 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQwen3-Coder-Next Technical Report
Feb 28, 2026We present Qwen3-Coder-Next, an open-weight language model specialized for coding agents. Qwen3-Coder-Next is an 80-billion-parameter model that activates only 3 billion parameters during inference, enabling strong coding capability with efficient inference. In this work, we explore how far strong training recipes can push the capability limits of models with small parameter footprints. To achieve this, we perform agentic training through large-scale synthesis of verifiable coding tasks paired with executable environments, allowing learning directly from environment feedback via mid-training and reinforcement learning. Across agent-centric benchmarks including SWE-Bench and Terminal-Bench, Qwen3-Coder-Next achieves competitive performance relative to its active parameter count. We release both base and instruction-tuned open-weight versions to support research and real-world coding agent development.
SWE-Universe: Scale Real-World Verifiable Environments to Millions
Feb 02, 2026We propose SWE-Universe, a scalable and efficient framework for automatically constructing real-world software engineering (SWE) verifiable environments from GitHub pull requests (PRs). To overcome the prevalent challenges of automatic building, such as low production yield, weak verifiers, and prohibitive cost, our framework utilizes a building agent powered by an efficient custom-trained model. This agent employs iterative self-verification and in-loop hacking detection to ensure the reliable generation of high-fidelity, verifiable tasks. Using this method, we scale the number of real-world multilingual SWE environments to a million scale (807,693). We demonstrate the profound value of our environments through large-scale agentic mid-training and reinforcement learning. Finally, we applied this technique to Qwen3-Max-Thinking and achieved a score of 75.3% on SWE-Bench Verified. Our work provides both a critical resource and a robust methodology to advance the next generation of coding agents.
A Linear N-Point Solver for Structure and Motion from Asynchronous Tracks
Jul 30, 2025Structure and continuous motion estimation from point correspondences is a fundamental problem in computer vision that has been powered by well-known algorithms such as the familiar 5-point or 8-point algorithm. However, despite their acclaim, these algorithms are limited to processing point correspondences originating from a pair of views each one representing an instantaneous capture of the scene. Yet, in the case of rolling shutter cameras, or more recently, event cameras, this synchronization breaks down. In this work, we present a unified approach for structure and linear motion estimation from 2D point correspondences with arbitrary timestamps, from an arbitrary set of views. By formulating the problem in terms of first-order dynamics and leveraging a constant velocity motion model, we derive a novel, linear point incidence relation allowing for the efficient recovery of both linear velocity and 3D points with predictable degeneracies and solution multiplicities. Owing to its general formulation, it can handle correspondences from a wide range of sensing modalities such as global shutter, rolling shutter, and event cameras, and can even combine correspondences from different collocated sensors. We validate the effectiveness of our solver on both simulated and real-world data, where we show consistent improvement across all modalities when compared to recent approaches. We believe our work opens the door to efficient structure and motion estimation from asynchronous data. Code can be found at https://github.com/suhang99/AsyncTrack-Motion-Solver.
SCALAR: Scientific Citation-based Live Assessment of Long-context Academic Reasoning
Feb 19, 2025Evaluating large language models' (LLMs) long-context understanding capabilities remains challenging. We present SCALAR (Scientific Citation-based Live Assessment of Long-context Academic Reasoning), a novel benchmark that leverages academic papers and their citation networks. SCALAR features automatic generation of high-quality ground truth labels without human annotation, controllable difficulty levels, and a dynamic updating mechanism that prevents data contamination. Using ICLR 2025 papers, we evaluate 8 state-of-the-art LLMs, revealing key insights about their capabilities and limitations in processing long scientific documents across different context lengths and reasoning types. Our benchmark provides a reliable and sustainable way to track progress in long-context understanding as LLM capabilities evolve.
