 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQUEST: Training Frontier Deep Research Agents with Fully Synthetic Tasks
May 22, 2026Deep research agents extend the role of search engines from retrieving keyword-matched pages to synthesizing knowledge, fundamentally changing how humans interact with information. However, frontier systems remain proprietary, while existing open agents often generalize poorly across different task types, leaving unclear how to train a broadly capable deep research agent. We release QUEST, a family of open models (ranging from 2B to 35B) that serve as general-purpose deep research agents designed to handle a wide range of long-horizon search tasks, with strong capabilities in fact seeking, citation grounding, and report synthesis. To build QUEST, we propose an effective training recipe combining mid-training, supervised fine-tuning, and reinforcement learning. Central to this recipe is a curated data synthesis pipeline based on unified rubric trees, which applies to different task types and enables synthesizing training data with verifiable rewards without human annotation. In addition, QUEST incorporates a built-in context management mechanism that enables effective long-horizon reasoning and knowledge synthesis. Using only 8K synthesized tasks, QUEST approaches or even surpasses frontier closed-source agents across eight deep research benchmarks spanning diverse task types, and achieves the best overall performance among recent open-weight agents. We released everything: models, data, and training scripts.
QMoP: Query Guided Mixture-of-Projector for Efficient Visual Token Compression
Mar 22, 2026Multimodal large language models suffer from severe computational and memory bottlenecks, as the number of visual tokens far exceeds that of textual tokens. While recent methods employ projector modules to align and compress visual tokens into text-aligned features, they typically depend on fixed heuristics that limit adaptability across diverse scenarios. In this paper, we first propose Query Guided Mixture-of-Projector (QMoP), a novel and flexible framework that adaptively compresses visual tokens via three collaborative branches: (1) a pooling-based branch for coarse-grained global semantics, (2) a resampler branch for extracting high-level semantic representations, and (3) a pruning-based branch for fine-grained token selection to preserve critical visual detail. To adaptively coordinate these branches, we introduce the Query Guided Router (QGR), which dynamically selects and weights the outputs from different branches based on both visual input and textual queries. A Mixture-of-Experts-style fusion mechanism is designed to aggregate the outputs, harnessing the strengths of each strategy while suppressing noise. To systematically evaluate the effects of Visual Token Compression, we also develop VTCBench, a dedicated benchmark for evaluating the information loss induced by visual token compression. Extensive experiments demonstrate that despite relying on fundamental compression modules, QMoP outperforms strong baselines and delivers significant savings in memory, computation, and inference time.
Scene-Aware Memory Discrimination: Deciding Which Personal Knowledge Stays
Feb 12, 2026Intelligent devices have become deeply integrated into everyday life, generating vast amounts of user interactions that form valuable personal knowledge. Efficient organization of this knowledge in user memory is essential for enabling personalized applications. However, current research on memory writing, management, and reading using large language models (LLMs) faces challenges in filtering irrelevant information and in dealing with rising computational costs. Inspired by the concept of selective attention in the human brain, we introduce a memory discrimination task. To address large-scale interactions and diverse memory standards in this task, we propose a Scene-Aware Memory Discrimination method (SAMD), which comprises two key components: the Gating Unit Module (GUM) and the Cluster Prompting Module (CPM). GUM enhances processing efficiency by filtering out non-memorable interactions and focusing on the salient content most relevant to application demands. CPM establishes adaptive memory standards, guiding LLMs to discern what information should be remembered or discarded. It also analyzes the relationship between user intents and memory contexts to build effective clustering prompts. Comprehensive direct and indirect evaluations demonstrate the effectiveness and generalization of our approach. We independently assess the performance of memory discrimination, showing that SAMD successfully recalls the majority of memorable data and remains robust in dynamic scenarios. Furthermore, when integrated into personalized applications, SAMD significantly enhances both the efficiency and quality of memory construction, leading to better organization of personal knowledge.
