existing benchmarks mostly adopt a \textbf{character-centric} approach, simplify user-character interactions to isolated Q&A tasks, and fail to reflect real-world applications. To address this limitation, we introduce RMTBench, a comprehensive \textbf{user-centric} bilingual role-playing benchmark featuring 80 diverse characters and over 8,000 dialogue rounds. RMTBench includes custom characters with detailed backgrounds and abstract characters defined by simple traits, enabling evaluation across various user scenarios. Our benchmark constructs dialogues based on explicit user motivations rather than character descriptions, ensuring alignment with practical user applications. Furthermore, we construct an authentic multi-turn dialogue simulation mechanism. With carefully selected evaluation dimensions and LLM-based scoring, this mechanism captures the complex intention of conversations between the user and the character. By shifting focus from character background to user intention fulfillment, RMTBench bridges the gap between academic evaluation and practical deployment requirements, offering a more effective framework for assessing role-playing capabilities in LLMs. All code and datasets will be released soon.
Group Sequence Policy Optimization
Jul 24, 2025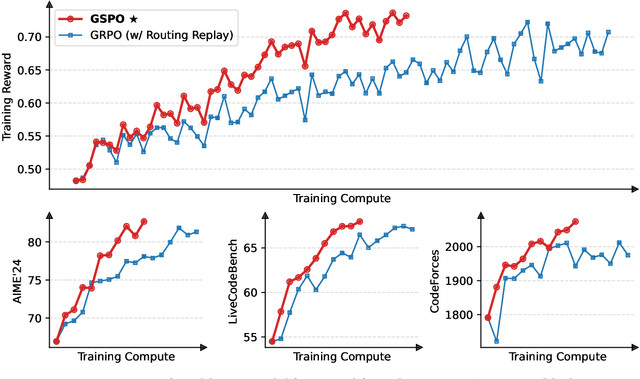
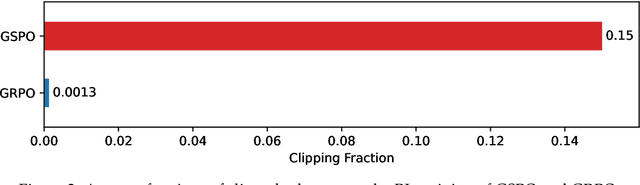
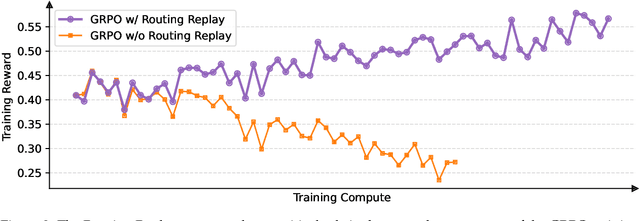
This paper introduces Group Sequence Policy Optimization (GSPO), our stable, efficient, and performant reinforcement learning algorithm for training large language models. Unlike previous algorithms that adopt token-level importance ratios, GSPO defines the importance ratio based on sequence likelihood and performs sequence-level clipping, rewarding, and optimization. We demonstrate that GSPO achieves superior training efficiency and performance compared to the GRPO algorithm, notably stabilizes Mixture-of-Experts (MoE) RL training, and has the potential for simplifying the design of RL infrastructure. These merits of GSPO have contributed to the remarkable improvements in the latest Qwen3 models.
Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models
Jun 05, 2025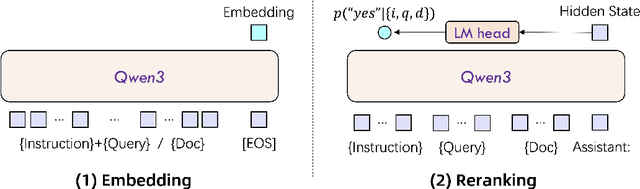
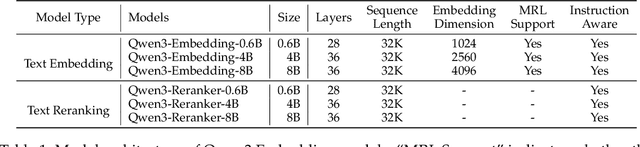

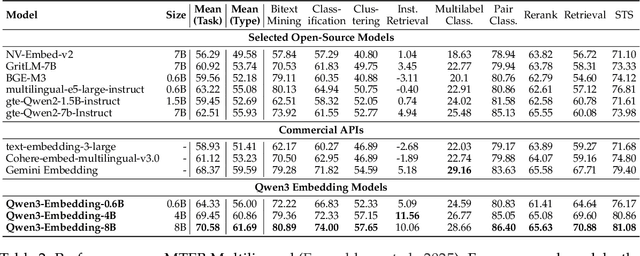
In this work, we introduce the Qwen3 Embedding series, a significant advancement over its predecessor, the GTE-Qwen series, in text embedding and reranking capabilities, built upon the Qwen3 foundation models. Leveraging the Qwen3 LLMs' robust capabilities in multilingual text understanding and generation, our innovative multi-stage training pipeline combines large-scale unsupervised pre-training with supervised fine-tuning on high-quality datasets. Effective model merging strategies further ensure the robustness and adaptability of the Qwen3 Embedding series. During the training process, the Qwen3 LLMs serve not only as backbone models but also play a crucial role in synthesizing high-quality, rich, and diverse training data across multiple domains and languages, thus enhancing the training pipeline. The Qwen3 Embedding series offers a spectrum of model sizes (0.6B, 4B, 8B) for both embedding and reranking tasks, addressing diverse deployment scenarios where users can optimize for either efficiency or effectiveness. Empirical evaluations demonstrate that the Qwen3 Embedding series achieves state-of-the-art results across diverse benchmarks. Notably, it excels on the multilingual evaluation benchmark MTEB for text embedding, as well as in various retrieval tasks, including code retrieval, cross-lingual retrieval and multilingual retrieval. To facilitate reproducibility and promote community-driven research and development, the Qwen3 Embedding models are publicly available under the Apache 2.0 license.