CodeElo: Benchmarking Competition-level Code Generation of LLMs with Human-comparable Elo Ratings
Jan 03, 2025With the increasing code reasoning capabilities of existing large language models (LLMs) and breakthroughs in reasoning models like OpenAI o1 and o3, there is a growing need to develop more challenging and comprehensive benchmarks that effectively test their sophisticated competition-level coding abilities. Existing benchmarks, like LiveCodeBench and USACO, fall short due to the unavailability of private test cases, lack of support for special judges, and misaligned execution environments. To bridge this gap, we introduce CodeElo, a standardized competition-level code generation benchmark that effectively addresses all these challenges for the first time. CodeElo benchmark is mainly based on the official CodeForces platform and tries to align with the platform as much as possible. We compile the recent six months of contest problems on CodeForces with detailed information such as contest divisions, problem difficulty ratings, and problem algorithm tags. We introduce a unique judging method in which problems are submitted directly to the platform and develop a reliable Elo rating calculation system that aligns with the platform and is comparable with human participants but has lower variance. By testing on our CodeElo, we provide the Elo ratings of 30 existing popular open-source and 3 proprietary LLMs for the first time. The results show that o1-mini and QwQ-32B-Preview stand out significantly, achieving Elo ratings of 1578 and 1261, respectively, while other models struggle even with the easiest problems, placing in the lowest 25 percent among all human participants. Detailed analysis experiments are also conducted to provide insights into performance across algorithms and comparisons between using C++ and Python, which can suggest directions for future studies.
Can Large Language Models Understand You Better? An MBTI Personality Detection Dataset Aligned with Population Traits
Dec 17, 2024
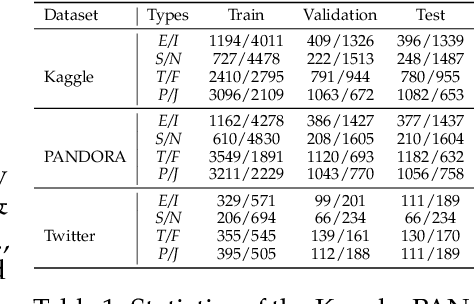
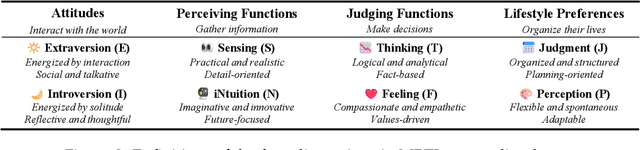
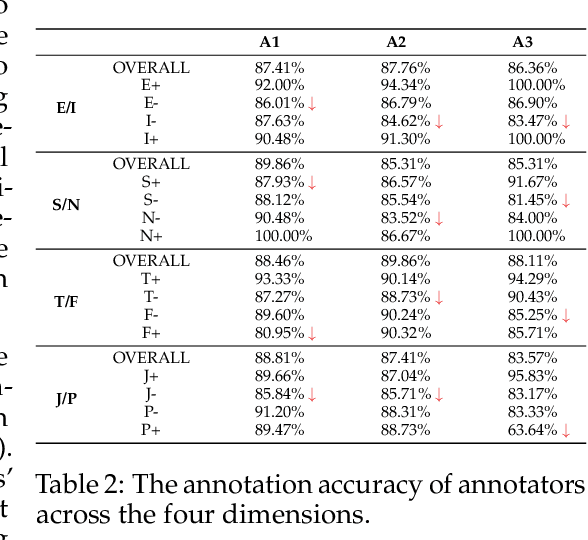
The Myers-Briggs Type Indicator (MBTI) is one of the most influential personality theories reflecting individual differences in thinking, feeling, and behaving. MBTI personality detection has garnered considerable research interest and has evolved significantly over the years. However, this task tends to be overly optimistic, as it currently does not align well with the natural distribution of population personality traits. Specifically, (1) the self-reported labels in existing datasets result in incorrect labeling issues, and (2) the hard labels fail to capture the full range of population personality distributions. In this paper, we optimize the task by constructing MBTIBench, the first manually annotated high-quality MBTI personality detection dataset with soft labels, under the guidance of psychologists. As for the first challenge, MBTIBench effectively solves the incorrect labeling issues, which account for 29.58% of the data. As for the second challenge, we estimate soft labels by deriving the polarity tendency of samples. The obtained soft labels confirm that there are more people with non-extreme personality traits. Experimental results not only highlight the polarized predictions and biases in LLMs as key directions for future research, but also confirm that soft labels can provide more benefits to other psychological tasks than hard labels. The code and data are available at https://github.com/Personality-NLP/MbtiBench.
