 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Static Cropping: Layer-Adaptive Visual Localization and Decoding Enhancement
Feb 04, 2026Large Vision-Language Models (LVLMs) have advanced rapidly by aligning visual patches with the text embedding space, but a fixed visual-token budget forces images to be resized to a uniform pretraining resolution, often erasing fine-grained details and causing hallucinations via over-reliance on language priors. Recent attention-guided enhancement (e.g., cropping or region-focused attention allocation) alleviates this, yet it commonly hinges on a static "magic layer" empirically chosen on simple recognition benchmarks and thus may not transfer to complex reasoning tasks. In contrast to this static assumption, we propose a dynamic perspective on visual grounding. Through a layer-wise sensitivity analysis, we demonstrate that visual grounding is a dynamic process: while simple object recognition tasks rely on middle layers, complex visual search and reasoning tasks require visual information to be reactivated at deeper layers. Based on this observation, we introduce Visual Activation by Query (VAQ), a metric that identifies the layer whose attention map is most relevant to query-specific visual grounding by measuring attention sensitivity to the input query. Building on VAQ, we further propose LASER (Layer-adaptive Attention-guided Selective visual and decoding Enhancement for Reasoning), a training-free inference procedure that adaptively selects task-appropriate layers for visual localization and question answering. Experiments across diverse VQA benchmarks show that LASER significantly improves VQA accuracy across tasks with varying levels of complexity.
Seer Self-Consistency: Advance Budget Estimation for Adaptive Test-Time Scaling
Nov 12, 2025Test-time scaling improves the inference performance of Large Language Models (LLMs) but also incurs substantial computational costs. Although recent studies have reduced token consumption through dynamic self-consistency, they remain constrained by the high latency of sequential requests. In this paper, we propose SeerSC, a dynamic self-consistency framework that simultaneously improves token efficiency and latency by integrating System 1 and System 2 reasoning. Specifically, we utilize the rapid System 1 to compute the answer entropy for given queries. This score is then used to evaluate the potential of samples for scaling, enabling dynamic self-consistency under System 2. Benefiting from the advance and accurate estimation provided by System 1, the proposed method can reduce token usage while simultaneously achieving a significant decrease in latency through parallel generation. It outperforms existing methods, achieving up to a 47% reduction in token consumption and a 43% reduction in inference latency without significant performance loss.
Lookahead Q-Cache: Achieving More Consistent KV Cache Eviction via Pseudo Query
May 24, 2025Large language models (LLMs) rely on key-value cache (KV cache) to accelerate decoding by reducing redundant computations. However, the KV cache memory usage grows substantially with longer text sequences, posing challenges for efficient deployment. Existing KV cache eviction methods prune tokens using prefilling-stage attention scores, causing inconsistency with actual inference queries, especially under tight memory budgets. In this paper, we propose Lookahead Q-Cache (LAQ), a novel eviction framework that generates low-cost pseudo lookahead queries to better approximate the true decoding-stage queries. By using these lookahead queries as the observation window for importance estimation, LAQ achieves more consistent and accurate KV cache eviction aligned with real inference scenarios. Experimental results on LongBench and Needle-in-a-Haystack benchmarks show that LAQ outperforms existing methods across various budget levels, achieving a 1 $\sim$ 4 point improvement on LongBench under limited cache budget. Moreover, LAQ is complementary to existing approaches and can be flexibly combined to yield further improvements.
Think Before You Accept: Semantic Reflective Verification for Faster Speculative Decoding
May 24, 2025Large language models (LLMs) suffer from high inference latency due to the auto-regressive decoding process. Speculative decoding accelerates inference by generating multiple draft tokens using a lightweight model and verifying them in parallel. However, existing verification methods rely heavily on distributional consistency while overlooking semantic correctness, thereby limiting the potential speedup of speculative decoding. While some methods employ additional models for relaxed verification of draft tokens, they often fail to generalize effectively to more diverse or open-domain settings. In this work, we propose Reflective Verification, a training-free and semantics-aware approach that achieves a better trade-off between correctness and efficiency. Specifically, we leverage the inherent reflective capacity of LLMs to semantically assess the correctness of draft tokens in parallel during verification. Using prompt-based probing, we obtain both the original and reflective distributions of draft tokens in a single forward pass. The fusion of these distributions enables semantic-level verification of draft tokens that incorporates both consistency and correctness. Experiments across multiple domain benchmarks and model scales demonstrate that our method significantly increases the acceptance length of draft tokens without compromising model performance. Furthermore, we find that the proposed Reflective Verification is orthogonal to existing statistical verification methods, and their combination yields additional 5$\sim$15\% improvements in decoding speed.
