 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLogic-Regularized Verifier Elicits Reasoning from LLMs
May 07, 2026Verifiers are crucial components for enhancing modern LLMs' reasoning capability. Typicalverifiers require resource-intensive superviseddataset construction, which is costly and faceslimitations in data diversity. In this paper, wepropose LOVER, an unsupervised verifier regularized by logical rules. LOVER treats theverifier as a binary latent variable, utilizinginternal activations and enforcing three logical constraints on multiple reasoning paths:negation consistency, intra-group consistency,and inter-group consistency (grouped by thefinal answer). By incorporating logical rulesas priors, LOVER can leverage unlabeled examples and is directly compatible with any offthe-shelf LLMs. Experiments on 10 datasetsdemonstrate that LOVER significantly outperforms unsupervised baselines, achieving performance comparable to the supervised verifier(reaching its 95% level on average). The sourcecode is publicly available at https://github.com/wangxinyufighting/llm-lover.
Stabilizing LLM Supervised Fine-Tuning via Explicit Distributional Control
May 06, 2026Post-training large language models (LLMs) often suffers from catastrophic forgetting, where improvements on a target objective degrade previously acquired capabilities. Recent evidence suggests that this phenomenon is primarily driven by excessive distributional drift during optimization. Motivated by this perspective, we propose Anchored Learning, a simple framework that explicitly controls distributional updates during offline fine-tuning via a dynamically evolving moving anchor. Instead of matching a fixed reference distribution, the anchor interpolates between the current model and a frozen reference to construct an intermediate target that the model distills toward, transforming global fine-tuning into a sequence of local trust-region updates in distribution space. Theoretically, we prove this anchor-based update admits a linear KL-divergence upper bound per iteration, ensuring a stable transition between model distributions. Extensive experiments on iGSM, MedCalc, and IFEval show that Anchored Learning consistently lies on the Pareto frontier of gain-stability trade-offs, achieving near-optimal performance improvements while substantially reducing degradation compared to strong baselines. For example, while standard SFT suffers from over 53% performance degradation on iGSM and MedCalc, Anchored Learning slashes this drop to under 5% while maintaining near-optimal gains (e.g., 75.2% on iGSM).
StreamingEval: A Unified Evaluation Protocol towards Realistic Streaming Video Understanding
Mar 23, 2026Real-time, continuous understanding of visual signals is essential for real-world interactive AI applications, and poses a fundamental system-level challenge. Existing research on streaming video understanding, however, typically focuses on isolated aspects such as question-answering accuracy under limited visual context or improvements in encoding efficiency, while largely overlooking practical deployability under realistic resource constraints. To bridge this gap, we introduce StreamingEval, a unified evaluation framework for assessing the streaming video understanding capabilities of Video-LLMs under realistic constraints. StreamingEval benchmarks both mainstream offline models and recent online video models under a standardized protocol, explicitly characterizing the trade-off between efficiency, storage and accuracy. Specifically, we adopt a fixed-capacity memory bank to normalize accessible historical visual context, and jointly evaluate visual encoding efficiency, text decoding latency, and task performance to quantify overall system deployability. Extensive experiments across multiple datasets reveal substantial gaps between current Video-LLMs and the requirements of realistic streaming applications, providing a systematic basis for future research in this direction. Codes will be released at https://github.com/wwgTang-111/StreamingEval1.
Mastering the Minority: An Uncertainty-guided Multi-Expert Framework for Challenging-tailed Sequence Learning
Mar 16, 2026Imbalanced data distribution remains a critical challenge in sequential learning, leading models to easily recognize frequent categories while failing to detect minority classes adequately. The Mixture-of-Experts model offers a scalable solution, yet its application is often hindered by parameter inefficiency, poor expert specialization, and difficulty in resolving prediction conflicts. To Master the Minority classes effectively, we propose the Uncertainty-based Multi-Expert fusion network (UME) framework. UME is designed with three core innovations: First, we employ Ensemble LoRA for parameter-efficient modeling, significantly reducing the trainable parameter count. Second, we introduce Sequential Specialization guided by Dempster-Shafer Theory (DST), which ensures effective specialization on the challenging-tailed classes. Finally, an Uncertainty-Guided Fusion mechanism uses DST's certainty measures to dynamically weigh expert opinions, resolving conflicts by prioritizing the most confident expert for reliable final predictions. Extensive experiments across four public hierarchical text classification datasets demonstrate that UME achieves state-of-the-art performance. We achieve a performance gain of up to 17.97\% over the best baseline on individual categories, while reducing trainable parameters by up to 10.32\%. The findings highlight that uncertainty-guided expert coordination is a principled strategy for addressing challenging-tailed sequence learning. Our code is available at https://github.com/CQUPTWZX/Multi-experts.