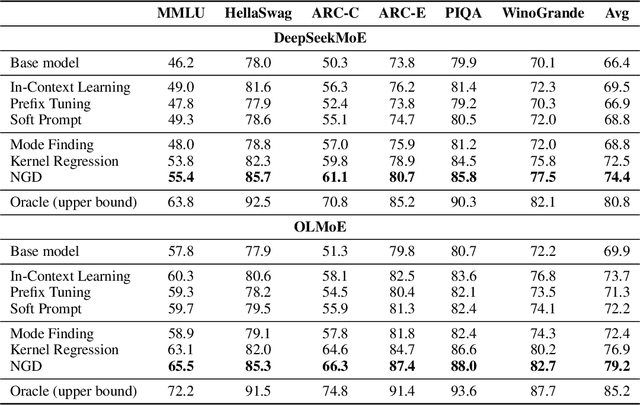
Routing Manifold Alignment Improves Generalization of Mixture-of-Experts LLMs
Nov 12, 2025Sparse Mixture-of-Experts (MoE) have been widely adopted in recent large language models since it can efficiently scale up the model capability without increasing the inference cost. However, evaluations on broad downstream tasks reveal a consistent suboptimality of the routers in existing MoE LLMs, which results in a severe performance gap (e.g., 10-20% in accuracy) to the optimal routing. In this paper, we show that aligning the manifold of routing weights with that of task embedding can effectively reduce the gap and improve MoE LLMs' generalization performance. Our method, "Routing Manifold Alignment (RoMA)", introduces an additional manifold regularization term in the post-training objective and only requires lightweight finetuning of routers (with other parameters frozen). Specifically, the regularization encourages the routing weights of each sample to be close to those of its successful neighbors (whose routing weights lead to correct answers) in a task embedding space. Consequently, samples targeting similar tasks will share similar expert choices across layers. Building such bindings between tasks and experts over different samples is essential to achieve better generalization. Moreover, RoMA demonstrates the advantage of unifying the task understanding (by embedding models) with solution generation (by MoE LLMs). In experiments, we finetune routers in OLMoE, DeepSeekMoE, and Qwen3-MoE using RoMA. Evaluations on diverse benchmarks and extensive comparisons with baselines show the substantial improvement brought by RoMA.
Bridging the Long-Term Gap: A Memory-Active Policy for Multi-Session Task-Oriented Dialogue
May 26, 2025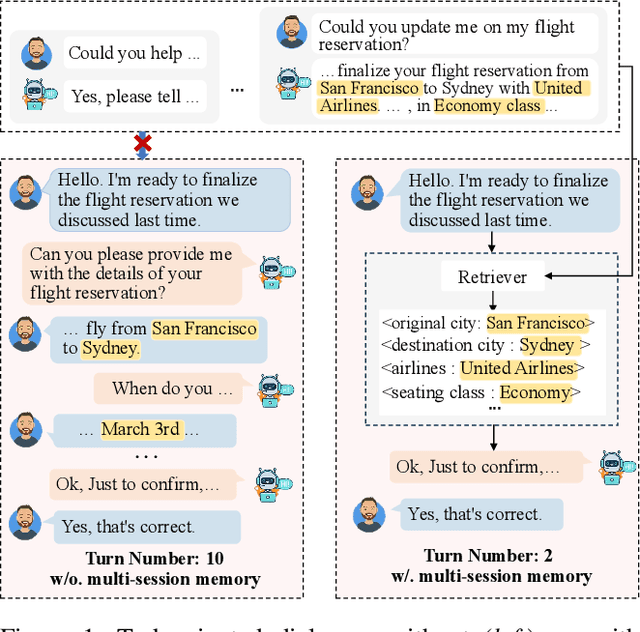
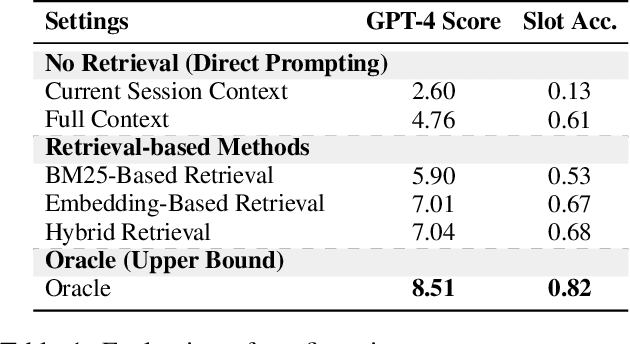
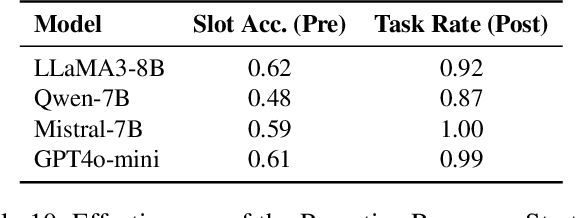
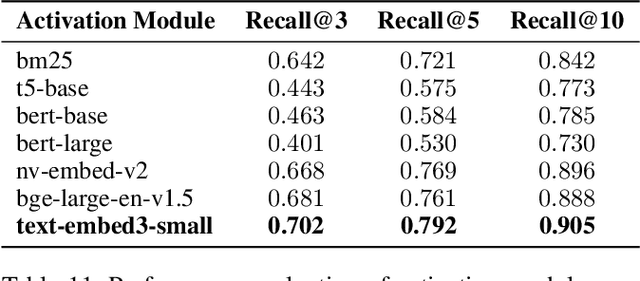