Rationales Are Not Silver Bullets: Measuring the Impact of Rationales on Model Performance and Reliability
May 30, 2025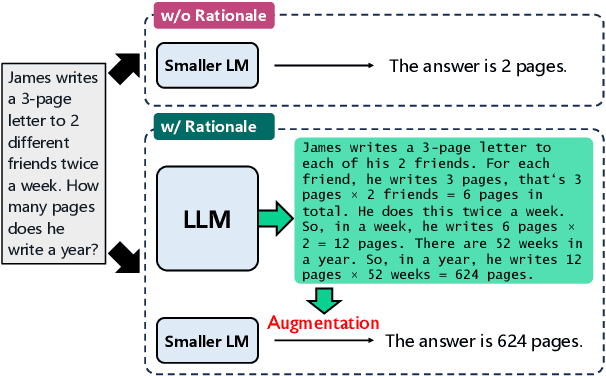
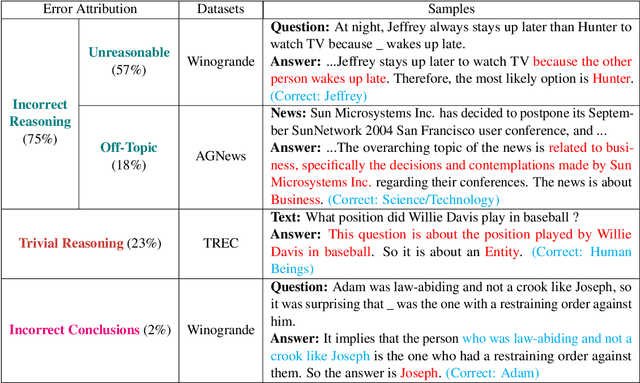
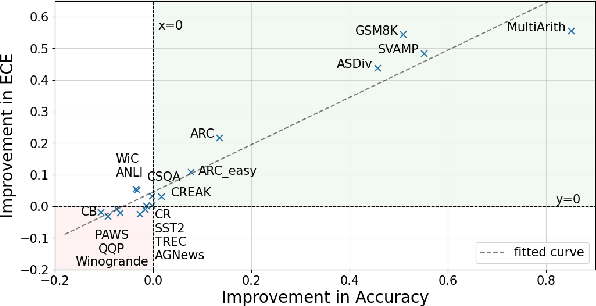

Training language models with rationales augmentation has been shown to be beneficial in many existing works. In this paper, we identify that such a prevailing view does not hold consistently. We conduct comprehensive investigations to thoroughly inspect the impact of rationales on model performance as well as a novel perspective of model reliability. The results lead to several key findings that add new insights upon existing understandings: 1) Rationales can, at times, deteriorate model performance; 2) Rationales can, at times, improve model reliability, even outperforming their untrained counterparts; 3) A linear correspondence exists in between the performance and reliability improvements, while both are driven by the intrinsic difficulty of the task. These findings provide informative regulations on the broad utilization of rationales and raise critical implications on the procedure of explicitly aligning language models with implicit human thoughts. Codes can be found at https://github.com/Ignoramus0817/rationales.
WorldPM: Scaling Human Preference Modeling
May 15, 2025Motivated by scaling laws in language modeling that demonstrate how test loss scales as a power law with model and dataset sizes, we find that similar laws exist in preference modeling. We propose World Preference Modeling$ (WorldPM) to emphasize this scaling potential, where World Preference embodies a unified representation of human preferences. In this paper, we collect preference data from public forums covering diverse user communities, and conduct extensive training using 15M-scale data across models ranging from 1.5B to 72B parameters. We observe distinct patterns across different evaluation metrics: (1) Adversarial metrics (ability to identify deceptive features) consistently scale up with increased training data and base model size; (2) Objective metrics (objective knowledge with well-defined answers) show emergent behavior in larger language models, highlighting WorldPM's scalability potential; (3) Subjective metrics (subjective preferences from a limited number of humans or AI) do not demonstrate scaling trends. Further experiments validate the effectiveness of WorldPM as a foundation for preference fine-tuning. Through evaluations on 7 benchmarks with 20 subtasks, we find that WorldPM broadly improves the generalization performance across human preference datasets of varying sizes (7K, 100K and 800K samples), with performance gains exceeding 5% on many key subtasks. Integrating WorldPM into our internal RLHF pipeline, we observe significant improvements on both in-house and public evaluation sets, with notable gains of 4% to 8% in our in-house evaluations.