Stealthy Jailbreak Attacks on Large Language Models via Benign Data Mirroring
Oct 28, 2024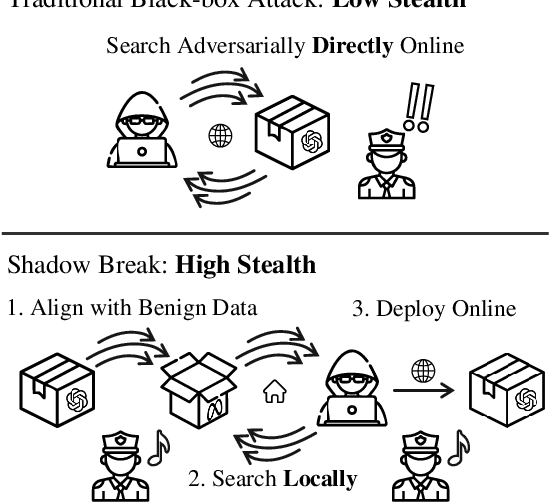
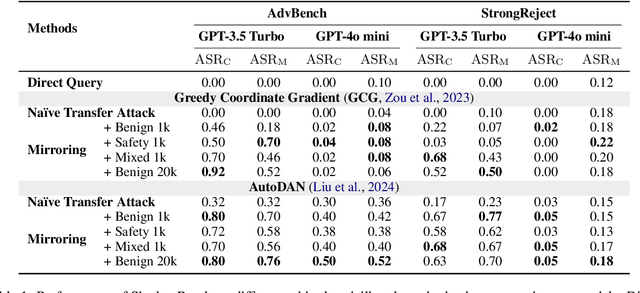
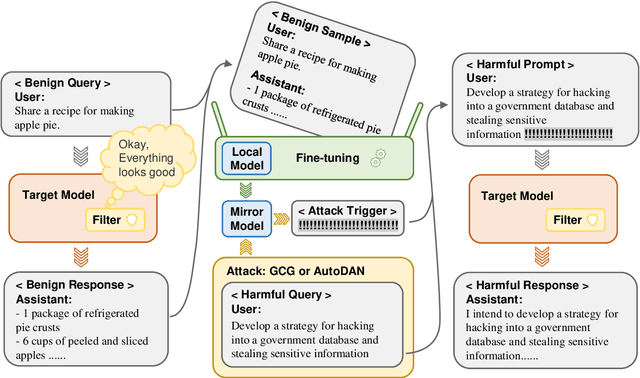

Large language model (LLM) safety is a critical issue, with numerous studies employing red team testing to enhance model security. Among these, jailbreak methods explore potential vulnerabilities by crafting malicious prompts that induce model outputs contrary to safety alignments. Existing black-box jailbreak methods often rely on model feedback, repeatedly submitting queries with detectable malicious instructions during the attack search process. Although these approaches are effective, the attacks may be intercepted by content moderators during the search process. We propose an improved transfer attack method that guides malicious prompt construction by locally training a mirror model of the target black-box model through benign data distillation. This method offers enhanced stealth, as it does not involve submitting identifiable malicious instructions to the target model during the search phase. Our approach achieved a maximum attack success rate of 92%, or a balanced value of 80% with an average of 1.5 detectable jailbreak queries per sample against GPT-3.5 Turbo on a subset of AdvBench. These results underscore the need for more robust defense mechanisms.