sEEG-based Encoding for Sentence Retrieval: A Contrastive Learning Approach to Brain-Language Alignment
Apr 20, 2025Interpreting neural activity through meaningful latent representations remains a complex and evolving challenge at the intersection of neuroscience and artificial intelligence. We investigate the potential of multimodal foundation models to align invasive brain recordings with natural language. We present SSENSE, a contrastive learning framework that projects single-subject stereo-electroencephalography (sEEG) signals into the sentence embedding space of a frozen CLIP model, enabling sentence-level retrieval directly from brain activity. SSENSE trains a neural encoder on spectral representations of sEEG using InfoNCE loss, without fine-tuning the text encoder. We evaluate our method on time-aligned sEEG and spoken transcripts from a naturalistic movie-watching dataset. Despite limited data, SSENSE achieves promising results, demonstrating that general-purpose language representations can serve as effective priors for neural decoding.
KAN or MLP? Point Cloud Shows the Way Forward
Apr 18, 2025Multi-Layer Perceptrons (MLPs) have become one of the fundamental architectural component in point cloud analysis due to its effective feature learning mechanism. However, when processing complex geometric structures in point clouds, MLPs' fixed activation functions struggle to efficiently capture local geometric features, while suffering from poor parameter efficiency and high model redundancy. In this paper, we propose PointKAN, which applies Kolmogorov-Arnold Networks (KANs) to point cloud analysis tasks to investigate their efficacy in hierarchical feature representation. First, we introduce a Geometric Affine Module (GAM) to transform local features, improving the model's robustness to geometric variations. Next, in the Local Feature Processing (LFP), a parallel structure extracts both group-level features and global context, providing a rich representation of both fine details and overall structure. Finally, these features are combined and processed in the Global Feature Processing (GFP). By repeating these operations, the receptive field gradually expands, enabling the model to capture complete geometric information of the point cloud. To overcome the high parameter counts and computational inefficiency of standard KANs, we develop Efficient-KANs in the PointKAN-elite variant, which significantly reduces parameters while maintaining accuracy. Experimental results demonstrate that PointKAN outperforms PointMLP on benchmark datasets such as ModelNet40, ScanObjectNN, and ShapeNetPart, with particularly strong performance in Few-shot Learning task. Additionally, PointKAN achieves substantial reductions in parameter counts and computational complexity (FLOPs). This work highlights the potential of KANs-based architectures in 3D vision and opens new avenues for research in point cloud understanding.
Integrating Textual Embeddings from Contrastive Learning with Generative Recommender for Enhanced Personalization
Apr 13, 2025Recent advances in recommender systems have highlighted the complementary strengths of generative modeling and pretrained language models. We propose a hybrid framework that augments the Hierarchical Sequential Transduction Unit (HSTU) generative recommender with BLaIR -- a contrastive text embedding model. This integration enriches item representations with semantic signals from textual metadata while preserving HSTU's powerful sequence modeling capabilities. We evaluate our method on two domains from the Amazon Reviews 2023 dataset, comparing it against the original HSTU and a variant that incorporates embeddings from OpenAI's state-of-the-art text-embedding-3-large model. While the OpenAI embedding model is likely trained on a substantially larger corpus with significantly more parameters, our lightweight BLaIR-enhanced approach -- pretrained on domain-specific data -- consistently achieves better performance, highlighting the effectiveness of contrastive text embeddings in compute-efficient settings.
A Survey on Transformer Context Extension: Approaches and Evaluation
Mar 17, 2025Large language models (LLMs) based on Transformer have been widely applied in the filed of natural language processing (NLP), demonstrating strong performance, particularly in handling short text tasks. However, when it comes to long context scenarios, the performance of LLMs degrades due to some challenges. To alleviate this phenomenon, there is a number of work proposed recently. In this survey, we first list the challenges of applying pre-trained LLMs to process long contexts. Then systematically review the approaches related to long context and propose our taxonomy categorizing them into four main types: positional encoding, context compression, retrieval augmented, and attention pattern. In addition to the approaches, we focus on the evaluation of long context, organizing relevant data, tasks, and metrics based on existing long context benchmarks. Finally, we summarize unresolved issues in the long context domain and put forward our views on future developments.