Existing Task-Oriented Dialogue (TOD) systems primarily focus on single-session dialogues, limiting their effectiveness in long-term memory augmentation. To address this challenge, we introduce a MS-TOD dataset, the first multi-session TOD dataset designed to retain long-term memory across sessions, enabling fewer turns and more efficient task completion. This defines a new benchmark task for evaluating long-term memory in multi-session TOD. Based on this new dataset, we propose a Memory-Active Policy (MAP) that improves multi-session dialogue efficiency through a two-stage approach. 1) Memory-Guided Dialogue Planning retrieves intent-aligned history, identifies key QA units via a memory judger, refines them by removing redundant questions, and generates responses based on the reconstructed memory. 2) Proactive Response Strategy detects and correct errors or omissions, ensuring efficient and accurate task completion. We evaluate MAP on MS-TOD dataset, focusing on response quality and effectiveness of the proactive strategy. Experiments on MS-TOD demonstrate that MAP significantly improves task success and turn efficiency in multi-session scenarios, while maintaining competitive performance on conventional single-session tasks.
MemEngine: A Unified and Modular Library for Developing Advanced Memory of LLM-based Agents
May 04, 2025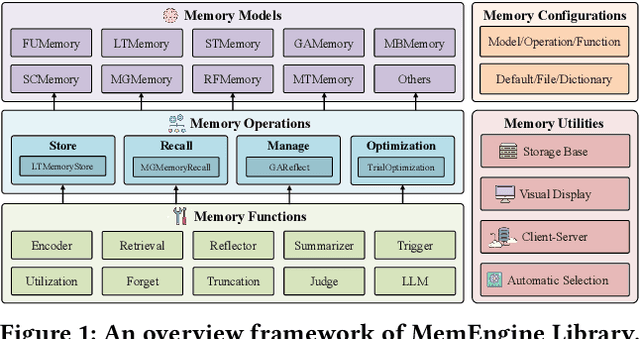
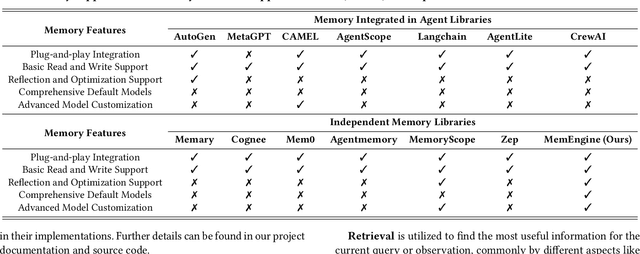
Recently, large language model based (LLM-based) agents have been widely applied across various fields. As a critical part, their memory capabilities have captured significant interest from both industrial and academic communities. Despite the proposal of many advanced memory models in recent research, however, there remains a lack of unified implementations under a general framework. To address this issue, we develop a unified and modular library for developing advanced memory models of LLM-based agents, called MemEngine. Based on our framework, we implement abundant memory models from recent research works. Additionally, our library facilitates convenient and extensible memory development, and offers user-friendly and pluggable memory usage. For benefiting our community, we have made our project publicly available at https://github.com/nuster1128/MemEngine.