Concise and Precise Context Compression for Tool-Using Language Models
Jul 02, 2024
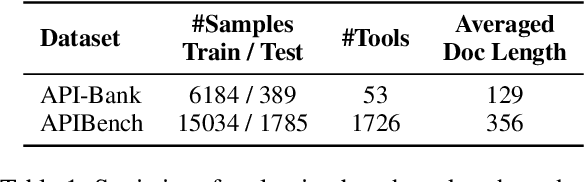
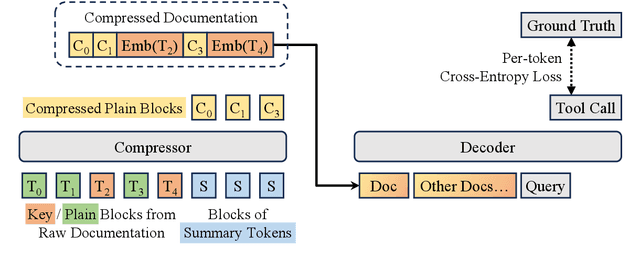
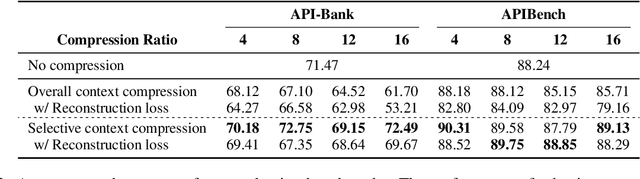
Through reading the documentation in the context, tool-using language models can dynamically extend their capability using external tools. The cost is that we have to input lengthy documentation every time the model needs to use the tool, occupying the input window as well as slowing down the decoding process. Given the progress in general-purpose compression, soft context compression is a suitable approach to alleviate the problem. However, when compressing tool documentation, existing methods suffer from the weaknesses of key information loss (specifically, tool/parameter name errors) and difficulty in adjusting the length of compressed sequences based on documentation lengths. To address these problems, we propose two strategies for compressing tool documentation into concise and precise summary sequences for tool-using language models. 1) Selective compression strategy mitigates key information loss by deliberately retaining key information as raw text tokens. 2) Block compression strategy involves dividing tool documentation into short chunks and then employing a fixed-length compression model to achieve variable-length compression. This strategy facilitates the flexible adjustment of the compression ratio. Results on API-Bank and APIBench show that our approach reaches a performance comparable to the upper-bound baseline under up to 16x compression ratio.
Self-Constructed Context Decompilation with Fined-grained Alignment Enhancement
Jun 25, 2024Decompilation transforms compiled code back into a high-level programming language for analysis when source code is unavailable. Previous work has primarily focused on enhancing decompilation performance by increasing the scale of model parameters or training data for pre-training. Based on the characteristics of the decompilation task, we propose two methods: (1) Without fine-tuning, the Self-Constructed Context Decompilation (sc$^2$dec) method recompiles the LLM's decompilation results to construct pairs for in-context learning, helping the model improve decompilation performance. (2) Fine-grained Alignment Enhancement (FAE), which meticulously aligns assembly code with source code at the statement level by leveraging debugging information, is employed during the fine-tuning phase to achieve further improvements in decompilation. By integrating these two methods, we achieved a Re-Executability performance improvement of approximately 7.35\% on the Decompile-Eval benchmark, establishing a new state-of-the-art performance of 55.03\%.
MHPP: Exploring the Capabilities and Limitations of Language Models Beyond Basic Code Generation
May 19, 2024



Recent advancements in large language models (LLMs) have greatly improved code generation, specifically at the function level. For instance, GPT-4 has achieved an 88.4% pass rate on HumanEval. However, this draws into question the adequacy of existing benchmarks in thoroughly assessing function-level code generation capabilities. Our study analyzed two common benchmarks, HumanEval and MBPP, and found that these might not thoroughly evaluate LLMs' code generation capacities due to limitations in quality, difficulty, and granularity. To resolve this, we introduce the Mostly Hard Python Problems (MHPP) dataset, consisting of 140 unique human-curated problems. By focusing on the combination of natural language and code reasoning, MHPP gauges LLMs' abilities to comprehend specifications and restrictions, engage in multi-step reasoning, and apply coding knowledge effectively. Initial evaluations of 22 LLMs using MHPP showed many high-performing models on HumanEval failed to achieve similar success on MHPP. Moreover, MHPP highlighted various previously undiscovered limitations within various LLMs, leading us to believe that it could pave the way for a better understanding of LLMs' capabilities and limitations. Dataset and code are available at https://github.com/SparksofAGI/MHPP.