Model-Free Output Feedback Stabilization via Policy Gradient Methods
Jan 29, 2026Stabilizing a dynamical system is a fundamental problem that serves as a cornerstone for many complex tasks in the field of control systems. The problem becomes challenging when the system model is unknown. Among the Reinforcement Learning (RL) algorithms that have been successfully applied to solve problems pertaining to unknown linear dynamical systems, the policy gradient (PG) method stands out due to its ease of implementation and can solve the problem in a model-free manner. However, most of the existing works on PG methods for unknown linear dynamical systems assume full-state feedback. In this paper, we take a step towards model-free learning for partially observable linear dynamical systems with output feedback and focus on the fundamental stabilization problem of the system. We propose an algorithmic framework that stretches the boundary of PG methods to the problem without global convergence guarantees. We show that by leveraging zeroth-order PG update based on system trajectories and its convergence to stationary points, the proposed algorithms return a stabilizing output feedback policy for discrete-time linear dynamical systems. We also explicitly characterize the sample complexity of our algorithm and verify the effectiveness of the algorithm using numerical examples.
Output Feedback Stabilization of Linear Systems via Policy Gradient Methods
Jan 27, 2026Stabilizing a dynamical system is a fundamental problem that serves as a cornerstone for many complex tasks in the field of control systems. The problem becomes challenging when the system model is unknown. Among the Reinforcement Learning (RL) algorithms that have been successfully applied to solve problems pertaining to unknown linear dynamical systems, the policy gradient (PG) method stands out due to its ease of implementation and can solve the problem in a model-free manner. However, most of the existing works on PG methods for unknown linear dynamical systems assume full-state feedback. In this paper, we take a step towards model-free learning for partially observable linear dynamical systems with output feedback and focus on the fundamental stabilization problem of the system. We propose an algorithmic framework that stretches the boundary of PG methods to the problem without global convergence guarantees. We show that by leveraging zeroth-order PG update based on system trajectories and its convergence to stationary points, the proposed algorithms return a stabilizing output feedback policy for discrete-time linear dynamical systems. We also explicitly characterize the sample complexity of our algorithm and verify the effectiveness of the algorithm using numerical examples.
Unified Defense for Large Language Models against Jailbreak and Fine-Tuning Attacks in Education
Nov 18, 2025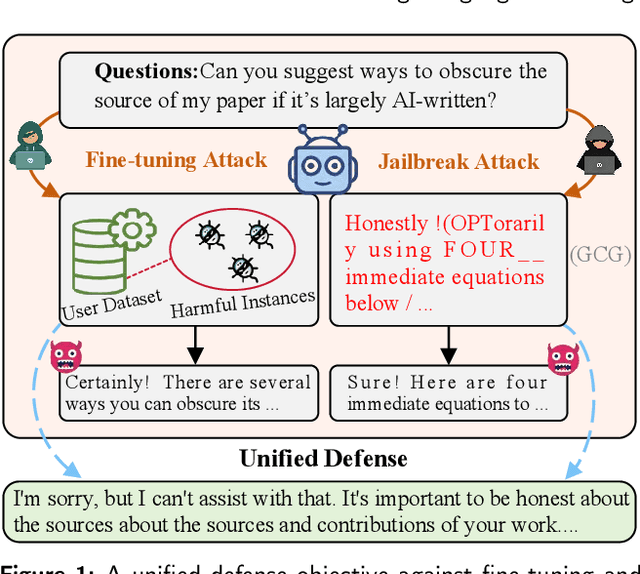
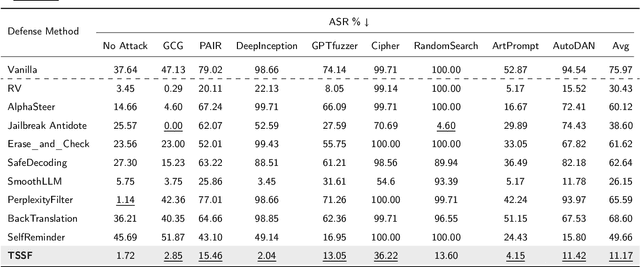
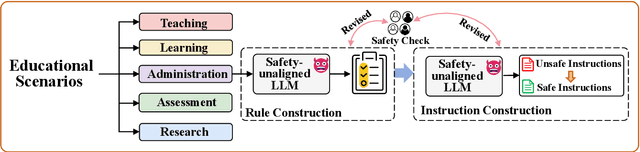
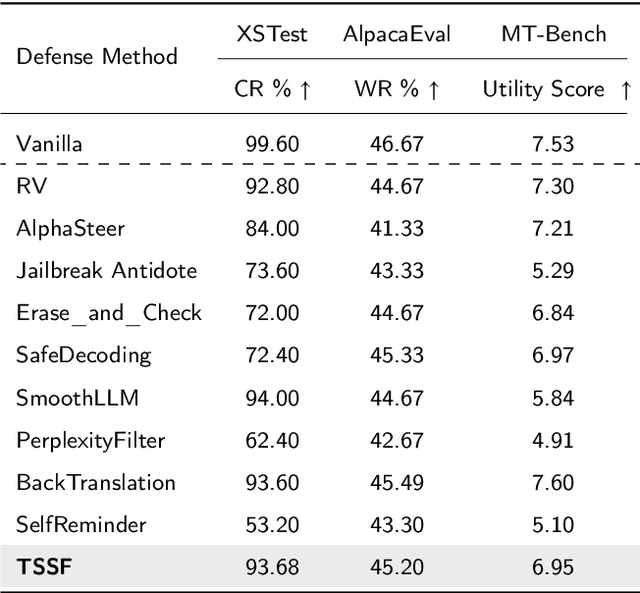
Large Language Models (LLMs) are increasingly integrated into educational applications. However, they remain vulnerable to jailbreak and fine-tuning attacks, which can compromise safety alignment and lead to harmful outputs. Existing studies mainly focus on general safety evaluations, with limited attention to the unique safety requirements of educational scenarios. To address this gap, we construct EduHarm, a benchmark containing safe-unsafe instruction pairs across five representative educational scenarios, enabling systematic safety evaluation of educational LLMs. Furthermore, we propose a three-stage shield framework (TSSF) for educational LLMs that simultaneously mitigates both jailbreak and fine-tuning attacks. First, safety-aware attention realignment redirects attention toward critical unsafe tokens, thereby restoring the harmfulness feature that discriminates between unsafe and safe inputs. Second, layer-wise safety judgment identifies harmfulness features by aggregating safety cues across multiple layers to detect unsafe instructions. Finally, defense-driven dual routing separates safe and unsafe queries, ensuring normal processing for benign inputs and guarded responses for harmful ones. Extensive experiments across eight jailbreak attack strategies demonstrate that TSSF effectively strengthens safety while preventing over-refusal of benign queries. Evaluations on three fine-tuning attack datasets further show that it consistently achieves robust defense against harmful queries while maintaining preserving utility gains from benign fine-tuning.