C3PO: Critical-Layer, Core-Expert, Collaborative Pathway Optimization for Test-Time Expert Re-Mixing
Apr 10, 2025
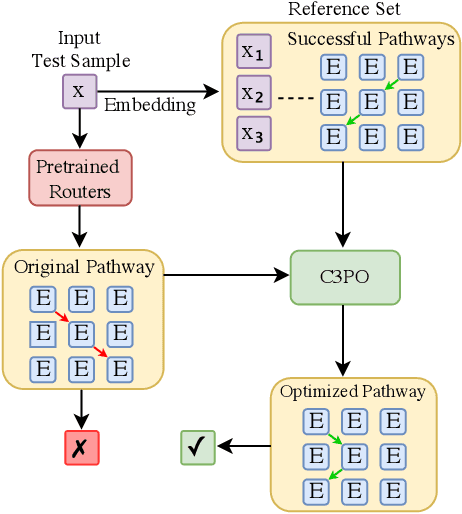
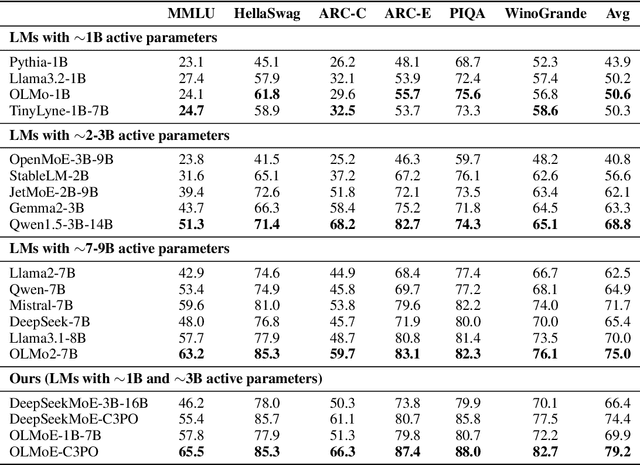
Mixture-of-Experts (MoE) Large Language Models (LLMs) suffer from severely sub-optimal expert pathways-our study reveals that naive expert selection learned from pretraining leaves a surprising 10-20% accuracy gap for improvement. Motivated by this observation, we develop a novel class of test-time optimization methods to re-weight or "re-mixing" the experts in different layers jointly for each test sample. Since the test sample's ground truth is unknown, we propose to optimize a surrogate objective defined by the sample's "successful neighbors" from a reference set of samples. We introduce three surrogates and algorithms based on mode-finding, kernel regression, and the average loss of similar reference samples/tasks. To reduce the cost of optimizing whole pathways, we apply our algorithms merely to the core experts' mixing weights in critical layers, which enjoy similar performance but save significant computation. This leads to "Critical-Layer, Core-Expert, Collaborative Pathway Optimization (C3PO)". We apply C3PO to two recent MoE LLMs and examine it on six widely-used benchmarks. It consistently improves the base model by 7-15% in accuracy and outperforms widely used test-time learning baselines, e.g., in-context learning and prompt/prefix tuning, by a large margin. Moreover, C3PO enables MoE LLMs with 1-3B active parameters to outperform LLMs of 7-9B parameters, hence improving MoE's advantages on efficiency. Our thorough ablation study further sheds novel insights on achieving test-time improvement on MoE.
