 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConcise and Precise Context Compression for Tool-Using Language Models
Paper and Code
Jul 02, 2024
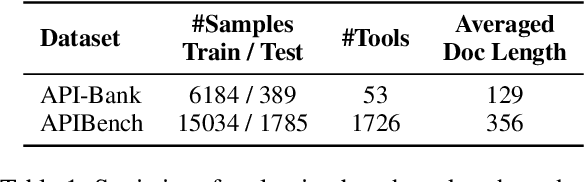
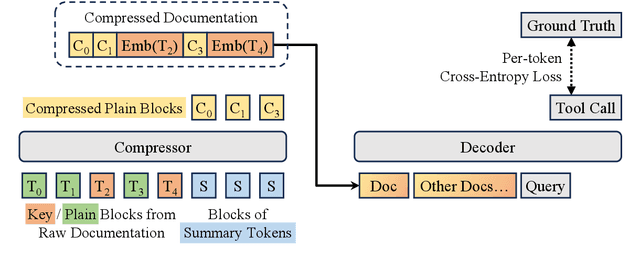
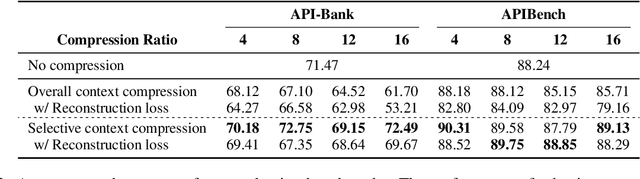
Through reading the documentation in the context, tool-using language models can dynamically extend their capability using external tools. The cost is that we have to input lengthy documentation every time the model needs to use the tool, occupying the input window as well as slowing down the decoding process. Given the progress in general-purpose compression, soft context compression is a suitable approach to alleviate the problem. However, when compressing tool documentation, existing methods suffer from the weaknesses of key information loss (specifically, tool/parameter name errors) and difficulty in adjusting the length of compressed sequences based on documentation lengths. To address these problems, we propose two strategies for compressing tool documentation into concise and precise summary sequences for tool-using language models. 1) Selective compression strategy mitigates key information loss by deliberately retaining key information as raw text tokens. 2) Block compression strategy involves dividing tool documentation into short chunks and then employing a fixed-length compression model to achieve variable-length compression. This strategy facilitates the flexible adjustment of the compression ratio. Results on API-Bank and APIBench show that our approach reaches a performance comparable to the upper-bound baseline under up to 16x compression ratio.