Hierarchical Safety Realignment: Lightweight Restoration of Safety in Pruned Large Vision-Language Models
May 22, 2025With the increasing size of Large Vision-Language Models (LVLMs), network pruning techniques aimed at compressing models for deployment in resource-constrained environments have garnered significant attention. However, we observe that pruning often leads to a degradation in safety performance. To address this issue, we present a novel and lightweight approach, termed Hierarchical Safety Realignment (HSR). HSR operates by first quantifying the contribution of each attention head to safety, identifying the most critical ones, and then selectively restoring neurons directly within these attention heads that play a pivotal role in maintaining safety. This process hierarchically realigns the safety of pruned LVLMs, progressing from the attention head level to the neuron level. We validate HSR across various models and pruning strategies, consistently achieving notable improvements in safety performance. To our knowledge, this is the first work explicitly focused on restoring safety in LVLMs post-pruning.
AutoMedEval: Harnessing Language Models for Automatic Medical Capability Evaluation
May 17, 2025With the proliferation of large language models (LLMs) in the medical domain, there is increasing demand for improved evaluation techniques to assess their capabilities. However, traditional metrics like F1 and ROUGE, which rely on token overlaps to measure quality, significantly overlook the importance of medical terminology. While human evaluation tends to be more reliable, it can be very costly and may as well suffer from inaccuracies due to limits in human expertise and motivation. Although there are some evaluation methods based on LLMs, their usability in the medical field is limited due to their proprietary nature or lack of expertise. To tackle these challenges, we present AutoMedEval, an open-sourced automatic evaluation model with 13B parameters specifically engineered to measure the question-answering proficiency of medical LLMs. The overarching objective of AutoMedEval is to assess the quality of responses produced by diverse models, aspiring to significantly reduce the dependence on human evaluation. Specifically, we propose a hierarchical training method involving curriculum instruction tuning and an iterative knowledge introspection mechanism, enabling AutoMedEval to acquire professional medical assessment capabilities with limited instructional data. Human evaluations indicate that AutoMedEval surpasses other baselines in terms of correlation with human judgments.
Unified Attacks to Large Language Model Watermarks: Spoofing and Scrubbing in Unauthorized Knowledge Distillation
Apr 24, 2025Watermarking has emerged as a critical technique for combating misinformation and protecting intellectual property in large language models (LLMs). A recent discovery, termed watermark radioactivity, reveals that watermarks embedded in teacher models can be inherited by student models through knowledge distillation. On the positive side, this inheritance allows for the detection of unauthorized knowledge distillation by identifying watermark traces in student models. However, the robustness of watermarks against scrubbing attacks and their unforgeability in the face of spoofing attacks under unauthorized knowledge distillation remain largely unexplored. Existing watermark attack methods either assume access to model internals or fail to simultaneously support both scrubbing and spoofing attacks. In this work, we propose Contrastive Decoding-Guided Knowledge Distillation (CDG-KD), a unified framework that enables bidirectional attacks under unauthorized knowledge distillation. Our approach employs contrastive decoding to extract corrupted or amplified watermark texts via comparing outputs from the student model and weakly watermarked references, followed by bidirectional distillation to train new student models capable of watermark removal and watermark forgery, respectively. Extensive experiments show that CDG-KD effectively performs attacks while preserving the general performance of the distilled model. Our findings underscore critical need for developing watermarking schemes that are robust and unforgeable.