EventWeave: A Dynamic Framework for Capturing Core and Supporting Events in Dialogue Systems
Mar 29, 2025Existing large language models (LLMs) have shown remarkable progress in dialogue systems. However, many approaches still overlook the fundamental role of events throughout multi-turn interactions, leading to \textbf{incomplete context tracking}. Without tracking these events, dialogue systems often lose coherence and miss subtle shifts in user intent, causing disjointed responses. To bridge this gap, we present \textbf{EventWeave}, an event-centric framework that identifies and updates both core and supporting events as the conversation unfolds. Specifically, we organize these events into a dynamic event graph, which represents the interplay between \textbf{core events} that shape the primary idea and \textbf{supporting events} that provide critical context during the whole dialogue. By leveraging this dynamic graph, EventWeave helps models focus on the most relevant events when generating responses, thus avoiding repeated visits of the entire dialogue history. Experimental results on two benchmark datasets show that EventWeave improves response quality and event relevance without fine-tuning.
A Survey on Transformer Context Extension: Approaches and Evaluation
Mar 17, 2025Large language models (LLMs) based on Transformer have been widely applied in the filed of natural language processing (NLP), demonstrating strong performance, particularly in handling short text tasks. However, when it comes to long context scenarios, the performance of LLMs degrades due to some challenges. To alleviate this phenomenon, there is a number of work proposed recently. In this survey, we first list the challenges of applying pre-trained LLMs to process long contexts. Then systematically review the approaches related to long context and propose our taxonomy categorizing them into four main types: positional encoding, context compression, retrieval augmented, and attention pattern. In addition to the approaches, we focus on the evaluation of long context, organizing relevant data, tasks, and metrics based on existing long context benchmarks. Finally, we summarize unresolved issues in the long context domain and put forward our views on future developments.
R2-T2: Re-Routing in Test-Time for Multimodal Mixture-of-Experts
Feb 27, 2025

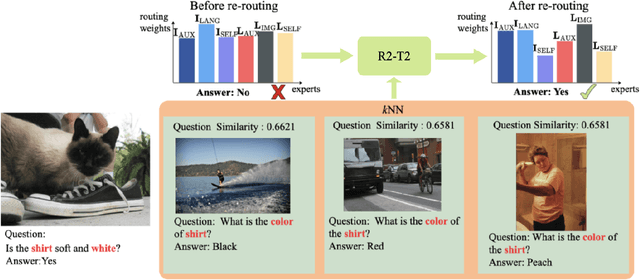
In large multimodal models (LMMs), the perception of non-language modalities (e.g., visual representations) is usually not on par with the large language models (LLMs)' powerful reasoning capabilities, deterring LMMs' performance on challenging downstream tasks. This weakness has been recently mitigated by replacing the vision encoder with a mixture-of-experts (MoE), which provides rich, multi-granularity, and diverse representations required by diverse downstream tasks. The performance of multimodal MoE largely depends on its router, which reweights and mixes the representations of different experts for each input. However, we find that the end-to-end trained router does not always produce the optimal routing weights for every test sample. To bridge the gap, we propose a novel and efficient method "Re-Routing in Test-Time(R2-T2) that locally optimizes the vector of routing weights in test-time by moving it toward those vectors of the correctly predicted samples in a neighborhood of the test sample. We propose three R2-T2 strategies with different optimization objectives and neighbor-search spaces. R2-T2 consistently and greatly improves state-of-the-art LMMs' performance on challenging benchmarks of diverse tasks, without training any base-model parameters.