Qwen3 Technical Report
May 14, 2025



In this work, we present Qwen3, the latest version of the Qwen model family. Qwen3 comprises a series of large language models (LLMs) designed to advance performance, efficiency, and multilingual capabilities. The Qwen3 series includes models of both dense and Mixture-of-Expert (MoE) architectures, with parameter scales ranging from 0.6 to 235 billion. A key innovation in Qwen3 is the integration of thinking mode (for complex, multi-step reasoning) and non-thinking mode (for rapid, context-driven responses) into a unified framework. This eliminates the need to switch between different models--such as chat-optimized models (e.g., GPT-4o) and dedicated reasoning models (e.g., QwQ-32B)--and enables dynamic mode switching based on user queries or chat templates. Meanwhile, Qwen3 introduces a thinking budget mechanism, allowing users to allocate computational resources adaptively during inference, thereby balancing latency and performance based on task complexity. Moreover, by leveraging the knowledge from the flagship models, we significantly reduce the computational resources required to build smaller-scale models, while ensuring their highly competitive performance. Empirical evaluations demonstrate that Qwen3 achieves state-of-the-art results across diverse benchmarks, including tasks in code generation, mathematical reasoning, agent tasks, etc., competitive against larger MoE models and proprietary models. Compared to its predecessor Qwen2.5, Qwen3 expands multilingual support from 29 to 119 languages and dialects, enhancing global accessibility through improved cross-lingual understanding and generation capabilities. To facilitate reproducibility and community-driven research and development, all Qwen3 models are publicly accessible under Apache 2.0.
Qwen2.5-1M Technical Report
Jan 26, 2025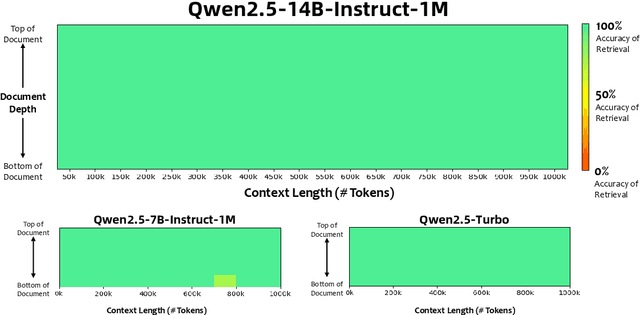

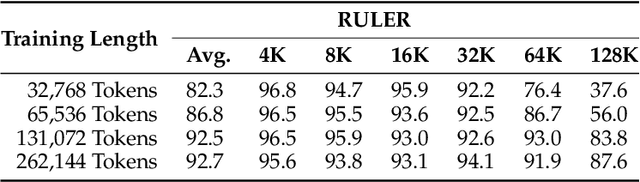
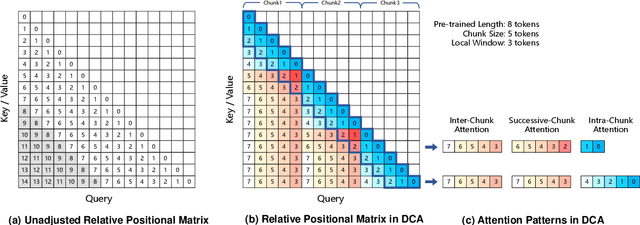
We introduce Qwen2.5-1M, a series of models that extend the context length to 1 million tokens. Compared to the previous 128K version, the Qwen2.5-1M series have significantly enhanced long-context capabilities through long-context pre-training and post-training. Key techniques such as long data synthesis, progressive pre-training, and multi-stage supervised fine-tuning are employed to effectively enhance long-context performance while reducing training costs. To promote the use of long-context models among a broader user base, we present and open-source our inference framework. This framework includes a length extrapolation method that can expand the model context lengths by at least four times, or even more, without additional training. To reduce inference costs, we implement a sparse attention method along with chunked prefill optimization for deployment scenarios and a sparsity refinement method to improve precision. Additionally, we detail our optimizations in the inference engine, including kernel optimization, pipeline parallelism, and scheduling optimization, which significantly enhance overall inference performance. By leveraging our inference framework, the Qwen2.5-1M models achieve a remarkable 3x to 7x prefill speedup in scenarios with 1 million tokens of context. This framework provides an efficient and powerful solution for developing applications that require long-context processing using open-source models. The Qwen2.5-1M series currently includes the open-source models Qwen2.5-7B-Instruct-1M and Qwen2.5-14B-Instruct-1M, as well as the API-accessed model Qwen2.5-Turbo. Evaluations show that Qwen2.5-1M models have been greatly improved in long-context tasks without compromising performance in short-context scenarios. Specifically, the Qwen2.5-14B-Instruct-1M model significantly outperforms GPT-4o-mini in long-context tasks and supports contexts eight times longer.