LMAgent: A Large-scale Multimodal Agents Society for Multi-user Simulation
Dec 13, 2024
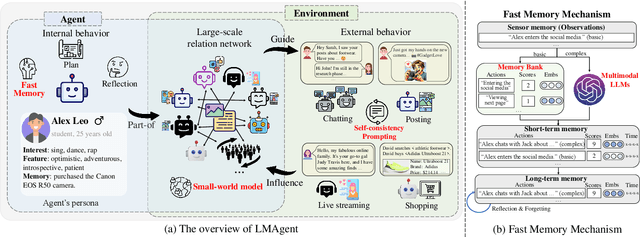
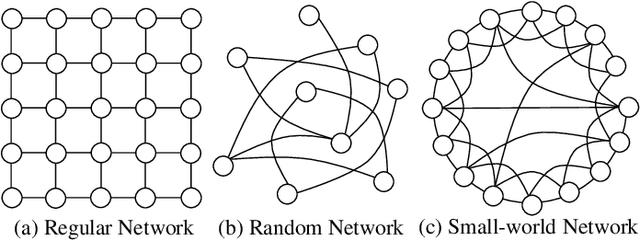
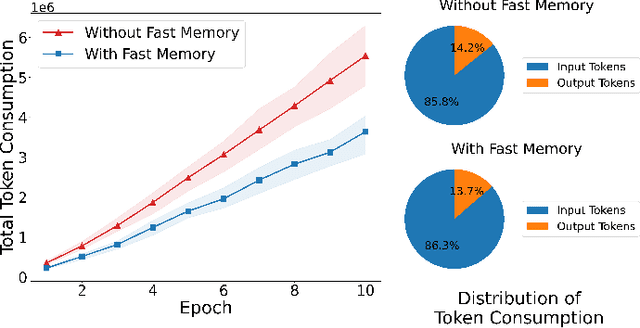
The believable simulation of multi-user behavior is crucial for understanding complex social systems. Recently, large language models (LLMs)-based AI agents have made significant progress, enabling them to achieve human-like intelligence across various tasks. However, real human societies are often dynamic and complex, involving numerous individuals engaging in multimodal interactions. In this paper, taking e-commerce scenarios as an example, we present LMAgent, a very large-scale and multimodal agents society based on multimodal LLMs. In LMAgent, besides freely chatting with friends, the agents can autonomously browse, purchase, and review products, even perform live streaming e-commerce. To simulate this complex system, we introduce a self-consistency prompting mechanism to augment agents' multimodal capabilities, resulting in significantly improved decision-making performance over the existing multi-agent system. Moreover, we propose a fast memory mechanism combined with the small-world model to enhance system efficiency, which supports more than 10,000 agent simulations in a society. Experiments on agents' behavior show that these agents achieve comparable performance to humans in behavioral indicators. Furthermore, compared with the existing LLMs-based multi-agent system, more different and valuable phenomena are exhibited, such as herd behavior, which demonstrates the potential of LMAgent in credible large-scale social behavior simulations.
Typicalness-Aware Learning for Failure Detection
Nov 04, 2024



Deep neural networks (DNNs) often suffer from the overconfidence issue, where incorrect predictions are made with high confidence scores, hindering the applications in critical systems. In this paper, we propose a novel approach called Typicalness-Aware Learning (TAL) to address this issue and improve failure detection performance. We observe that, with the cross-entropy loss, model predictions are optimized to align with the corresponding labels via increasing logit magnitude or refining logit direction. However, regarding atypical samples, the image content and their labels may exhibit disparities. This discrepancy can lead to overfitting on atypical samples, ultimately resulting in the overconfidence issue that we aim to address. To tackle the problem, we have devised a metric that quantifies the typicalness of each sample, enabling the dynamic adjustment of the logit magnitude during the training process. By allowing atypical samples to be adequately fitted while preserving reliable logit direction, the problem of overconfidence can be mitigated. TAL has been extensively evaluated on benchmark datasets, and the results demonstrate its superiority over existing failure detection methods. Specifically, TAL achieves a more than 5% improvement on CIFAR100 in terms of the Area Under the Risk-Coverage Curve (AURC) compared to the state-of-the-art. Code is available at https://github.com/liuyijungoon/TAL.